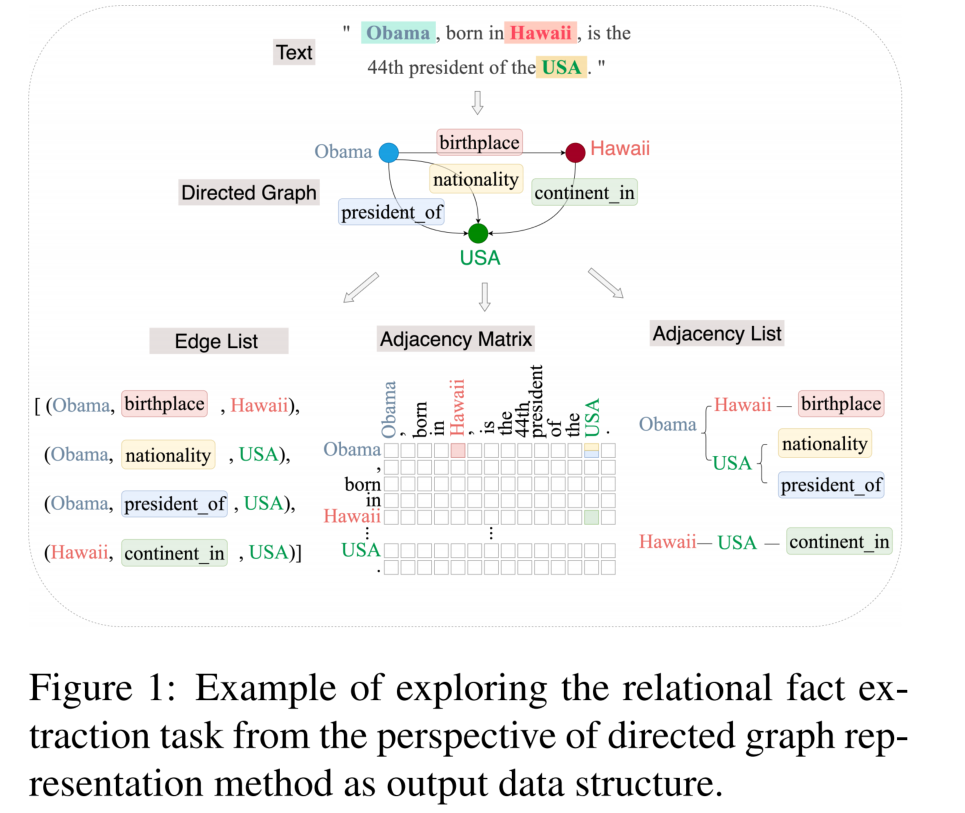
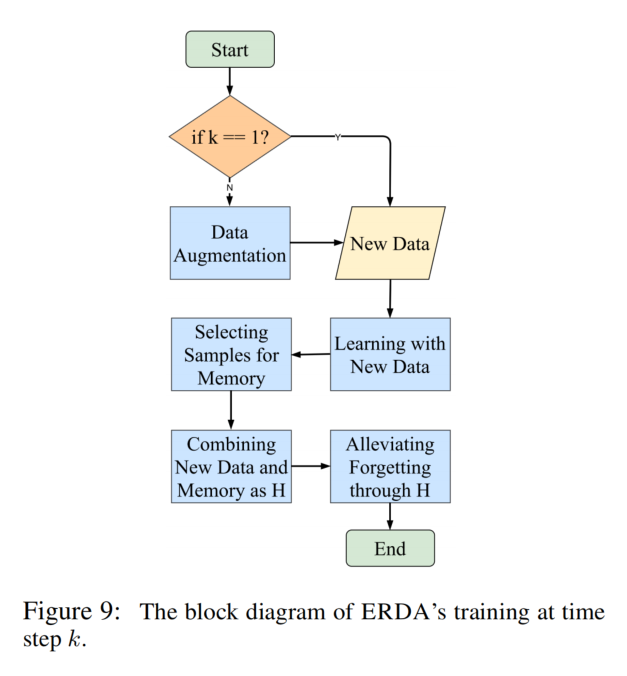
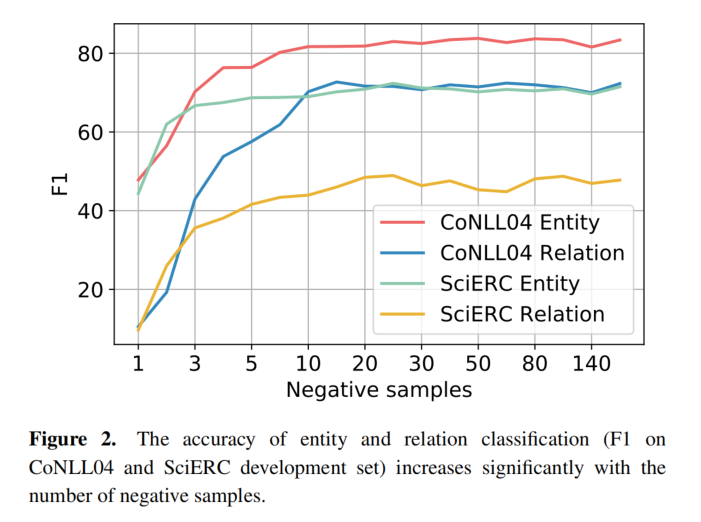
对于带有 ttl 的 key,到期清理有两种解决思路:
- 将所有带有 ttl 的 key 记录下来,比如用一个 list 保存,启动一个协程定期的去轮询。但是这样有一个缺点,就是效率低下:因为每一个的轮询都会遍历所有的 list 项,才能知道是否到期了。
- 时间轮,时间轮避免了每一次轮询所有的 list 项,每一次只会查询可能到期的 key。
时间轮
简单时间轮
时间轮实际上是一个环形队列,底层用数组实现。数组中的每个元素可以存放一个定时任务列表。定时任务列表是一个双向链表,链表中的每一项表示的都是定时任务项,其中封装了真正的定时任务。
环形队列的每一个元素,可以看作是一个时间格,每个时间格代表当前时间轮的基本时间跨度。时间格的个数是固定的,时间轮的总体事件跨度 = 时间格个数 × 时间格的事件跨度。
时间轮还有一个表盘指针,用来表示时间轮当前所处的时间(就是当前指向了哪一个时间格)。表盘指针指向的是到期的时间格,表示需要处理的时间格所对应的链表中的所有任务。
如下图所示,时间格个数为 10,基本时间跨度为 1s 的时间轮,每一格里面放的是一个定时任务链表,链表里面存有真正的任务项。

初始情况下,表盘指针指向 0。若此时有一个 2s 的任务插入进来,就会放到时间格为 2 的任务链表中。当表盘指针指向 2 时,就会执行其中的任务。
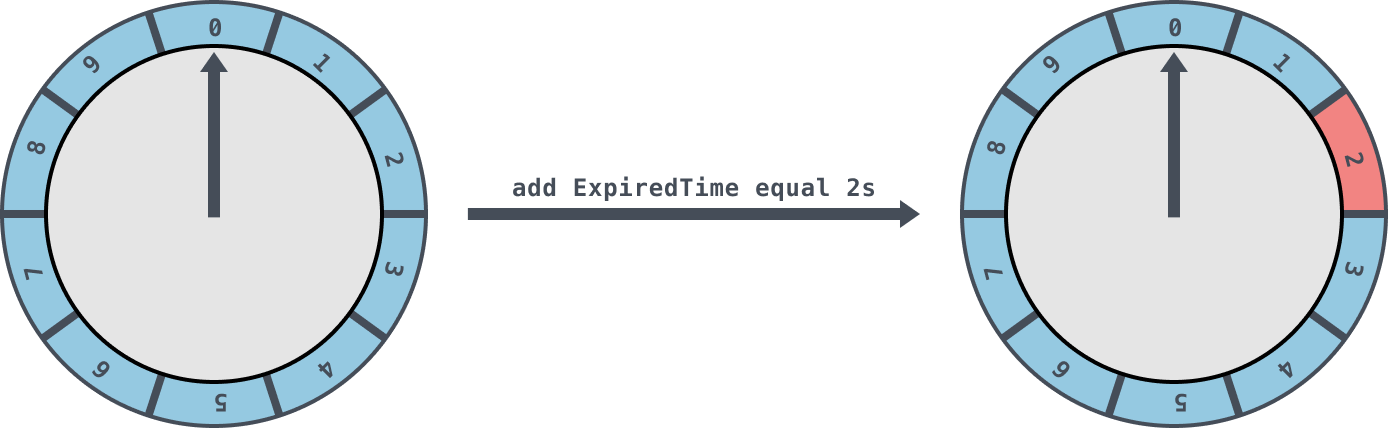
在这样的简单时间轮中,若有一个 15s 的定时任务,那么至少需要设置一个总体时间跨度为 15s 的时间轮才够用。如果需要一个一万秒的时间轮,那么可能需要一个很大的数组去存放(如果时间基本跨度为 1s,那么数组长度为 1 万)。不仅占用很大的内存空间,而且也会因为需要遍历这么大的数组从而拉低效率。
因此引入了层级时间轮的概念。
层级时间轮
层级时间轮就是引入多层的时间轮。
如下图所示,是一个两层的时间轮。第二层时间轮也是由 10 个时间格组成,每一个时间格的跨度是第一层时间轮的总体时间跨度,所以第二次时间轮的总体时间跨度为 100s。
如果像向该时间轮中添加一个 15s 的任务,那么当第一层时间轮容纳不下时,进入第二层时间轮,并插入到过期时间为 [10,19] 的时间格中。

随着时间的流逝,当原本 15s 的任务还剩下 5s 的时候,这里就有一个时间轮降级的操作,此时第一层时间轮的总体时间跨度已足够,此任务被添加到第一层时间轮到期时间为5的时间格中,之后再经历 5s 后,此任务真正到期,最终执行相应的到期操作。
在实际的实现中,一种简单的实现方式是:可以为每个任务记录下走过的圈数(circle),来表示逻辑上的层级关系。
godis 中时间轮的实现
在 godis 中,时间轮的实现采用层级时间轮(为每个任务记录下此时需要走过的圈数,表示逻辑上的层级关系)
数据结构
TimeWheel 时间轮
godis 中,时间轮的主体结构 TimeWheel 如下:
- interval:每个时间格的基本时间跨度。
- ticker:定时器,每过 interval 的时间,就会移动到下一个时间格、并且执行任务。
- slots:时间格。
- timer:因为每一个 key 都可以移除 ttl 或者 改变 ttl,所以用 timer 来定位每一个任务(key)。
- currentPos:表盘指针,指向当前的时间格。
- addTaskChannel:添加任务采用异步的操作,先将任务加入到 channel 中。
- removeTaskChannel:移除任务也采用异步的操作,将需要取消 ttl 的 key 加入到通道中。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
type TimeWheel struct {
interval time.Duration
ticker *time.Ticker
slots []*list.List
timer map[string]*location
currentPos int
slotNum int
addTaskChannel chan task
removeTaskChannel chan string
stopChannel chan bool
}
|
location 的结构如下,用于定位任务在时间格中,所在的位置:
- slot:表示时间格的下标。
- etask:表示时间格维护的双向链表中,任务元素的地址。
1
2
3
4
| type location struct {
slot int
etask *list.Element
}
|
task 任务
task 的结构如下:
- circle:表示当前表针走过的圈数,表示逻辑上的层级。每一次指向当前 task 所在的时间格时都会令 circle 减一,circle 为 0 时说明已经到达了第一层时间轮。
- delay:延迟 delay 时间之后,执行任务。
1
2
3
4
5
6
| type task struct {
delay time.Duration
circle int
key string
job func()
}
|
时间轮开始后,会开启一个 start 协程来维护时间轮。采用 select 的方式:
- 定期轮询时间到之后,调用 tickHandler 处理某一个时间格上的任务。
- 异步处理需要添加的任务、需要删除的任务。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| func (tw *TimeWheel) start() {
for {
select {
case <-tw.ticker.C:
tw.tickHandler()
case task := <-tw.addTaskChannel:
tw.addTask(&task)
case key := <-tw.removeTaskChannel:
tw.removeTask(key)
case <-tw.stopChannel:
tw.ticker.Stop()
return
}
}
}
|
添加任务
首先在 addTaskChannel 通道中加入一个 task,就表示添加了一个任务。之后时间轮会调用 addTask 方法,异步的将 task 从通道中转移到时间格中。
1
| func (tw *TimeWheel) addTask(task *task)
|
步骤如下:
- 首先计算这个任务所对应的时间格下标 pos,以及等待的圈数。
1
2
| pos, circle := tw.getPositionAndCircle(task.delay)
task.circle = circle
|
1
2
3
4
5
| e := tw.slots[pos].PushBack(task)
loc := &location{
slot: pos,
etask: e,
}
|
- 如果之前存在相同的 key 则移除位置信息,记录这个任务的位置。
1
2
3
4
5
6
7
| if task.key != "" {
_, ok := tw.timer[task.key]
if ok {
tw.removeTask(task.key)
}
}
tw.timer[task.key] = loc
|
删除任务
删除任务(为一个 key 加上 ttl)和添加任务是类似的,也是异步的方式。步骤如下:
- 首先找到这个 key 所对应的 location。
- 接着在相应的时间格内删除任务,删除 location 的信息。
1
2
3
4
5
6
7
8
9
| func (tw *TimeWheel) removeTask(key string) {
pos, ok := tw.timer[key]
if !ok {
return
}
l := tw.slots[pos.slot]
l.Remove(pos.etask)
delete(tw.timer, key)
}
|
处理任务
每过 interval 时间,都会调用 tickHandler 方法,指向下一个时间格,处理时间格上的任务。
1
2
3
4
5
6
7
8
9
| func (tw *TimeWheel) tickHandler() {
l := tw.slots[tw.currentPos]
if tw.currentPos == tw.slotNum-1 {
tw.currentPos = 0
} else {
tw.currentPos++
}
go tw.scanAndRunTask(l)
}
|
scanAndRunTask 处理任务
scanAndRunTask 是真正的处理任务逻辑,它扫描时间格列表上的每一个任务,并且执行需要执行的任务。
处理逻辑如下,首先依次扫描 list 上的每一个元素:
- 若 circle > 0,令 circle 减一,并移动到下一个元素上。
- 否则,开启一个协程执行任务,并且在 list 上删除当前元素、删除位置信息 location。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| func (tw *TimeWheel) scanAndRunTask(l *list.List) {
for e := l.Front(); e != nil; {
task := e.Value.(*task)
if task.circle > 0 {
task.circle--
e = e.Next()
continue
}
go func() {
defer func() {
if err := recover(); err != nil {
logger.Error(err)
}
}()
job := task.job
job()
}()
next := e.Next()
l.Remove(e)
if task.key != "" {
delete(tw.timer, task.key)
}
e = next
}
}
|