RAPL: A Relation-Aware Prototype Learning Approach for Few-Shot Document-Level Relation Extraction
年份:2023
From:EMNLP
作者:Shiao Meng, Xuming Hu, Aiwei Liu, Shu’ang Li, Fukun Ma, Yawen Yang, Lijie Wen
机构:School of Software, Tsinghua University
GitHub:https://github.com/THU-BPM/RAPL
文档型关系抽取数据的标记费时间、人工密集,同时在垂直领域中缺乏标记数据,文档型关系抽取标记稀缺是现实世界的常见问题。文章提出了RAPL(Relation-Awared Prototype Learning),解决了以下问题:
对于支持文档中包含关系的每个实体对,利用关系描述中固有的关系语义作为指导,为每个表达的关系推导出一个实例级表示。关系原型是通过聚合其所有关系实例的表示来构建的,从而更好地关注与关系相关的信息。基于实例级的嵌入,又提出了一种关系加权对比学习方法来进一步细化原型,可以更好地区分语义密切关系的原型。
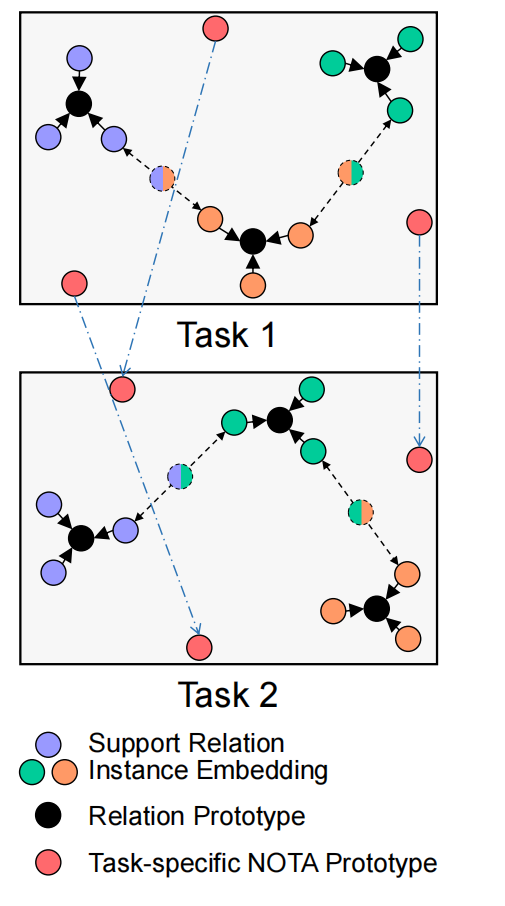
设计了一个特定于任务的NOTA原型生成策略。对于每个任务,自适应地选择支持的NOTA实例,并将它们融合成一组可学习的基础NOTA原型,以生成特定于任务的NOTA原型,从而更有效地捕获每个任务中的NOTA语义。
few-shot文档级关系抽取在实际应用中,针对labaled文档稀缺问题至关重要。现有的工作主要是matric-based元学习框架,为关系类型建模原型,是FSDLRE(Few-Shot Document-Level RE)中被应用广泛的一种框架。然而,现有的工作往往难以获得具有精确关系语义的类原型,缺陷:
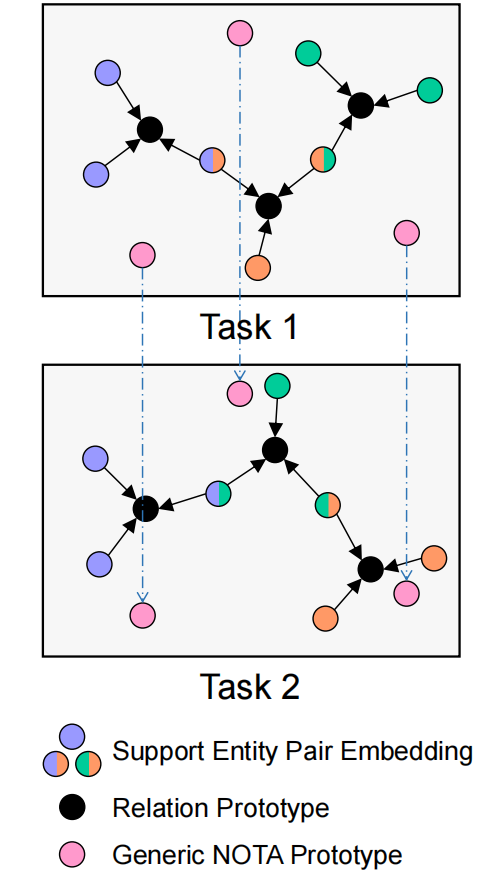
- 为了构建目标关系类型的原型,它们聚合了带有该关系的所有实体对的表示,而这些实体对也可能包含其他关系,从而干扰了原型(Overlap问题)。
- 在所有任务中使用一组通用的NOTA(None of the above)原型,而忽略了在具有不同目标关系类型的任务中,NOTA语义的不同。
模型结构
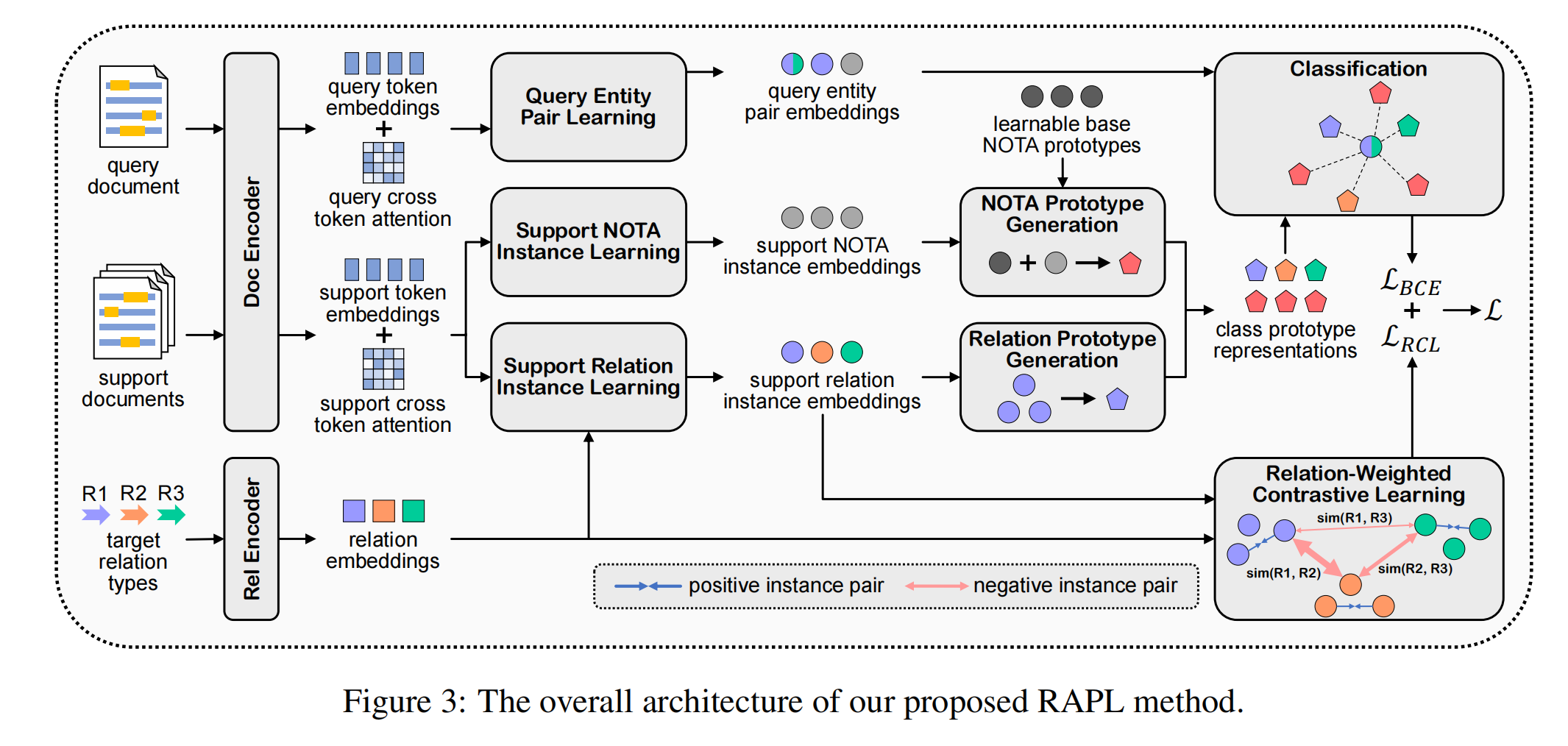
文档和实体编码器
文档编码
使用预训练语言模型(BERT等)作为文档编码器,对于每一个文档,在每个实体提及的开始和结束处插入一个特殊的token“∗”,以标记实体的位置。然后,将文档输入预训练语言模型编码器,以获得具有上下文信息的token嵌入H和交叉token注意力矩阵A。其中,H是BERT的输出;A是最后一层的平均注意力头。

实体编码
对于一个实体而言,在一个文档中可能有多次提及,使用插入特殊的标记“*”作为提及的嵌入,实体的嵌入就是多个提及嵌入的sumexp池化。
关系感知的关系原型学习
对于给定事件中的每个目标关系类型,目标是获得一个能够更好地捕获相应关系语义的原型表示。为此:
- 首先提出构建基于实例级(一个关系三元组就是一个实例)嵌入的关系原型,使每个原型能够更多地关注支持文档中的关系相关信息。
- 然后提出了一种实例级的关系加权对比学习方法,进一步细化了关系原型。
基于实例的原型构建
实体对级别的注意力分布
首先得到实体pair级别的注意力分布,获取与实体pair相关的上下文。其中实体级别的注意力分布是实体提及嵌入(A矩阵得到)的平均值:
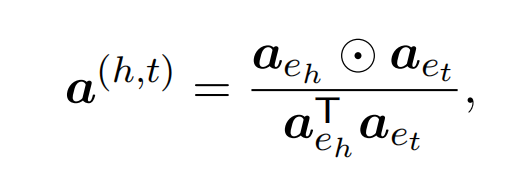
关系级别的注意力分布
同时,获取关系级别的注意力分布,使用另一个预先训练好的语言模型作为关系编码器,并将关系的名称和描述连接到一个序列中,然后将该序列输入编码器。以[CLS]的输出作为关系嵌入,并计算关系级别的注意力分布:
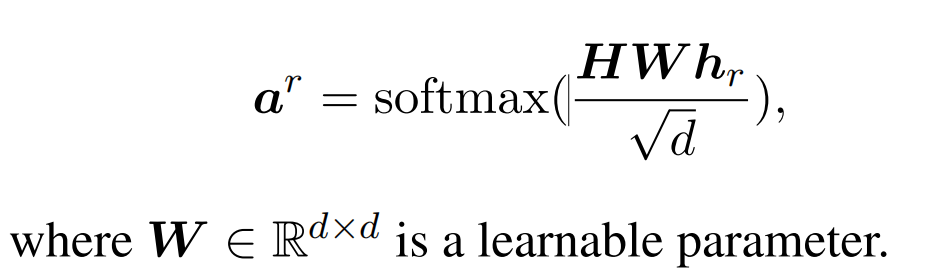
实例级别的嵌入计算
基于实体对级别和关系级别的注意力嵌入,计算实例级别的注意力嵌入,以获取实例级别的上下文信息。其中top-k%函数表示获取%k大的下标。利用关系级的注意力来放大与实例最相关的上下文的实体对级别嵌入的权重。
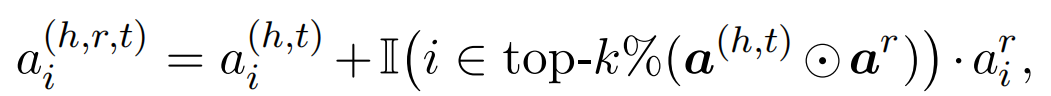
最后,计算实例级别的上下文嵌入:
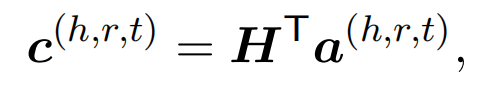
并将其融合到头实体和尾实体的嵌入中,获得具有实例感知能力的实体表示:
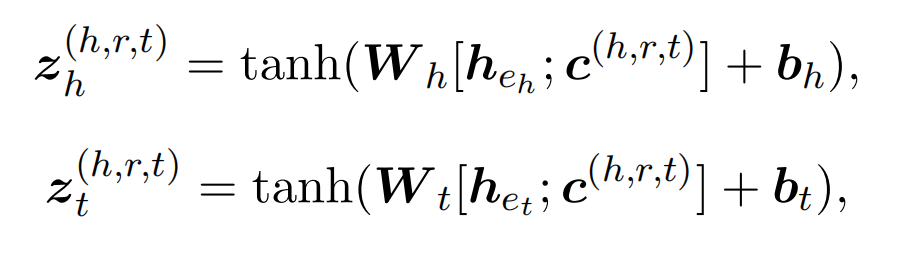
原型计算
将头实体和尾实体视为实例级别的嵌入:
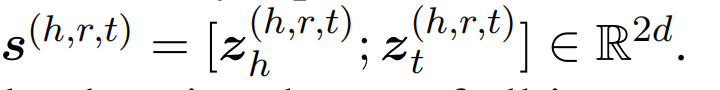
原型为实例级别嵌入的平均值:
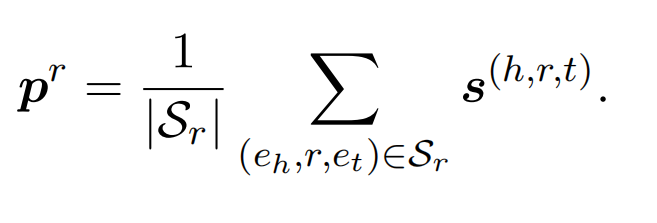
关系加权对比学习方法
提出了一种关系加权的对比学习方法以细化关系原型表示,对比学习的目标是:使得同一关系类型的实例级别表示更近,不同关系类型的实力级别表示更远。
S为Support集合中的所有实例集合;对于一个特定的实例(关系三元组),P为表达同一关系的其他实例的集合,A为其他所有实例的集合。然后定义关系加权对比学习的损失函数:
- 分子越大,分数越大,损失函数越小:当前实例和表达同一关系的其他实例的点积越大,故当前实例和表达同一关系的其他实例越接近。
- 分母越小,分数越大,损失函数越小:引入关系相似度(cossim),当不同关系的语义相似度越接近时具备更大损失,故当前实例和表达不同关系的其他实例越远。
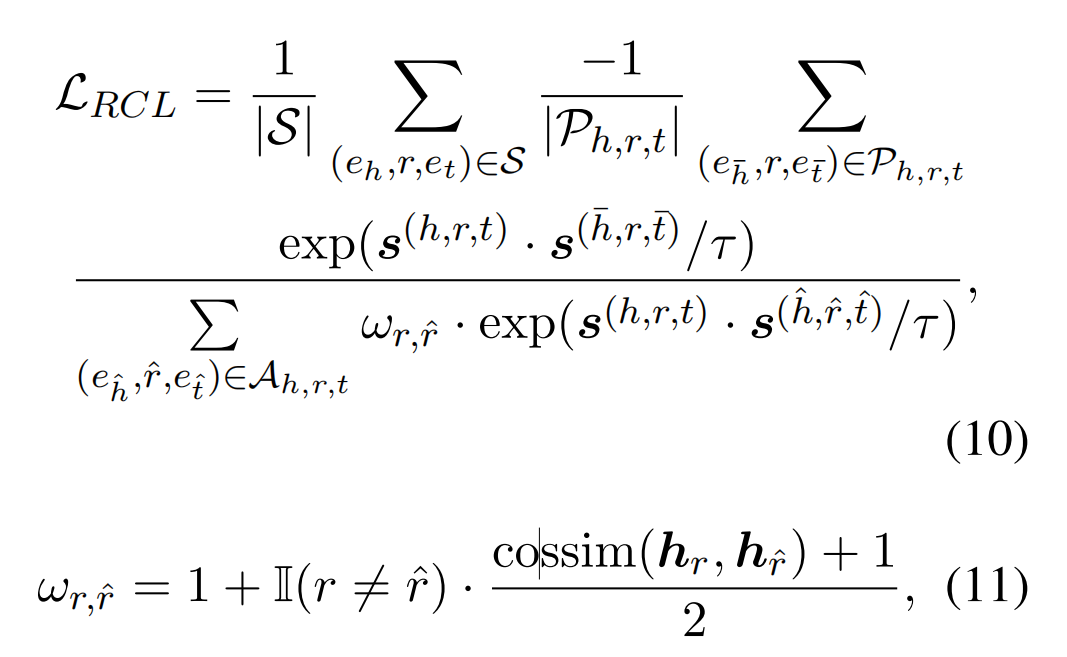
通过引入相似性,损失函数可以更好的区分相似语义的不同关系。
关系感知的NOTA原型学习
现有方法中,通常学习一组NOTA原型以应用于所有的任务。这在某些任务中可能不是最优的,因为NOTA语义在具有不同目标关系类型的任务中是不同的。为此,提出了一种特定于任务的NOTA原型生成策略,以更好地捕获每个单独任务中的NOTA语义。
引入一组可学习的向量,与以前直接将这组向量视为NOTA原型的工作不同,将它们视为需要在每个任务中进行进一步修正的基础NOTA原型。由于Support文档的注释是完整的,所以可以获取到Support集合中的隐式表达语义的NOTA分布。因此,依靠Support集合中的NOTA实例来捕获每个特定任务中的NOTA语义。
下面表达式中,它定位了接近基础NOTA原型、并且远离关系原型的NOTA实例:
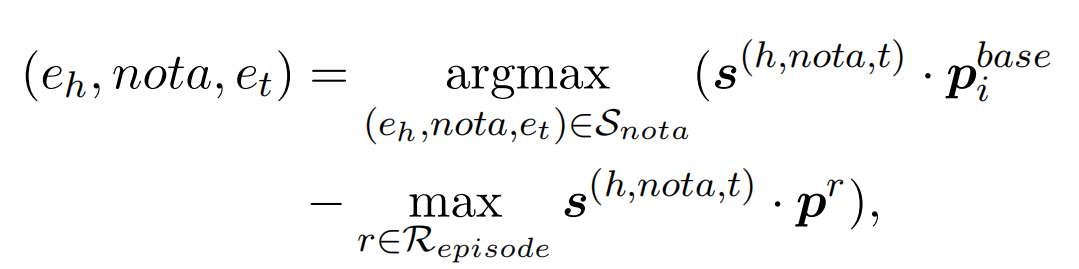
NOTA原型如下,将获取到的NOTA实例融合到基础NOTA原型中:
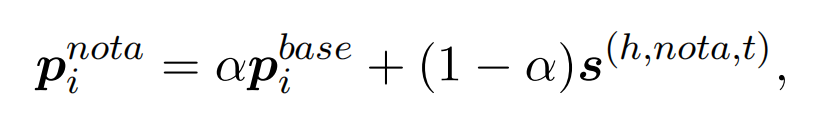
推理/训练过程
推理时,实体之间的关系类型概率判别如下:
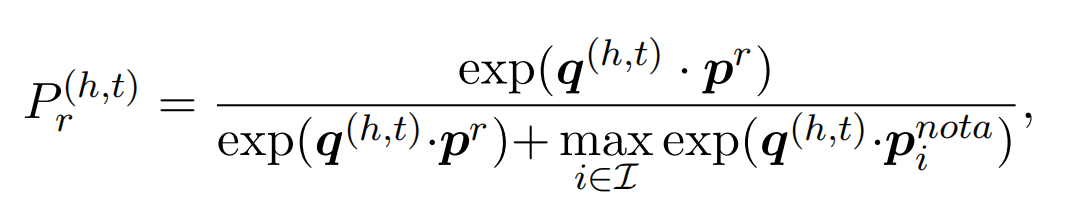
在训练时,损失函数不仅仅包含对比学习损失,还包括Query预测结果损失(BCE):
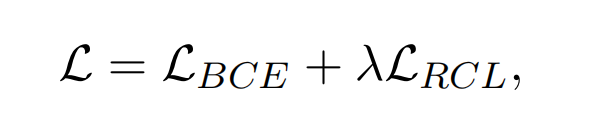
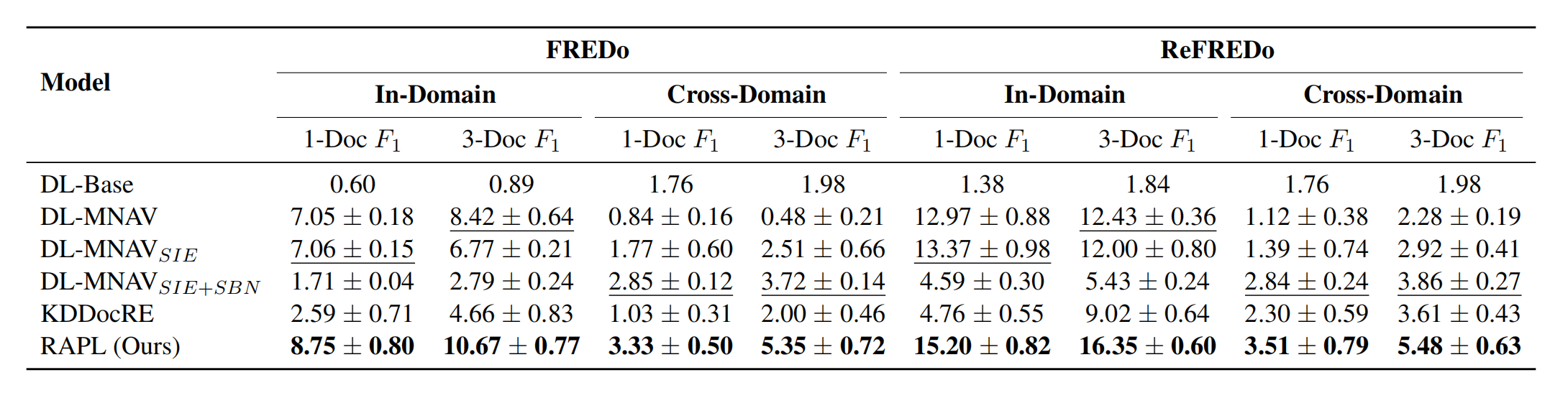
结果