// The loop we generate: // for_temp := range // len_temp := len(for_temp) // for index_temp = 0; index_temp < len_temp; index_temp++ { // value_temp = for_temp[index_temp] // index = index_temp // value = value_temp // original body // }
// The loop we generate: // var hiter map_iteration_struct // for mapiterinit(type, range, &hiter); hiter.key != nil; mapiternext(&hiter) { // index_temp = *hiter.key // value_temp = *hiter.val // index = index_temp // value = value_temp // original body // }
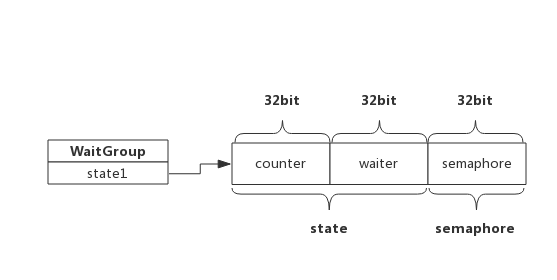
state := atomic.AddUint64(statep, uint64(delta)<<32) //把delta左移32位累加到state,即累加到counter中 v := int32(state >> 32) //获取counter值 w := uint32(state) //获取waiter值
if v < 0 { //经过累加后counter值变为负值,panic panic("sync: negative WaitGroup counter") }
//经过累加后,此时,counter >= 0 //如果counter为正,说明不需要释放信号量,直接退出 //如果waiter为零,说明没有等待者,也不需要释放信号量,直接退出 if v > 0 || w == 0 { return }
//此时,counter一定等于0,而waiter一定大于0(内部维护waiter,不会出现小于0的情况), //先把counter置为0,再释放waiter个数的信号量 *statep = 0 for ; w != 0; w-- { runtime_Semrelease(semap, false) //释放信号量,执行一次释放一个,唤醒一个等待者 } }
Wait
Wait 函数主要的流程如下:
首先,累加 waiter 的数量。
接着,如果 counter 大于 0,则阻塞当前协程等待信号量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
func(wg *WaitGroup)Wait() { statep, semap := wg.state() //获取state和semaphore地址指针 for { state := atomic.LoadUint64(statep) //获取state值 v := int32(state >> 32) //获取counter值 w := uint32(state) //获取waiter值 if v == 0 { //如果counter值为0,说明所有goroutine都退出了,不需要待待,直接返回 return }