Mutex
数据结构
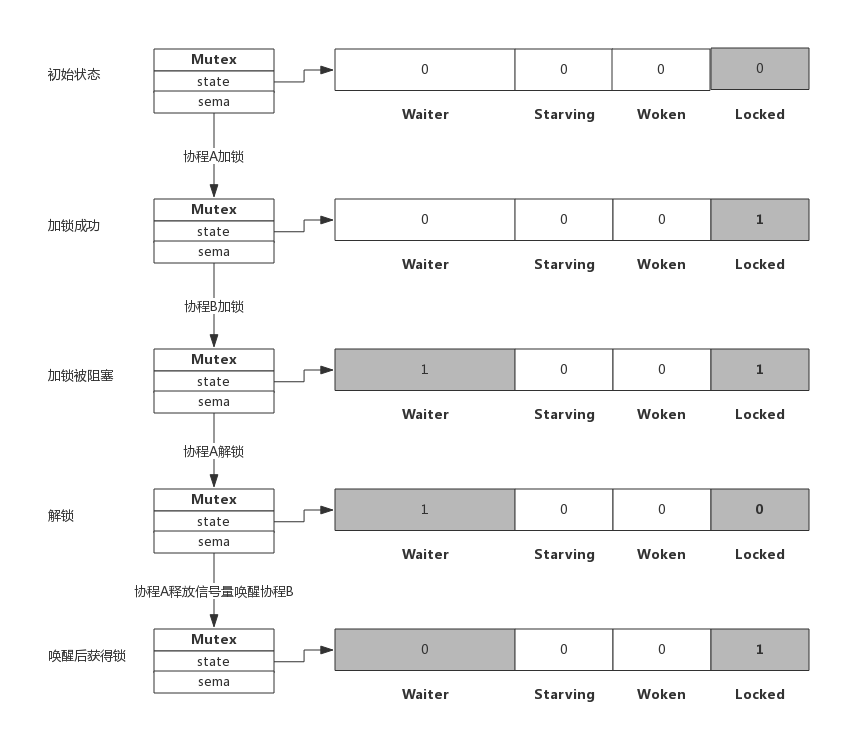
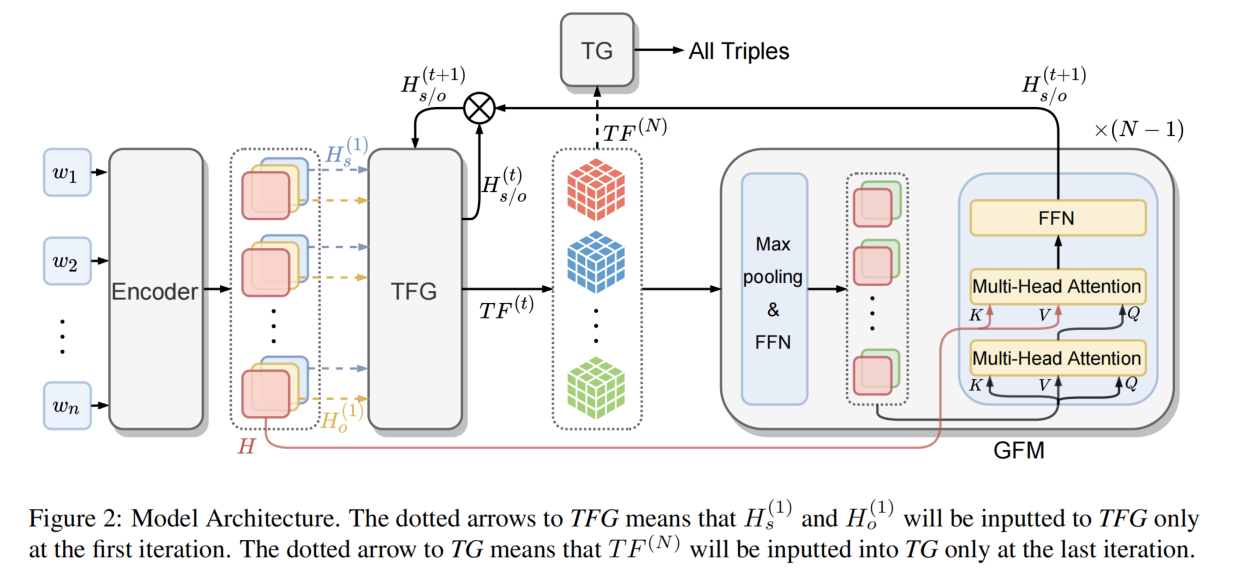
mutex 互斥锁的数据结构如下:
- state:互斥锁的状态。
- sema:信号量,协程阻塞等待该信号量,解锁的协程释放信号量从而唤醒等待信号量的协程。
1 | type Mutex struct { |
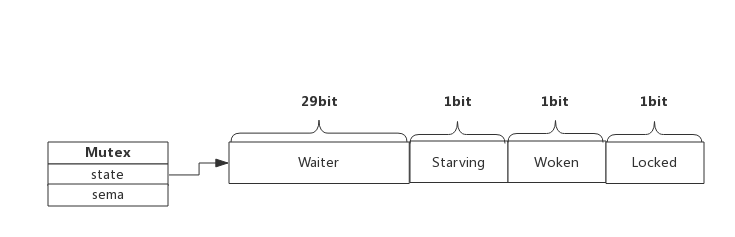
Mutex.state 是 32 位的整型变量,内部实现时把该变量分成四份,用于记录 Mutex 的四种状态:
- Locked:这个互斥锁是否被锁定。协程之间抢锁实际上是抢给 Locked 赋值的权利,能给 Locked 域置 1,就说明抢锁成功。
- Woken:是否有协程正在加锁过程中。
- Starving:互斥锁是否处于饥饿状态,饥饿状态说明有协程阻塞了超过 1ms。
- Waiter:表示阻塞等待锁的协程个数,协程解锁时根据此值来判断是否需要释放信号量。
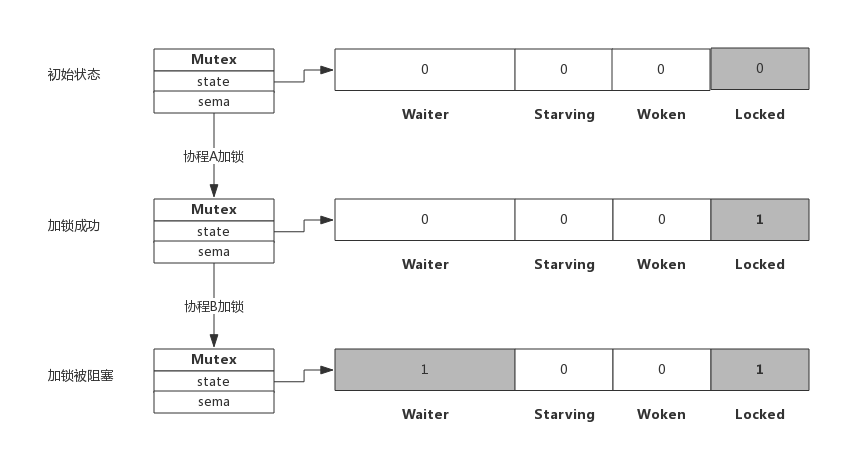
加锁解锁过程
加锁
协程 A 成功加锁,协程 B 再加锁被阻塞的过程如下:
解锁
协程 A 解锁,释放信号量唤醒协程 B 过程如下。协程 A 解锁过程分为两个步骤:
- 一是把 Locked 位置 0。
- 二是查看到 Waiter>0,所以释放一个信号量,唤醒一个阻塞的协程,被唤醒的协程 B 把 Locked 位置 1,于是协程 B 获得锁。