目前有如下两个问题:
- 容量不够,Redis 如何进行扩容。
- 并发写操作,Redis 如何分摊操作。
解决方法:无中心化集群。
Redis集群
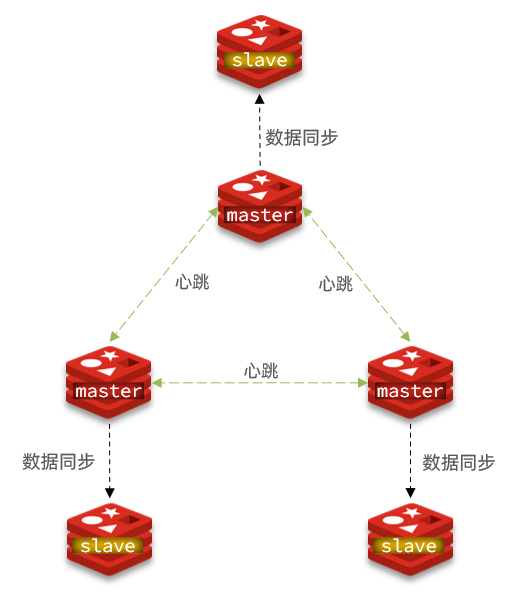
Redis 集群实现了对 Redis 的水平扩容,即启动 N 个 Redis 节点,将整个数据库分布存储在这 N 个节点中,每个节点存储总数据的 1/N。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
Compose 项目是 Docker 官方的开源项目,负责实现对 Docker 容器集群的快速编排。它允许用户通过一个单独的 docker-compose.yml 模板文件(YAML 格式)来定义一组相关联的应用容器为一个项目(project)。
Compose 中有两个重要的概念:
Compose 的默认管理对象是项目,通过子命令对项目中的一组容器进行便捷地生命周期管理。
dockers-compose 的常用命令如下:
直接使用 http.ListenAndServe():
1 | func main() { |
或者首先定义 http.Server,再调用 http.Server.ListenAndServe():
1 | func main() { |
在 n9e 服务器启动时,会将一些数据同步在内存中进行缓存。系统中的 memsto 模块用于缓存数据。
在 n9e 中,主要缓存以下数据:
SyncBusiGroups():业务组信息。SyncUsers():每一个用户信息。SyncUserGroups():用户组(团队)信息。SyncAlertMutes():告警屏蔽 Alert Mute 信息。SyncAlertSubscribes():告警订阅 Alert Subscribe 信息。SyncAlertRules():告警规则 Alert Rule 信息。SyncTargets():Target 信息,用于监控目标主机是否存活(target up 指标)。SyncRecordingRules():Recording Rule 信息。1 | func Sync() { |
缓存的流程都是类似的:
单独开启一个协程用于某部分数据的缓存同步。
协程中,开启一个循环,每 9000 毫秒同步一次数据。
1 | type Statistics struct { |
在传统 HTTP 请求中,一个 HTML 页面如果包含了其他图片、CSS 样式表等外部资源,需要发送多个请求(多轮请求耗时)。
服务器推送就是为了解决这样一种问题,服务器推送(server push)指的是,还没有收到浏览器的请求,服务器就把各种资源推送给浏览器。
比如,浏览器只请求了
index.html,但是服务器把index.html、style.css、example.png全部发送给浏览器。这样的话,只需要一轮 HTTP 通信,浏览器就得到了全部资源,提高了性能。
对于服务器推送,有一个很麻烦的问题。所要推送的资源文件,如果浏览器已经有缓存,推送就是浪费带宽。即使推送的文件版本更新,浏览器也会优先使用本地缓存。
一种解决办法是,只对第一次访问的用户开启服务器推送。
http.Pusher 推送仅支持 **Go 1.8+**,Gin 中使用 c.Push() 获取 http.Pusher:
1 | func main() { |
在 Go 1.8 中,考虑使用 http 包自带的 Shutdown() 方法优雅的关闭服务器。该方法需要传入一个 Context 参数,当程序终止时其中不会中断活跃的连接,会等待活跃连接闲置或 Context 终止(手动 cancel 或超时)最后才终止程序
特别注意:
server.ListenAndServe() 方法在 Shutdown 时会立刻返回,Shutdown 方法会阻塞至所有连接闲置或 context 完成,所以 Shutdown 的方法要写在主 goroutine 中。
如果写在其他协程中,需要配合 sync.WaitGroup 来同步等待。
在具体用应用中我们可以配合 signal.Notify 函数来监听系统退出信号,来完成程序优雅退出。
1 | // +build go1.8 |
n9e server judge引擎主要用于产生告警信息。
启动 judge 引擎时,主要有启动了 4 个 goroutine,代表了 n9e 告警引擎的四个职责:
1 | func Start(ctx context.Context) error { |
首先调用 Run 函数启动一个 n9e server,其流程如下。
1 | sc := make(chan os.Signal, 1) |
initialize 函数对 server 进行初始化:1 | cleanFunc, err := server.initialize() |
syscall.SIGHUP 信号,则调用 reload() 重新加载模板文件。1 | EXIT: |
在 reload 函数中,调用了 engine.Reload() 重新加载模板文件:
1 | func reload() { |
engine.Reload() 函数如下,其中 reloadTpls() 用于重新加载模板文件:
1 | func Reload() { |
| 命令 | 作用 |
|---|---|
| git init | 初始化本地库 |
| git status | 查看本地库状态 |
| git add 文件名 | 添加到暂存区 |
| git rm –cached 文件名 | 从暂存区中删除 |
| git commit -m “xxx” 文件名 | 添加到本地库 |
| git reflog | 查看历史记录 |
| git log | 查看版本详细信息 |
| git reset –hard 版本号 | 版本切换 |
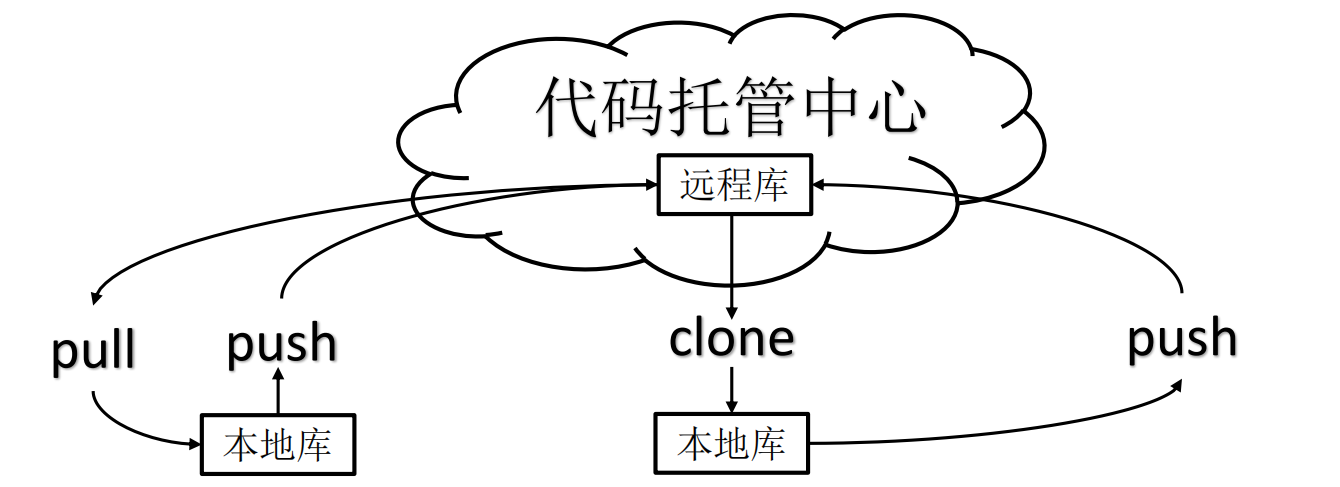
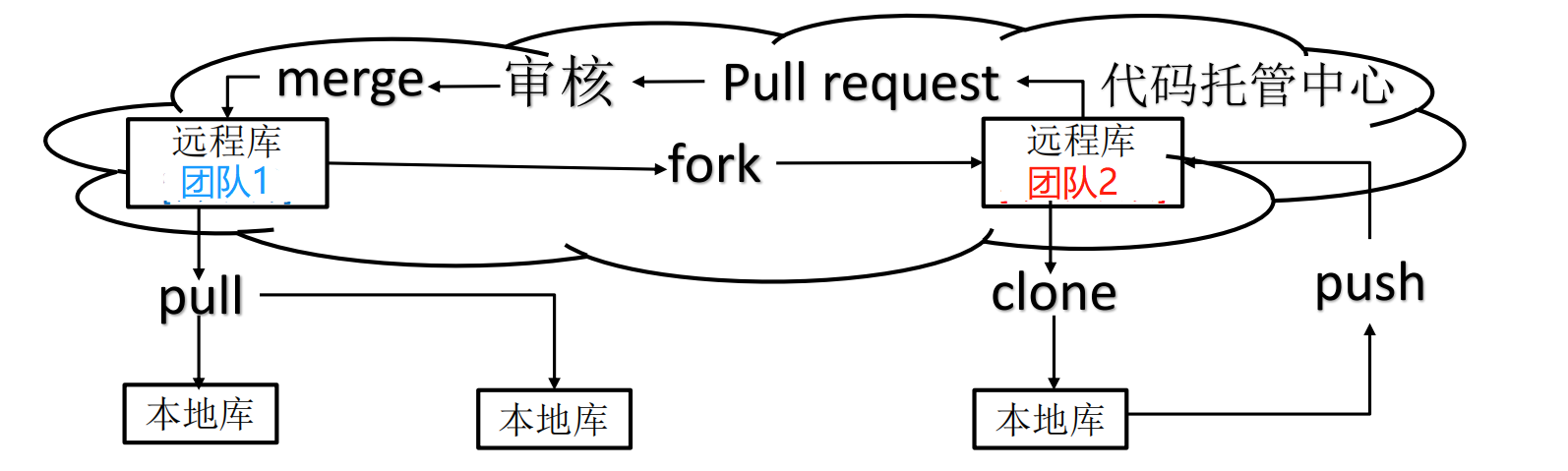
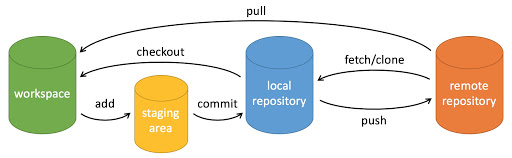
Git 常用的是以下 6 个命令:git clone、git push、git add 、git commit、git checkout、git pull。
在版本控制过程中,同时推进多个任务。所以可以为每个任务,创建每个任务的单独分支。
好处:
- 同时并行推进多个功能开发,提高开发效率。
- 各个分支在开发过程中,如果某一个分支开发失败,不会对其他分支有任何影响。
创建分支的本质就是多创建一个指针,指向一个特定的版本记录。master、other_branch 分支其实都是指向具体版本记录的指针。
当前所在的分支,其实是由 HEAD 指针决定的,所以切换分支的本质就是移动 HEAD 指针。
Git 是开源的、分布式版本控制系统。
集中式版本控制工具,如 SVN,都有一个单一的集中管理的服务器,保存所有文件的修订版本。而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或者提交更新。
好处:
- 每个人都可以在一定程度上看到项目中的其他人正在做些什么。
- 管理员也可以轻松掌控每个开发者的权限。
- 管理一个集中化的版本控制系统更加容易。
坏处:
- 中央服务器的单点故障。
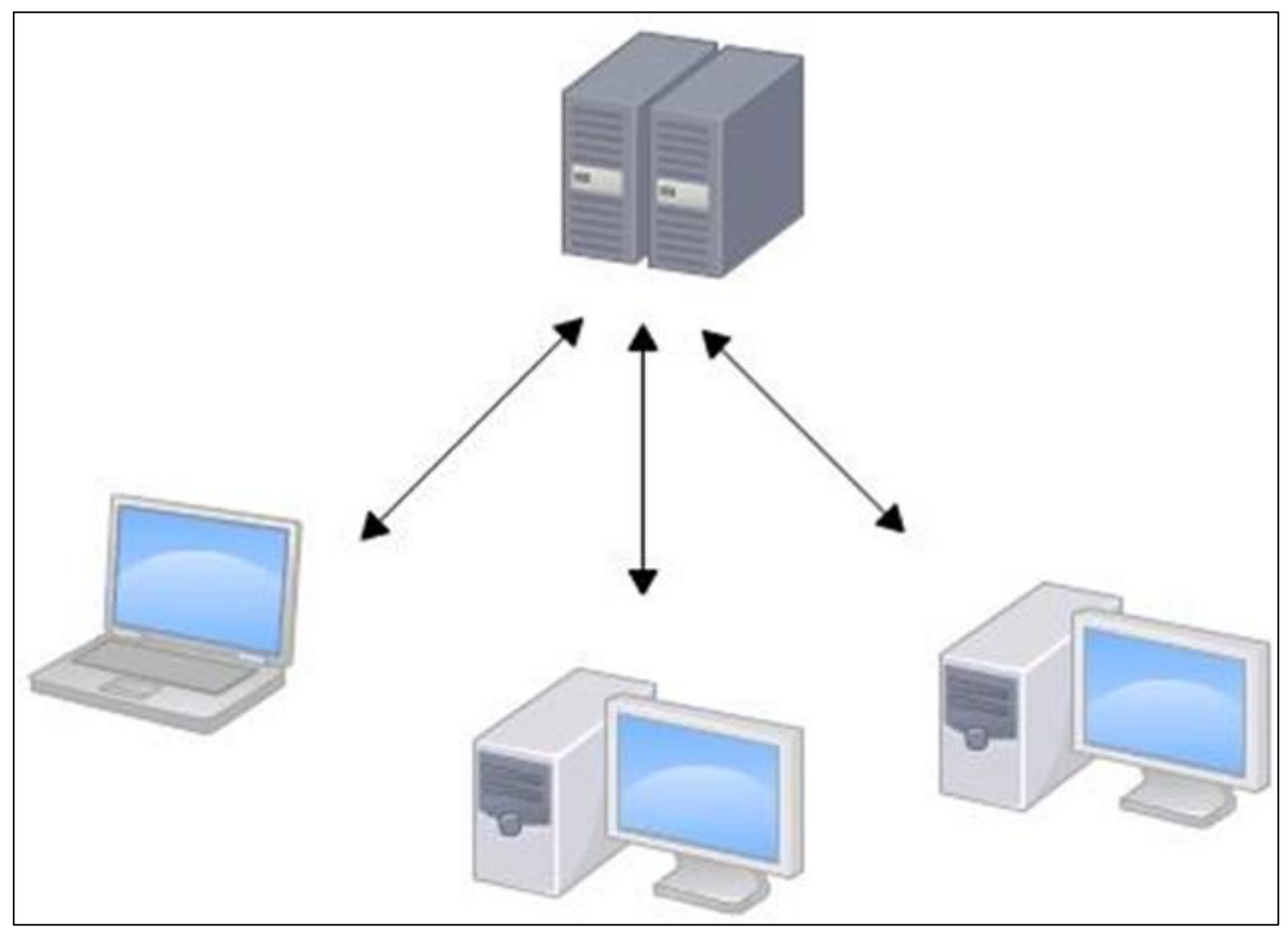
分布式版本控制工具,如 Git,客户端提取的不是最新版本的文件快照,而是把代码仓库完整地保存下来(本地库)。这样任何一处协同工作用的文件发生故障,事后都可以用其他客户端的本地仓库进行恢复。因为每个客户端的每一次文件提取操作,实际上都是一次对整个文件仓库的完整备份。
分布式的版本控制解决了集中式版本控制系统的缺陷:
- 服务器断网的情况下也可以进行开发(版本控制在本地)。
- 每个客户端保存的也都是整个完整的项目(包含历史记录,更加安全,避免单点故障)。