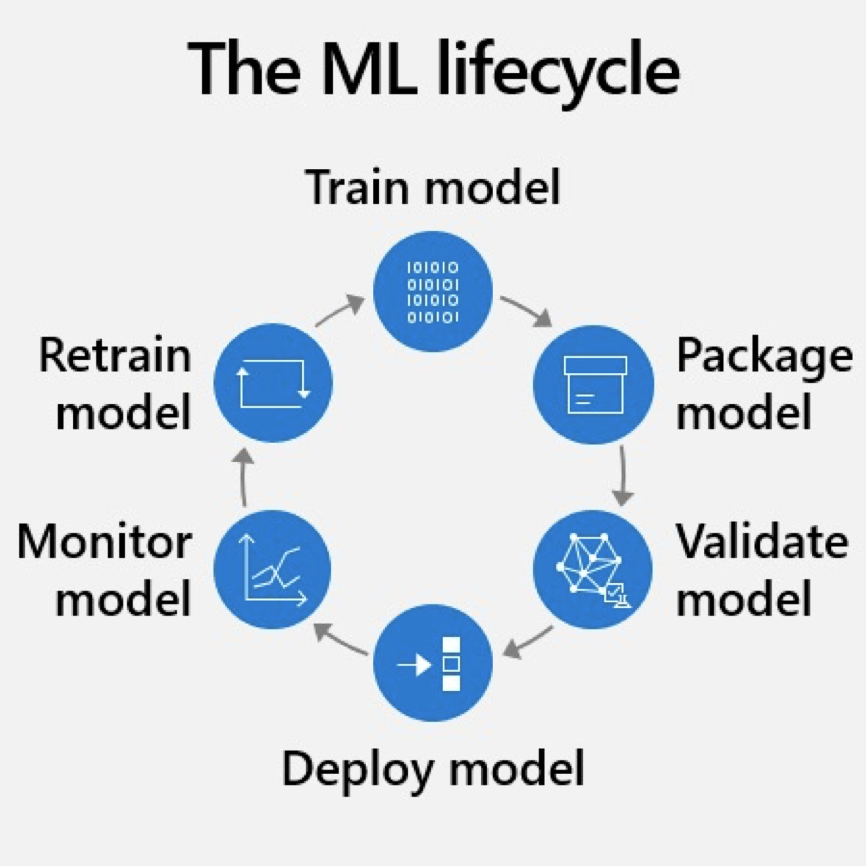
模型部署按照部署设备分类,主要分为两类:
- 云端/服务器上的部署,将模型作为一个线上服务进行部署。
- 移动端/设备端上的部署,就是将模型作为 SDK 进行部署。
本文主要探讨模型作为一个线上服务进行部署。
作为线上服务部署
把 AI 模型作为一个线上服务部署,就需要提供外界访问的接口:
- Restful HTTP 接口,使用 Flask、Django 等构建 HTTP API 服务。
- RPC 接口,如 GRPC、Thrift 等。
也可以使用深度学习框架 Serving 实现快速部署:Torch Serving、Tensorflow Serving、Triton 等。
服务优化
模型部署涉及到了服务优化,例如内存占用太大怎么办、响应速度太慢怎么办,如何在线模型更新等等问题。
更小的内存占用
优化内存占用,有两个基本思路:
分布式 kv 存储
如下图的模型结构,分为两个部分:
- dense 网络:右侧深层网络,输入用户画像、用户行为序列等高级特征,结构较复杂。
- sparse 网络:左侧浅层网络,输入用户或物料 id,结构非常简单。
推荐模型中,由于用于、候选物料极多, sparse 网络的参数占模型参数的 99%。但是进行预测时,sparse 网络只有输入的用户和候选内容 ID 对应的节点参与运算,dense 网络大部分节点都参与运算。
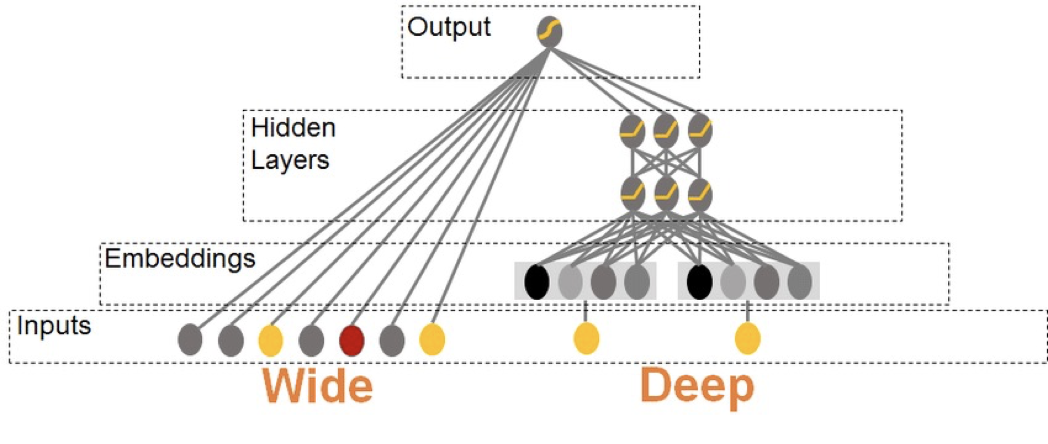
dense 网络每次计算都用到,且占用空间小,不适合独立存储;sparse 网络每次计算只用到很少一部分参数,适合独立存储。
所以将 dense 网络存储在内存中,sparse 网络以分布式 kv 的方式进行存储。
压缩模型
多用于 NLP、CV 等领域,可以使用:
- 模型量化(把模型从浮点数变为整数 INT8)。
- 蒸馏(将复杂的网络特征提取出来,迁移到参数量小的网络中)。
压缩模型会使得模型的效果变差,要在模型效果和计算速度上进行 balance。
更快的推理速度
模型加速推理的优化方向:
- 算法层加速:
- 框架层加速:tensorRT 等。
- 硬件层加速:使用 GPU 而不是 CPU。
算法层加速 - 训练后加速
训练后加速方法:
- 模型量化。
- 模型蒸馏。
- 模型剪枝:去掉模型中不重要的参数。
模型剪枝可行性:研究表明,并不是所有的参数都在模型中发挥作用,部分参数作用有限、表达冗余,甚至会降低模型的性能。
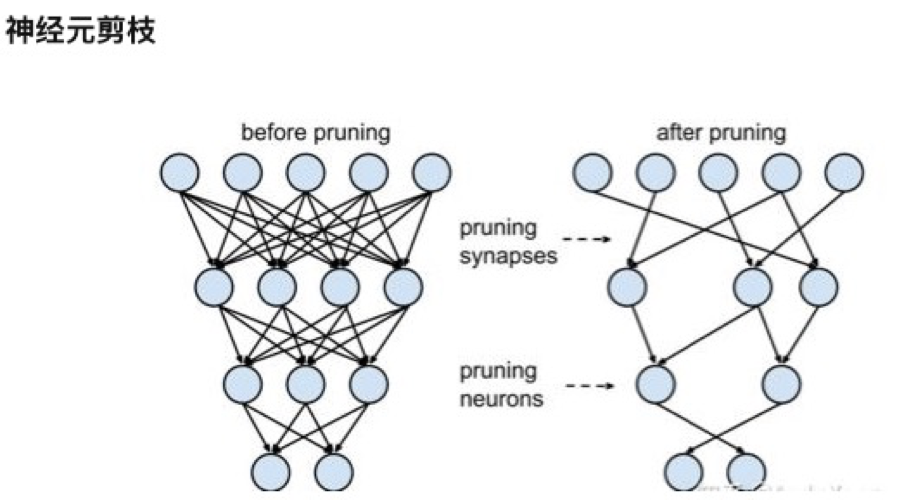
- 模型拆分:模型按照计算逻辑拆分成几部分,推理时只需要计算部分模型,其他部分在合适时机提前计算、存储好。
框架层加速
使用 tensorRT 等加速计算框架,可以合并网络结构、提高计算的并发度。
硬件加速
硬件加速就是使用 GPU 来进行推理,而不是使用 CPU。
硬件加速并不是万能药,对于简单模型不适合硬件加速,I/O 耗时大于计算耗时。
更快的模型更新
模型热更新时,有模型文件大,加载时间长,加载/更新时不可用来预测的问题,所以通过加锁的方式解决模型热更新,会造成服务短暂不可用。
double buffer 机制
为了解决加锁时服务不可用的问题,所以可以在内存空间中保存两份模型,一份用于正常运行,另一份用于更新模型,模型更新完成后切换新模型进行预测。
online learning 在线学习
在推荐领域经常用到,这里只是提出来不做详细解释。
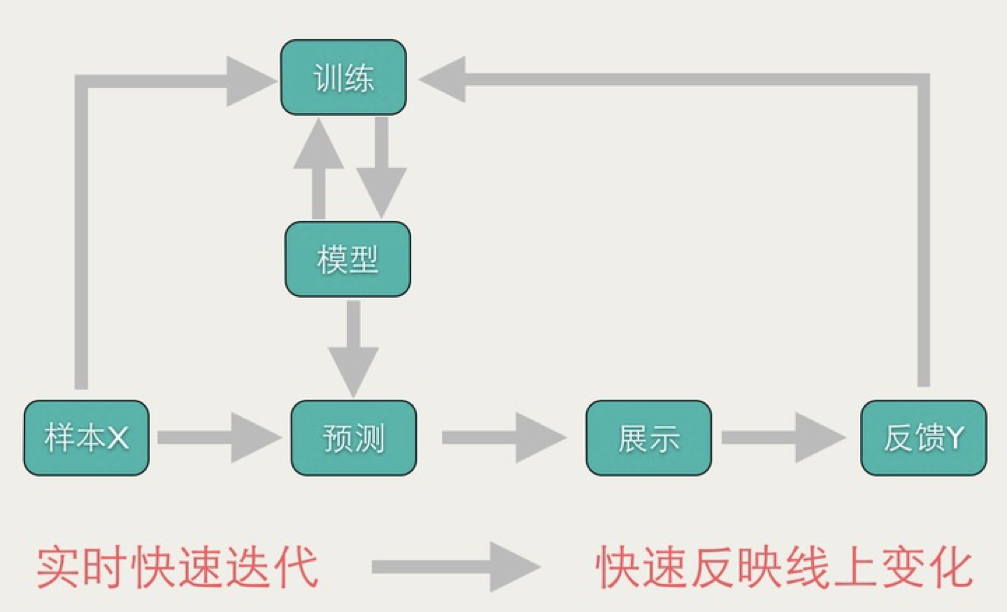
可维护性 & 开发效率提升
Serving 框架
成熟的 Serving 框架可以简化开发,提供包括但不限于以下:
- 对外暴露 HTTP/GRPC 接口。
- 模型版本管理。
- 动态 batch。
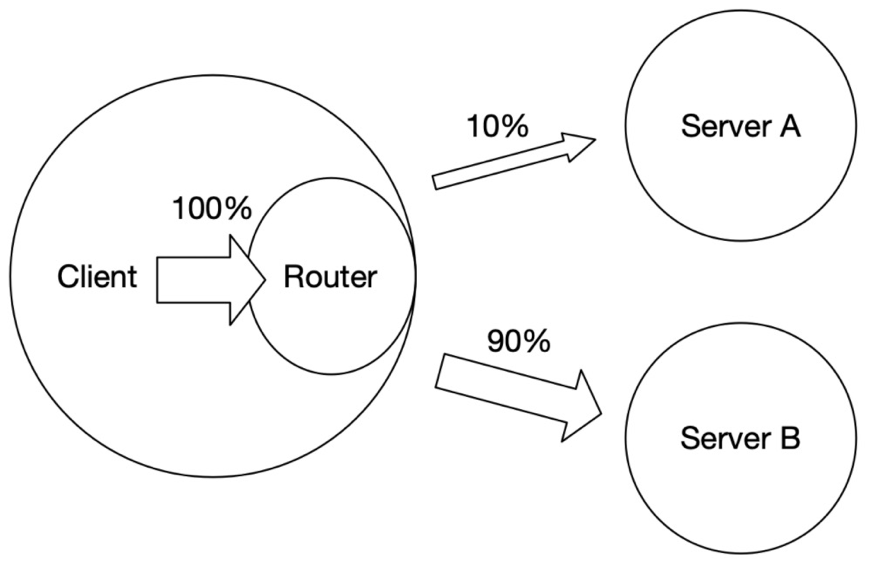
A/B 实验
部署多个模型服务,用于接收 client 的请求,通过流量控制实现 A/B 实验。
MLOps
MLOps = ML + Dev + Ops,MLOps 的原则:
- Automation:环节尽可能自动化
- Continuous:模型的持续集成、持续部署、持续监控、持续训练
- Versioning:代码、数据、模型的版本管理
- Experiment Tracking:实验记录
- Testing:数据、模型、应用的自动化测试
- Monitoring:输入数据、模型输出的监控、降级
- Reproducibility:减少随机性,保证可复现