ntity Structure Within and Throughout: Modeling Mention Dependencies for Document-Level Relation Extraction
会议:AAAI
年份:2021
作者:Benfeng Xu, Quan Wang etc.
机构:School of Information Science and Technology, University of Science and Technology of China, Hefei, China
数据集:
- DocRED
- CRD、GDA:生物医学领域
贡献:
- 将文档级文本中显示的各种提及依赖关系总结成一个统一的框架。通过在编码网络内部和整个编码网络中显式地合并这种结构,能够同时、交互式地执行上下文推理和结构推理,从而大大提高了关系提取任务的性能。
- 提出SSAN(Structured Self-Attention Network),通过结构性的指导,扩展标准的自注意力机制。
Approach
实体结构
文档级关系抽取中的实体结构,两种结构都可以表示为True和False:
- 共现(co-occurence)结构:一个句子中存在多个实体提及,表示句子内部的实体依赖关系。
- 协同(coreference)结构:多个实体提及指向同一实体,指向同一实体时需要被同时发现和推理。
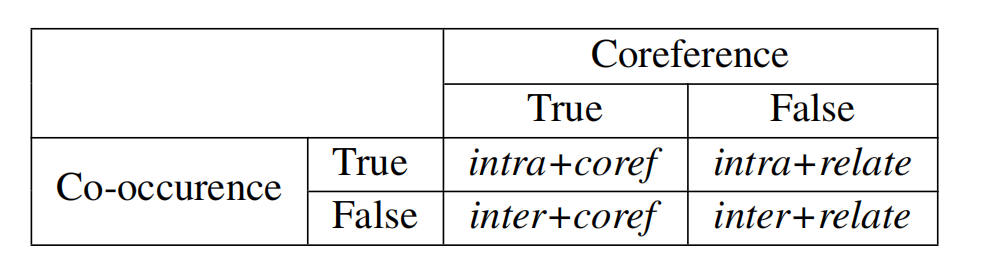
除了实体提及之间的依赖关系外,我们还进一步考虑了实体提及与其句子内非实体(None-Entity,NE)词之间的另一种依赖关系,把它表示为intraNE。对于其他句子间非实体词,我们假设不存在关键依赖,并将其归类为NA。
综上,实体结构为:intra+coref,intra+relate,inter+coref,inter+relate,intraNE,NA
模型
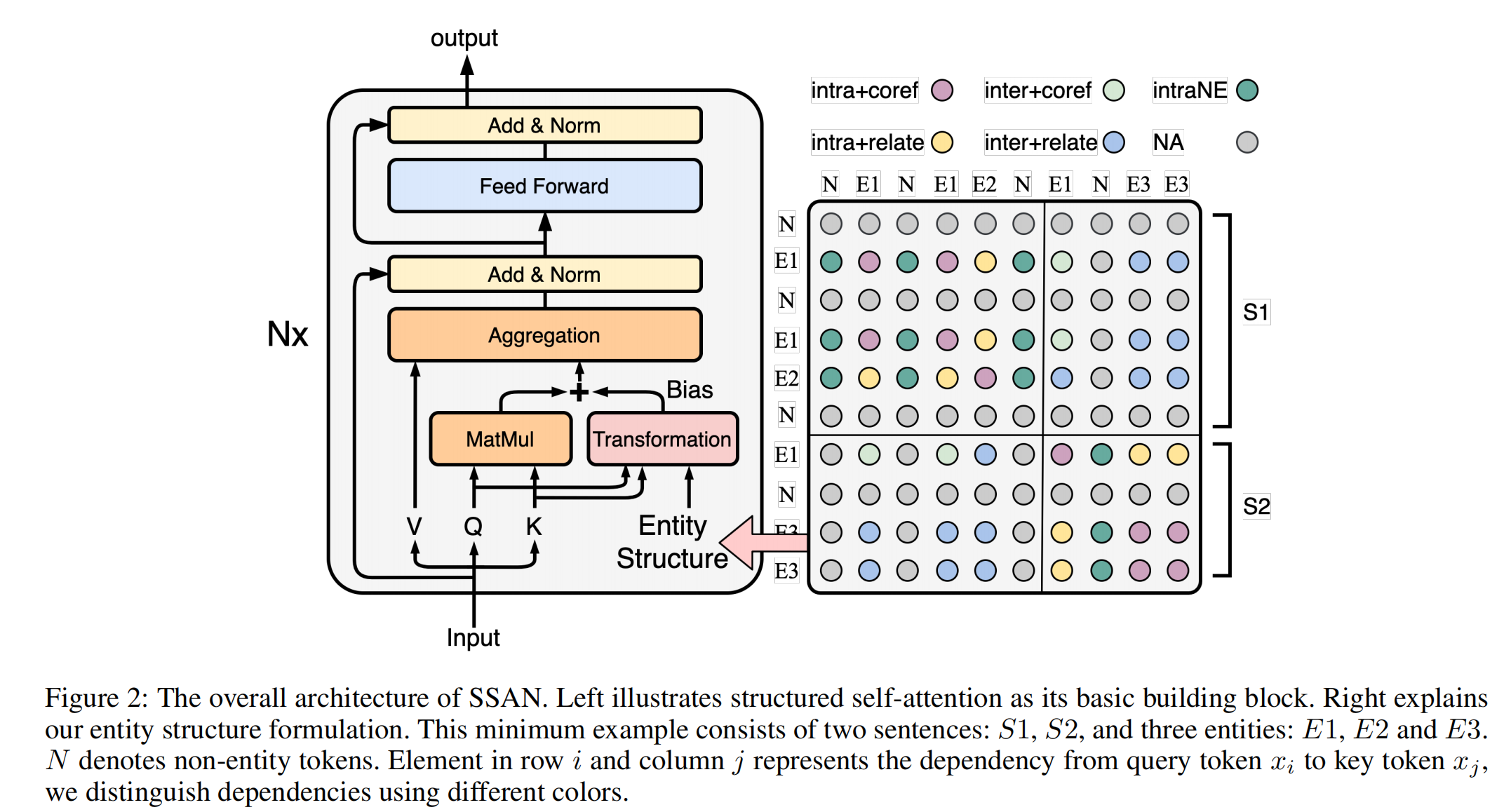
文章使用了引入结构性信息的Transformer结构,在计算注意力权重时引入结构信息,其中 s_i_j为上图中矩阵中的实体结构类型。
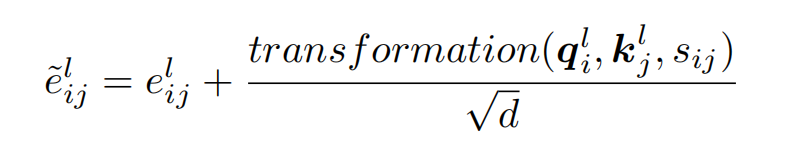
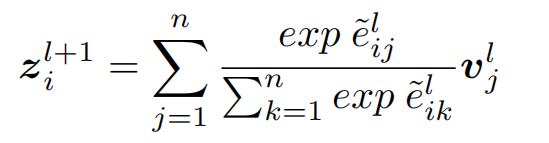
其中,转换模块(transformation)有两种方案,双仿射方案和线性分解方案:
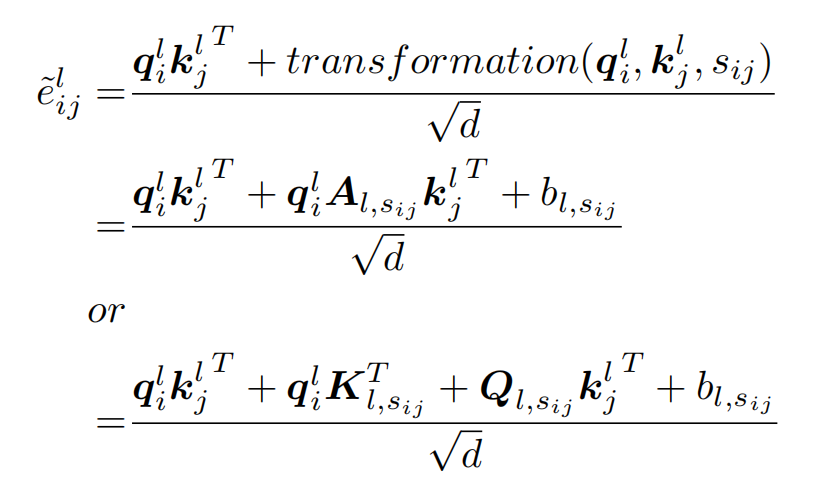
在关系分类时,使用指向同一个实体的多个实体提及的平均池化作为实体表示,最后进行多分类。损失使用普通的交叉熵损失。
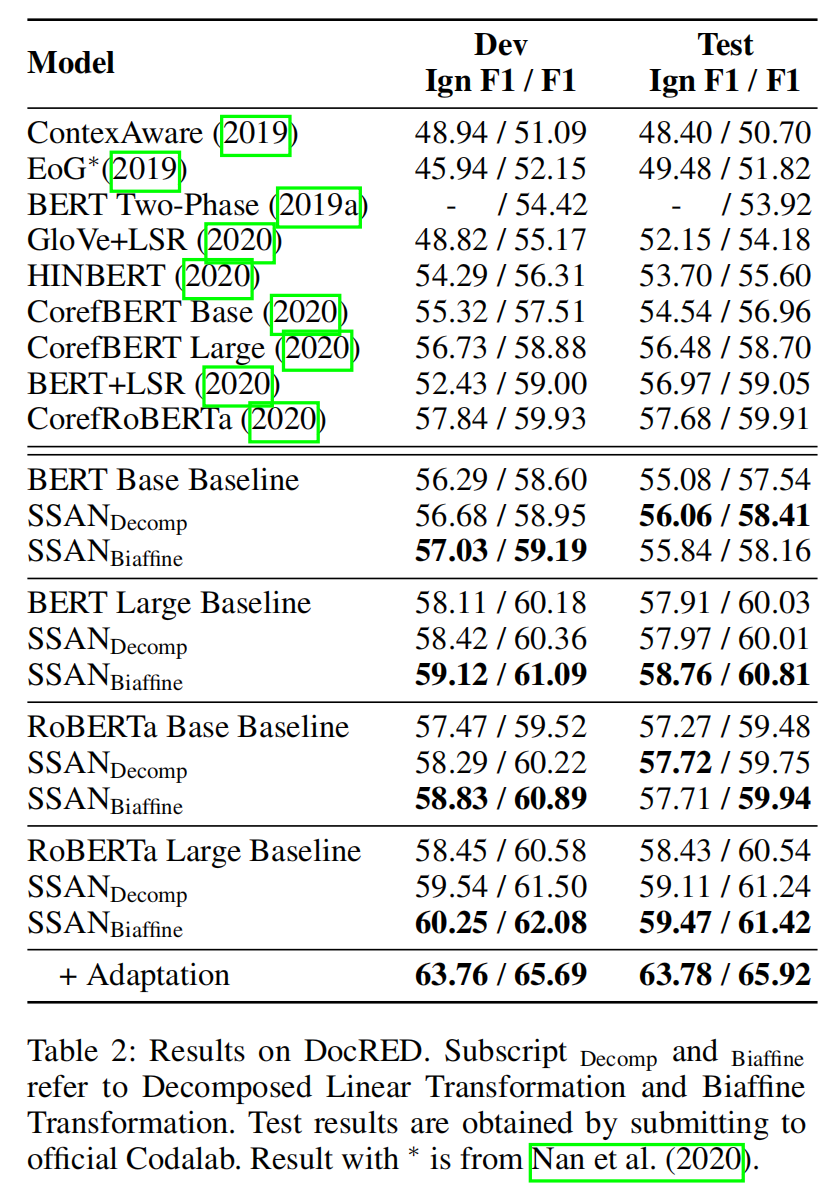
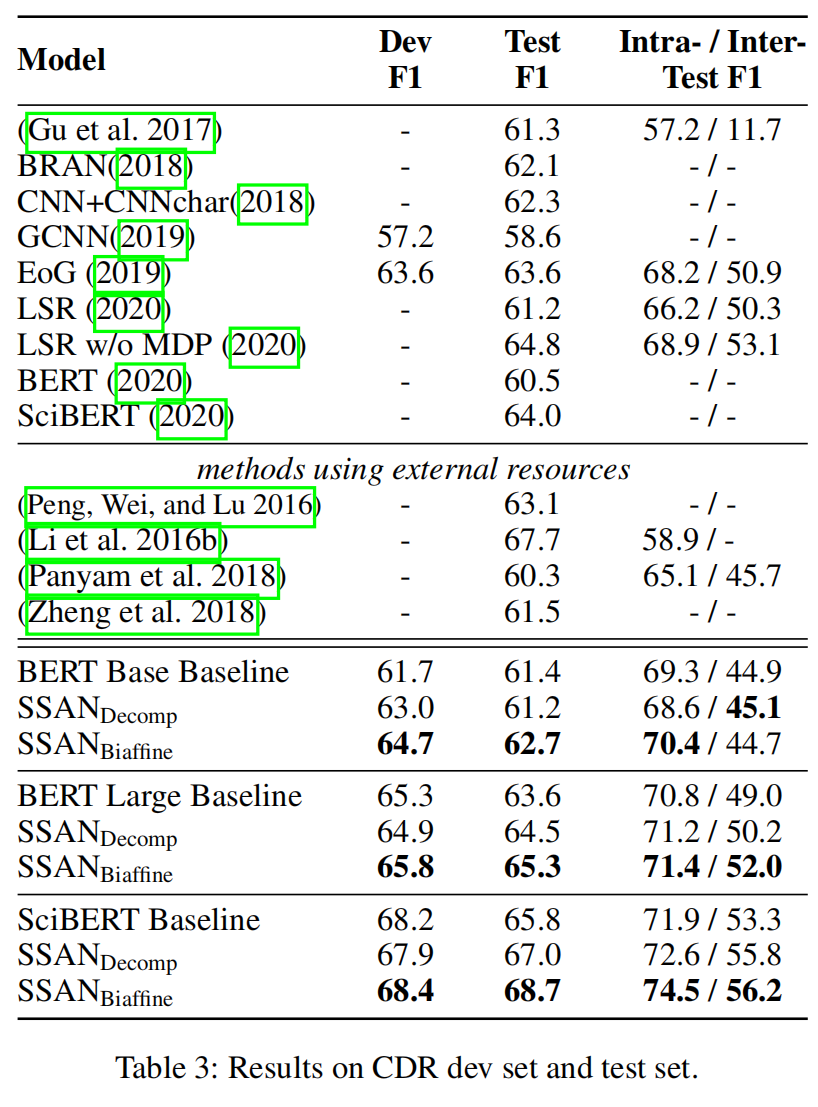
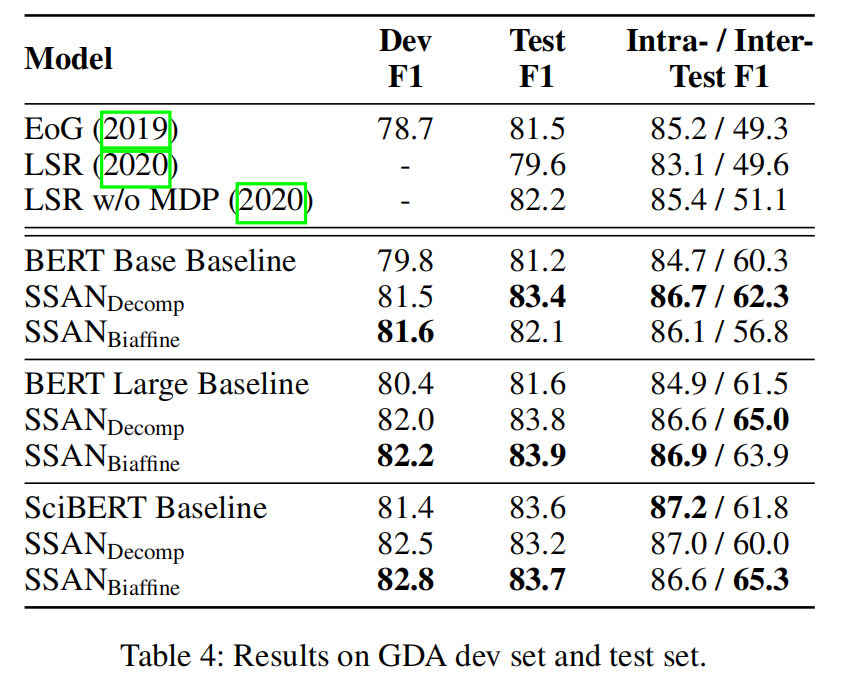
实验结果