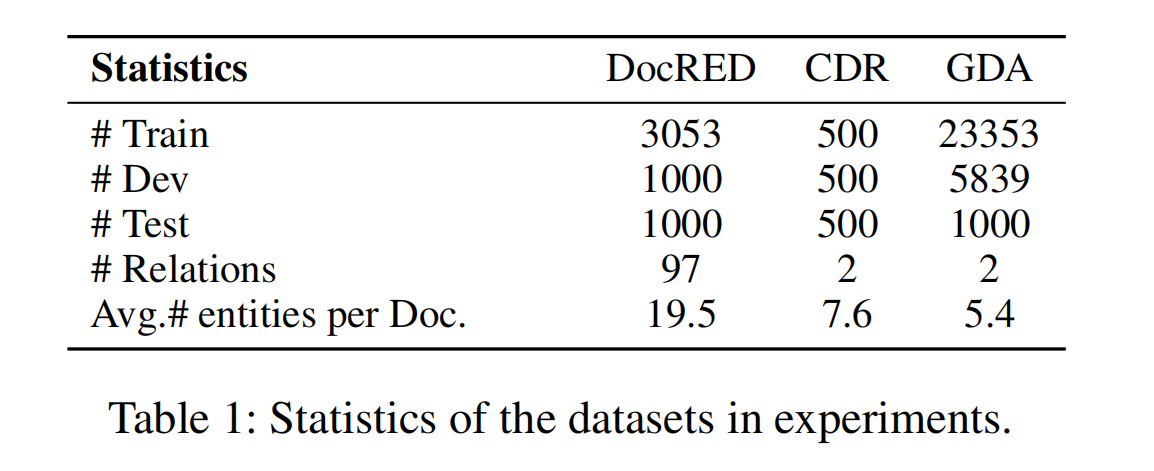
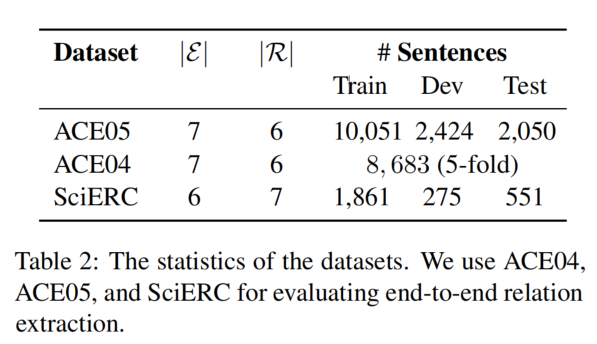
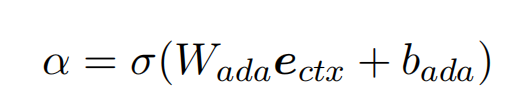GrantRel: Grant Information Extraction via Joint Entity and Relation Extraction
会议:ACL2021
作者:Junyi Bian, Li Huang
机构:School of Computer Science, Fudan University
motivation:资助信息对于学术机构和资助机构都很重要。但是目前对于这一主题的研究有两点挑战:
- 没有高质量的数据集。
- 提取资助者和 grantIDs 之间关系的负责性
贡献:
- 提出了一种 pipeline 的资助信息关系抽取框架 GrantRE,包含了两个部分 funding sentence classifier 和 joint entity and relation extractor。
- 人工标注了两个数据集,Grant-SP 包含 1402 个句子用于训练 funding sentence classifier,Grant-RE 包含 3331 个句子用于 joint entity and relation extractor。
GitHub:https://github.com/Eulring/GrantRel
grant information 作为学术文章的一部分,包含了 funder name,grant number 和它们的关系。分别将 funder name(subject)和 GrantID(object)作为实体,将 grant information 抽取问题转为关系抽取问题。

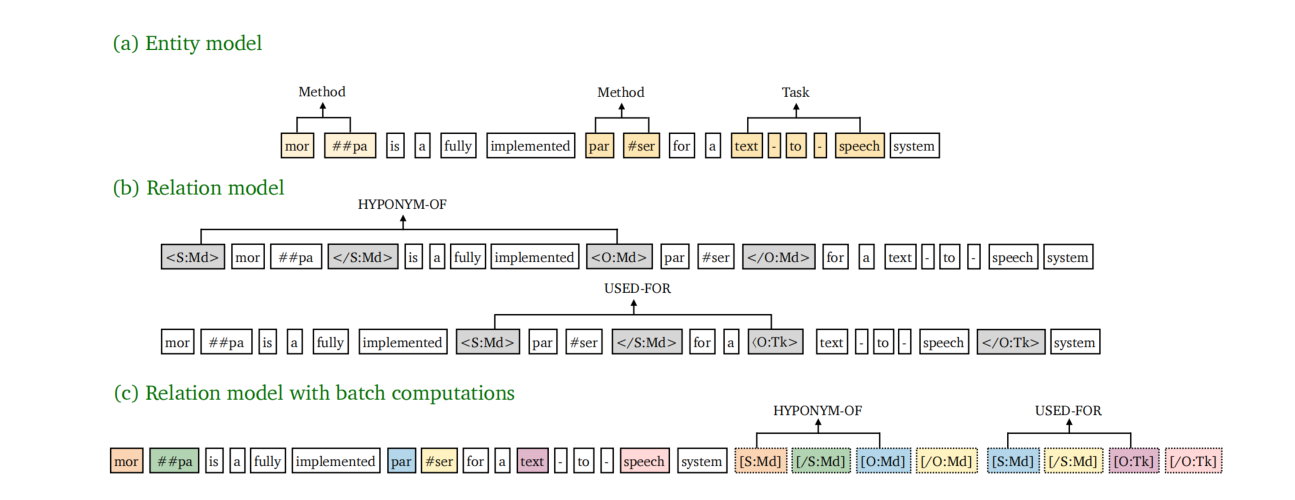
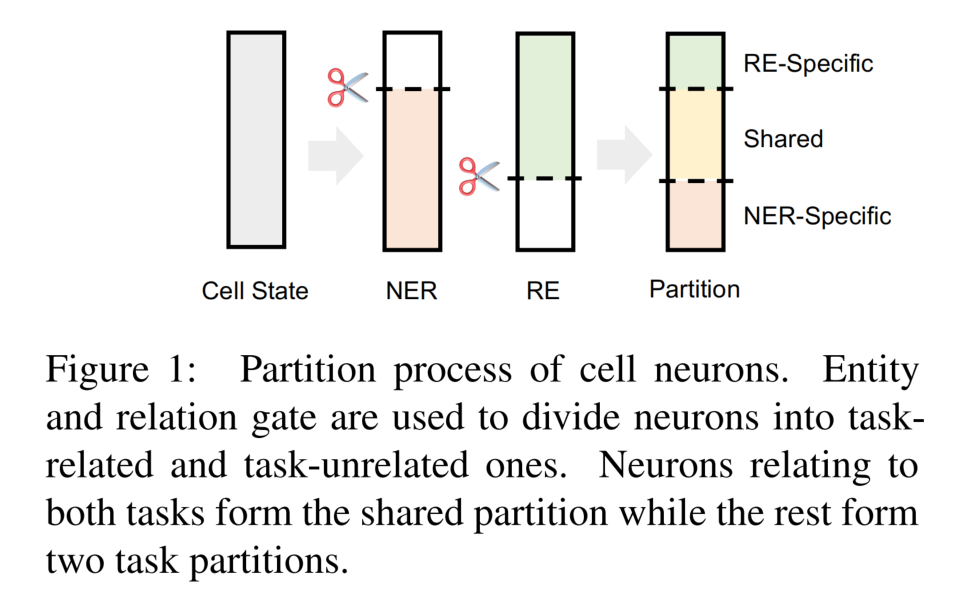
模型结构
下图的左侧为 GrantRE 的工作流:
- Sentence Classification:用于挑选出可能包含资助信息的句子。
- Relation Extraction:提取资助信息。
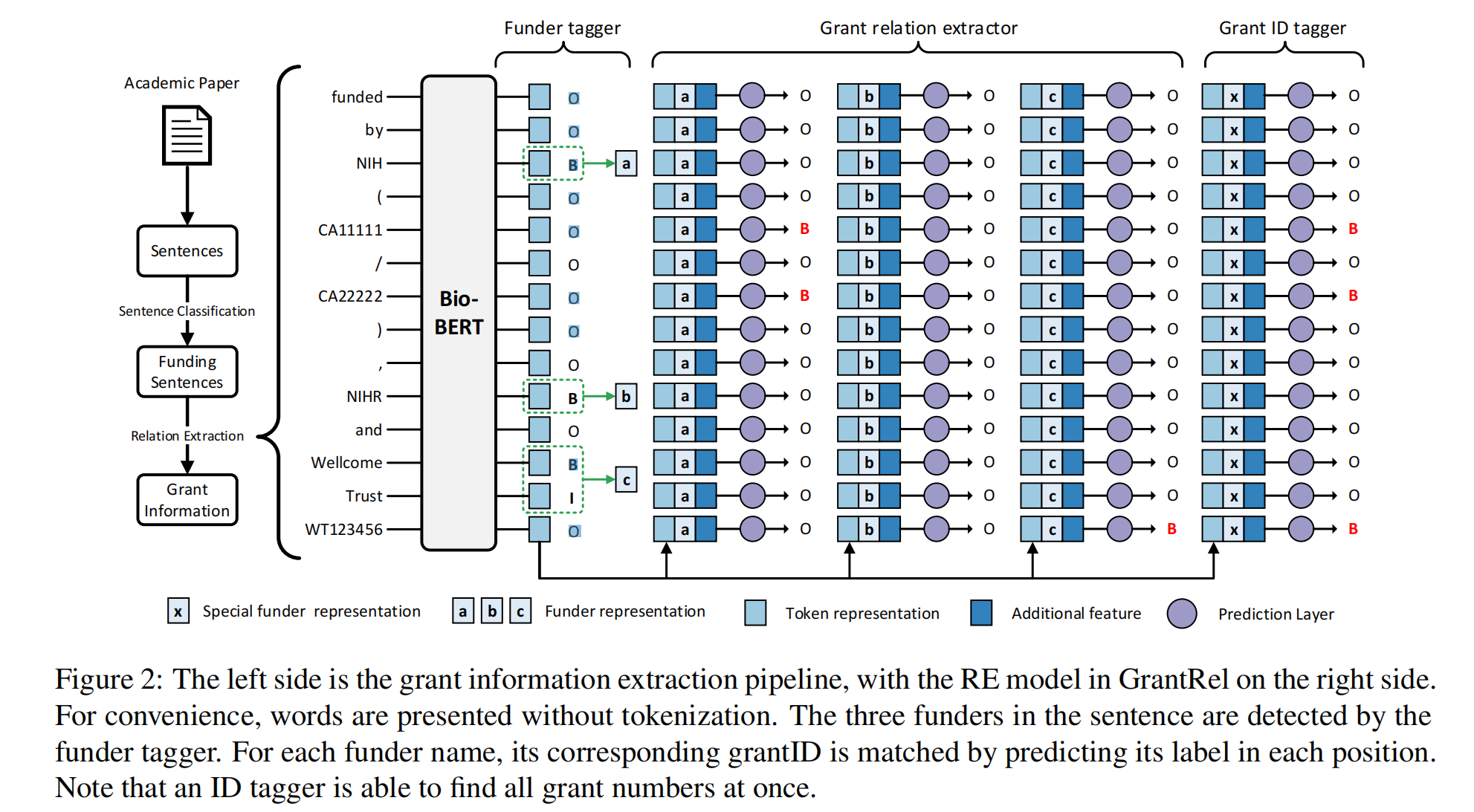
Identification of funding sentences
使用 BioBERT 作为预训练模型,将句子输入到预训练模型中,使用 [CLS] 对应的 embedding([CLS] 包含的句子的 embedding),获取这个句子包含资助信息的可能性。
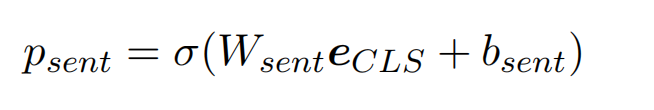
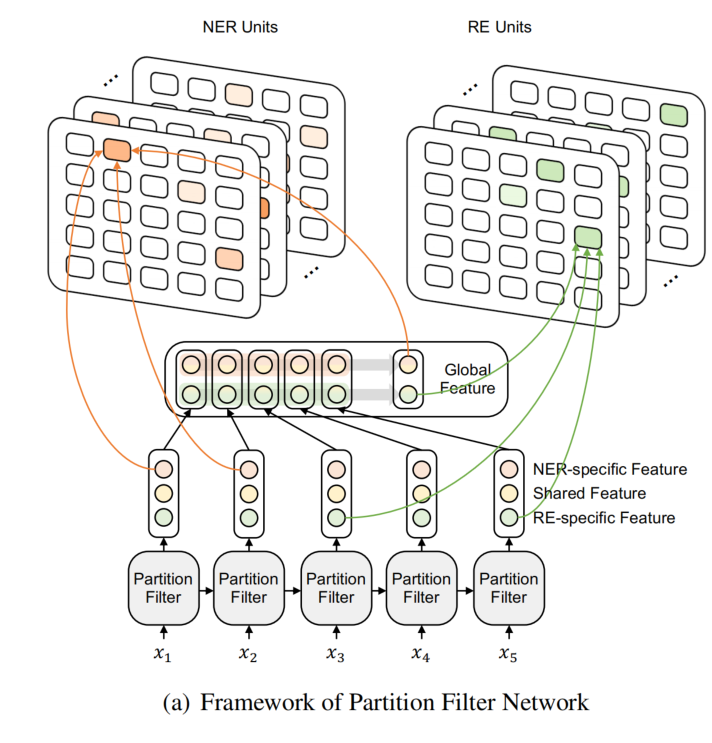
Joint entity and RE
一个资助关系包含一个 funder(subject)和一个 grantID(object)。
Funder name detection
使用 BIO 去标记实体,将 BioBERT 的输出,送入线性层中去获取 BIO 标签的概率:
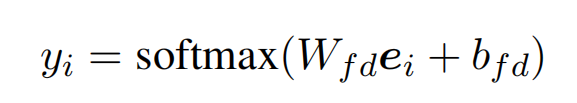
Grant relation detection
首先根据 funder name 的推理结果得到 funder name 的 embedding 表示。其中 u_fd 表示一个 funder name 实体的位置边界信息信息(起始位置和结束位置)。因为 funder name 的长度是不一致的,所以 f_fd 为平均池化操作。
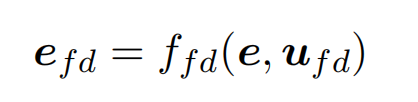
对于每一个 token 进行 BIO 标记以获取 funder name 对应的 GrantID,计算 BIO 标记概率的方法如下(e_gr 表示 grant relation feature,即模型结构图中的 addition feature):
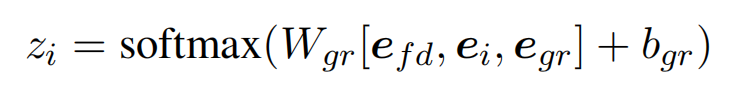
GrantID detection
如果在前一步中未检测到一个资助者的名称,那么将会错过相应的 GrantID。此外,由于句子的分割问题 GrantID 可能会在句子中独立出现而没有相应的 funder。
为了提取出完整的 GantID,使用了一个可训练的向量 e_hat 来表示所有的 funder name。这意味着句子中的所有 GrantID 都应该与这个特殊的 funder 相匹配。
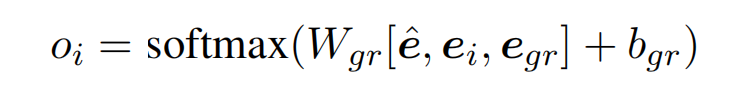
Grant relation feature
为了正确的建立 funder name 和 GrantID 之间的关系,除了使用 funder representation e_fd 之外,还使用了 addition feature e_gr。这个 feature 描述了 token 与 funder 之间的关系,用位置向量和上下文信息生成。
Position embedding
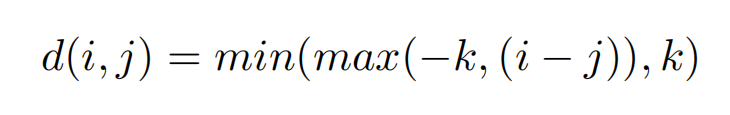
一些 funder name 的跨度相对较长,所以用一个数字来表示所有的距离是不准确的。我们将两个相对距离(与起始位置的距离和与结束位置的距离)的 embedding 作为我们最终的位置 embedding:
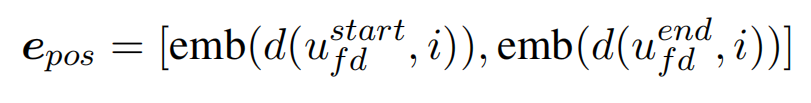
Context embedding
一个句子中除了 funder name 和当前的 token 之外的所有其他 token 为上下文,对上下文使用最大池化来获取 context embedding。
Adaptive embedding
位置和上下文的两种嵌入的组合,可以使模型更加健壮。当上下文意义非常清晰时,论文期望所提出的模型可以更多地关注上下文信息。根据这一观点,提出了一种机制,可以平衡两种 embedding,以一种自适应的方式处理不同的情况:
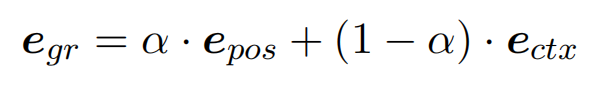
其中,α 是可训练的由上下文 embedding 决定的一个标量: