事件溯源
事件溯源是一种以事件为中心的技术,用于实现业务逻辑和持久化。
使用事件溯源的方式的好处是:
- 提供准确的事件审计信息,保留聚合的历史。
- 与领域事件的发布是天然的契合的。
弊端在于:
- 更改了现有的业务实现逻辑,与传统的逻辑完全不同。
- 事件的结构可能发生改变,那么如何兼容新版本和旧版本事件是需要解决的问题。
- 删除是通过记录删除事件的形式进行的,这不是真正意义上的物理删除。
持久化
使用事件溯源进行持久化时,与传统的数据库表设计不同。传统的数据库表设计中,仅仅保存聚合的最终状态,一旦聚合的状态发生变化并进行了持久化,那么之前的状态我们是无从知晓的。但是在事件溯源中,存储的是聚合相关的事件,每一个条目都保存了事件类型(创建、修改、删除等),聚合的唯一标识符,以及序列化的事件(如 json 格式)。
使用事件溯源的方式组织表结构,通过检索并重放对应聚合的所有事件来重建聚合。
实现业务逻辑
使用事件溯源实现业务逻辑时,与传统的方法不同。在传统的方法中,会更新聚合的一个或者多个字段,更新之后再将聚合的最终状态存储在数据库当中。在事件溯源中,实现业务逻辑的结果就是产生一系列的事件,事件表示进行的状态更改操作,并将这些事件存储在数据库中。
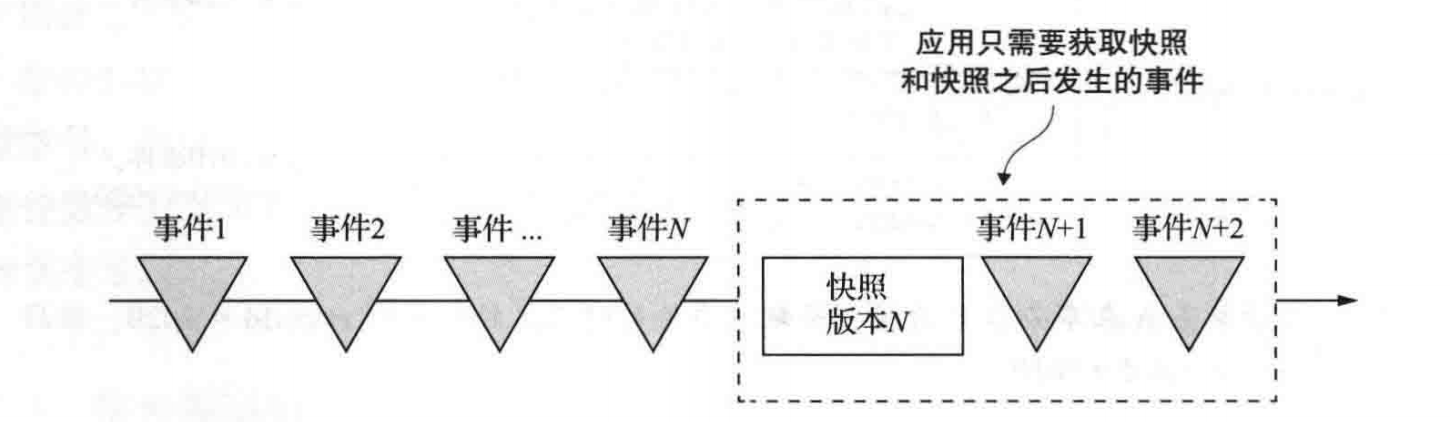
使用快照优化
使用时间溯源的方式存储数据库时,一个聚合可能会产生大量的事件,随着时间的推移,重放事件的成本会越来越高。
优化的方法就是定期的存储聚合状态的快照,然后通过加载快照,以及重放快照之后的事件来达到快速重放事件。