publicfinalclassString implementsjava.io.Serializable, Comparable<String>, CharSequence{ /** The value is used for character storage. */ privatefinalchar value[]; /** Cache the hash code for the string */ privateint hash; // Default to 0
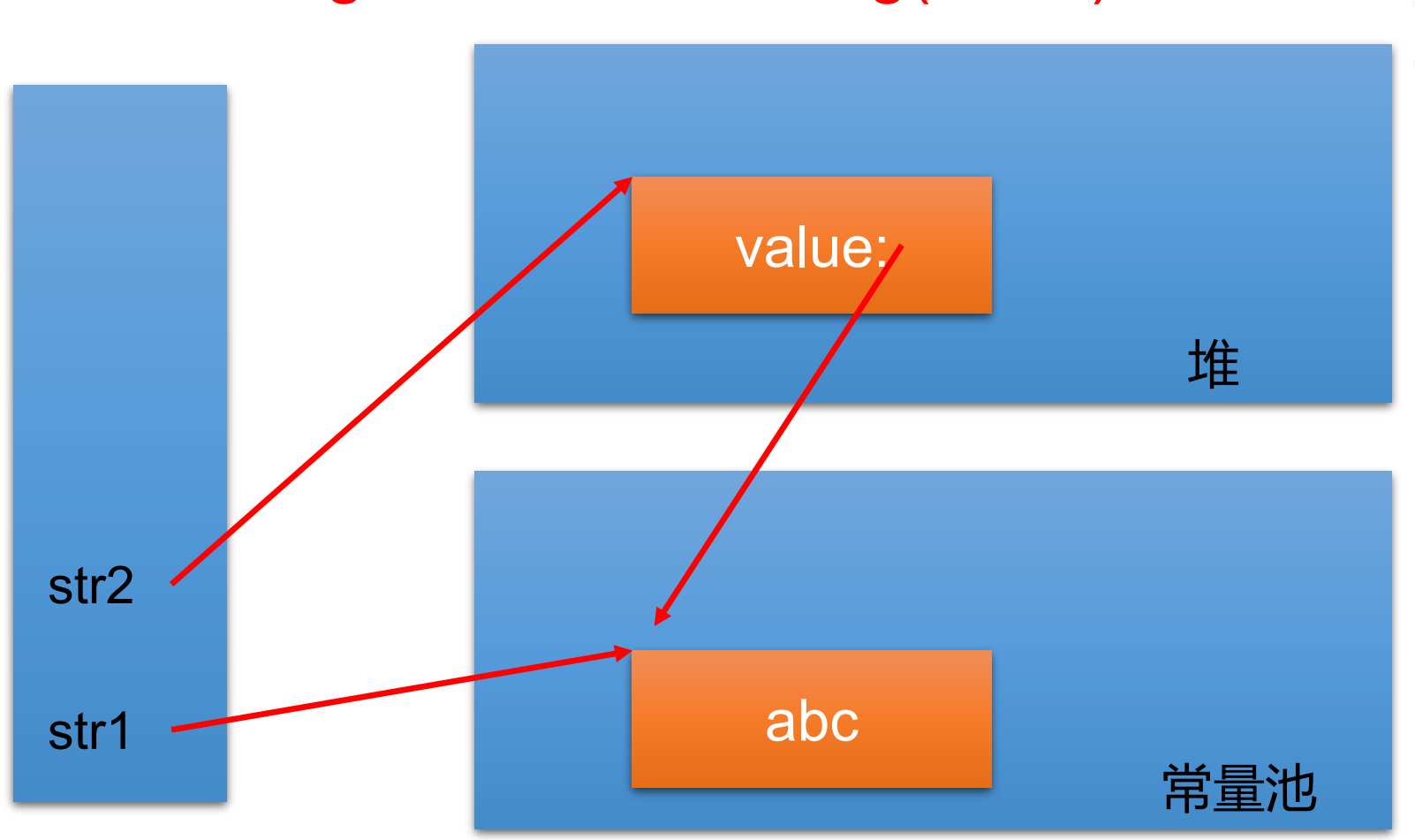
字符串存储结构
实例化字符串
当字符串以字面量(直接赋值)的方式声明一个字符串时,字符串常量直接存储在常量池中。
当以 new 的方式声明一个字符串时,字符串中非常量对象存储在堆中,对象中的 value 数组指向常量池。
// Listener will be called-back after receiving a aof payload // with a listener we can forward the updates to slave nodes etc. type Listener interface { // Callback will be called-back after receiving a aof payload Callback([]CmdLine) }
// Persister receive msgs from channel and write to AOF file type Persister struct { ctx context.Context cancel context.CancelFunc db database.DBEngine tmpDBMaker func()database.DBEngine aofChan chan *payload aofFile *os.File aofFilename string aofFsync string // aof goroutine will send msg to main goroutine through this channel when aof tasks finished and ready to shut down aofFinished chanstruct{} // pause aof for start/finish aof rewrite progress pausingAof sync.Mutex currentDB int listeners map[Listener]struct{} // reuse cmdLine buffer buffer []CmdLine }