Entity-Relation Extraction as Multi-turn Question Answering
会议:ACL
年份:2019
作者:Xiaoya Li, Fan Yin, Zijun Sun, Xiayu Li, Arianna Yuan, Duo Chai, Mingxin Zhou, Jiwei Li
机构:Shannon.AI Computer Science Department, Stanford University
数据集:ACE 04、ACE 05 和 CoNLL04。并且构建了一个新的数据集 RESUME。
- ACE 04 :
- 定义了 7 种实体类型:Person(PER)、Organization(ORG)、Geographical Entities(GPE)、Location(loc)、Facility(FAC)、Weapon(WEA)和 Vehicle(VEH)。
- 定义了 7 种关系类型:Physica(PHYS)、Person-Social(PER-SOC)、Employment-Organization(EMP-ORG)、Agent-Artifact(ART)、PER/ORG Affiliation(OTHER-AFF)、GPE-Affiliation(GPE-AFF)和 Discourse(DISC)
- ACE 05:
- 保留了 PER-SOC、ART 和 GPE-AFF 类别,将 PHYS 分为了 PHYS 和一个新的类别 PART-WHOLE,删除了类别 DISC,将 EMP-ORG 和 OTHER-AFF 合并为了一个新的类别 EMP-ORG。
- CoNLL04:
- 定义了 4 种实体:LOC、ORG、PER 和 OTHERS
- 5 种关系类别:LOCATED IN、WORK FOR、ORGBASED IN、LIVE IN、KILL
贡献:
- 将实体关系联合抽取任务转换为多轮次的 QA 任务,即从上下文中识别答案范围。
- 构建了一个新开发的中文 RESUME 数据集简历,它需要多步推理来构建实体依赖,而不是在以前的数据集的三元组提取中进行单步依赖提取。
RESUME 数据集
ACE 和 CoNLL04数据集基于关系三元组的提取,两轮 QA 就可以提取三元组:第一轮用于提取头实体,第二轮用于提取尾实体和关系。这些数据集不涉及层次的实体关系。
因此,论文中构建了一个新的数据集 RESUME,从 IPO(指首次公开募股)招股说明书中描述管理团队的章节中提取了 841 个文档。每一个文档都描述了一些主管的工作历史,并从简历中提取结构性数据。该数据集是用中文表示的。
定义了 4 种类型的实体:Person、Company、Position、Time。值得注意的是,一个人可以在不同的时间在不同的公司工作,一个人可以在不同的时间在同一公司担任不同的职位。将所有数据以(人,公司,时间,职位)进行组织,表示一个人在某事件某公司担任某职位:
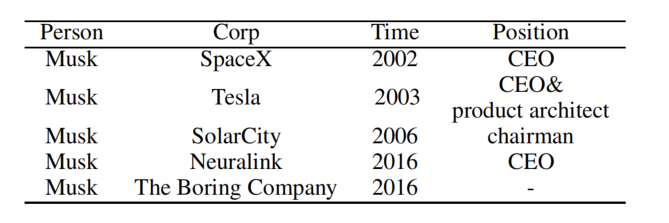
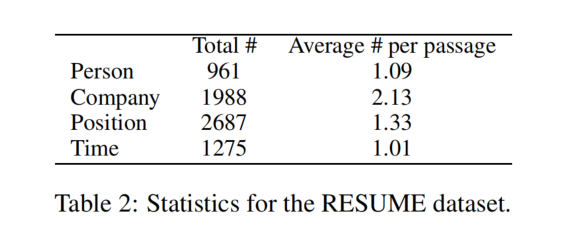
RESUME 数据集的统计数据如下:
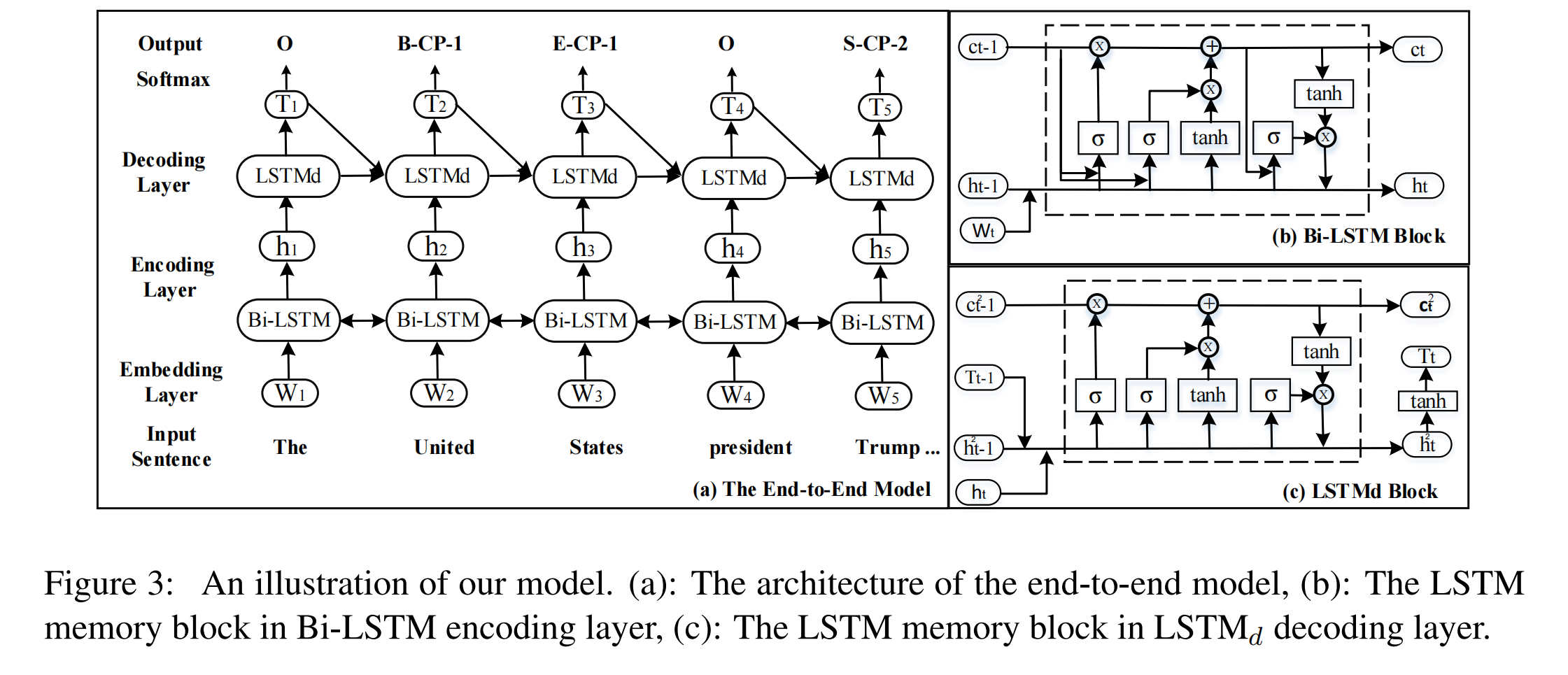
模型结构
算法分为两个阶段:
- 头实体提取阶段(4 - 9 行):为了提取头实体,使用 EntityQuesTemplates(line 4)将实体类别转化为一个问题,并通过回答这个问题(line 5)提取实体 e(若答案是 None,则说明不包含该类型的任何实体)。
- 关系和尾实体提取阶段(10 - 24 行):ChainOfRelTemplates 定义了一个关系链,需要遵循它的顺序来运行多轮次的 QA(因为一些实体的提取依赖于其他实体的提取,比如在 RESUME 数据集中,高管所担任的职位依赖于他所工作的公司,时间实体的提取也依赖于公司和职位的提取。)。提取的顺序是人为预先定义的。ChainOfRelTemplates 还定义了每一种关系的模板,每个模板都包含一些要填充的插槽。为了生成一个问题(line 14),我们将先前提取的实体插入到模板中的插槽中。通过回答生成的问题(line 15)共同提取 REL 和尾部实体 e。
值得注意的是,从头实体提取阶段提取的实体可能不都是头实体。如果从第一阶段提取的一个实体 e 确实是一个关系的头实体,那么 QA 模型将通过回答相应的问题来提取该尾部实体。否则,答案将是 None,因此这个错误的头实体会被忽略。