海象运算符
从 Python 3.8 开始,加入了海象运算符 :=,语法格式是 variable_name := expression。
用法
用于 if-else 条件表达式中
1 | if a := 5 > 1: |
用于 while 循环
1 | # 常规写法 |
加 1 是因为在循环条件判断之前,n 已经减 1 了。
读取文件
1 | fp = open("test.txt", "r") |
从 Python 3.8 开始,加入了海象运算符 :=,语法格式是 variable_name := expression。
用于 if-else 条件表达式中
1 | if a := 5 > 1: |
用于 while 循环
1 | # 常规写法 |
加 1 是因为在循环条件判断之前,n 已经减 1 了。
读取文件
1 | fp = open("test.txt", "r") |
装饰器(Decorators),是 Python 中修改其他函数的功能的函数,有助于让我们的代码更简短。
比如可以用一个简易的装饰器,定义一个函数执行之前或者执行之后做的额外工作:
1 | # 这是一个装饰器 |
当一个函数需要这个装饰器时,可以这样调用:
1 | def a_function_requiring_decoration(): |
以上就是一个手动实现的装饰器,可以用 @ 符号来更简单的实现。事实上,@a_new_decorator 就是以下语句的简易声明:
a_function_requiring_decoration = a_new_decorator(a_function_requiring_decoration)
1 |
|
但是,运行如下代码会存在一个问题:
1 | print(a_function_requiring_decoration.__name__) |
因为函数 a_function_requiring_decoration 被重写了,所以这个函数被 warpTheFunction 替代了,这里就需要 functools.wraps。
修改修饰器的声明方式即可解决上述问题:
1 | from functools import wraps |
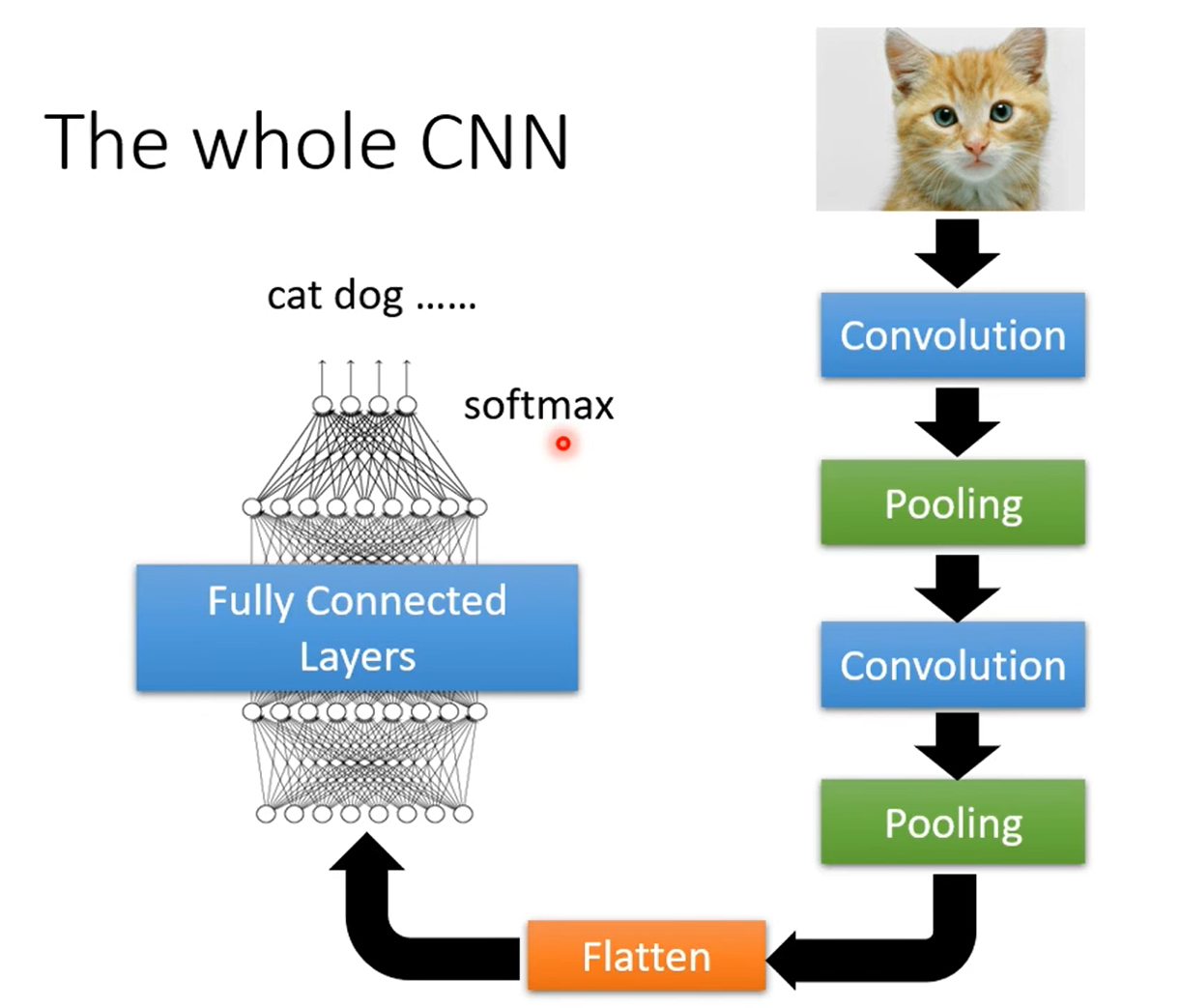
对于图片而言,通常使用 CNN(卷积神经网络)。
若使用全连接神经网络,则参数很多,容易过拟合。
对于图片检测而言,也行不需要看整张图片,只需要看到图片的一部分(所以提出 Receptive Field),就可以检测 pattern。CNN 的简化方式就是一个 Receptive Field 对应于一个神经网络单元。典型的 Receptive Field 设置如下:
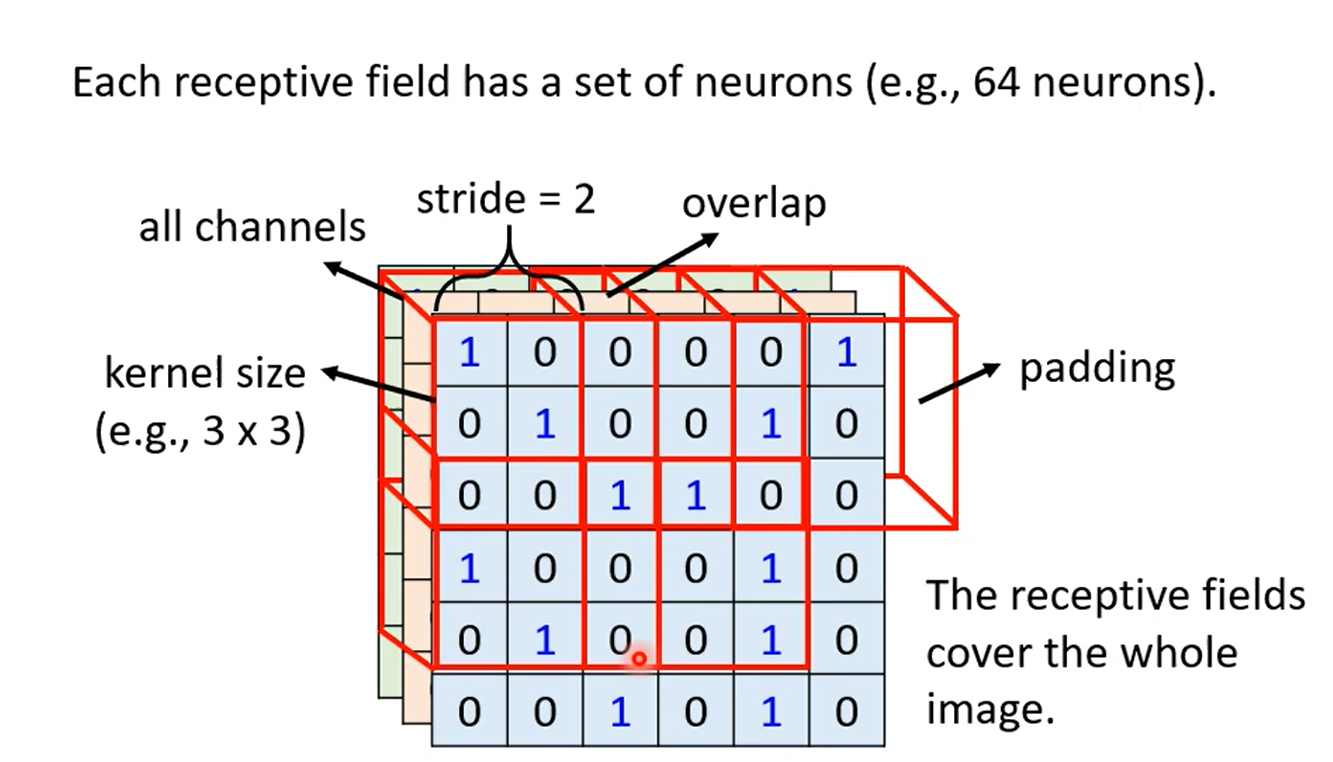
对于图像识别而言,同一个 pattern 的位置可能不同,Receptive Field 用于检测 pattern。
所以对于不同位置的 Receptive Field,可以共享参数(因为尽管这些 Receptive Field 在不同位置,但是它们在检测同一个 pattern)。
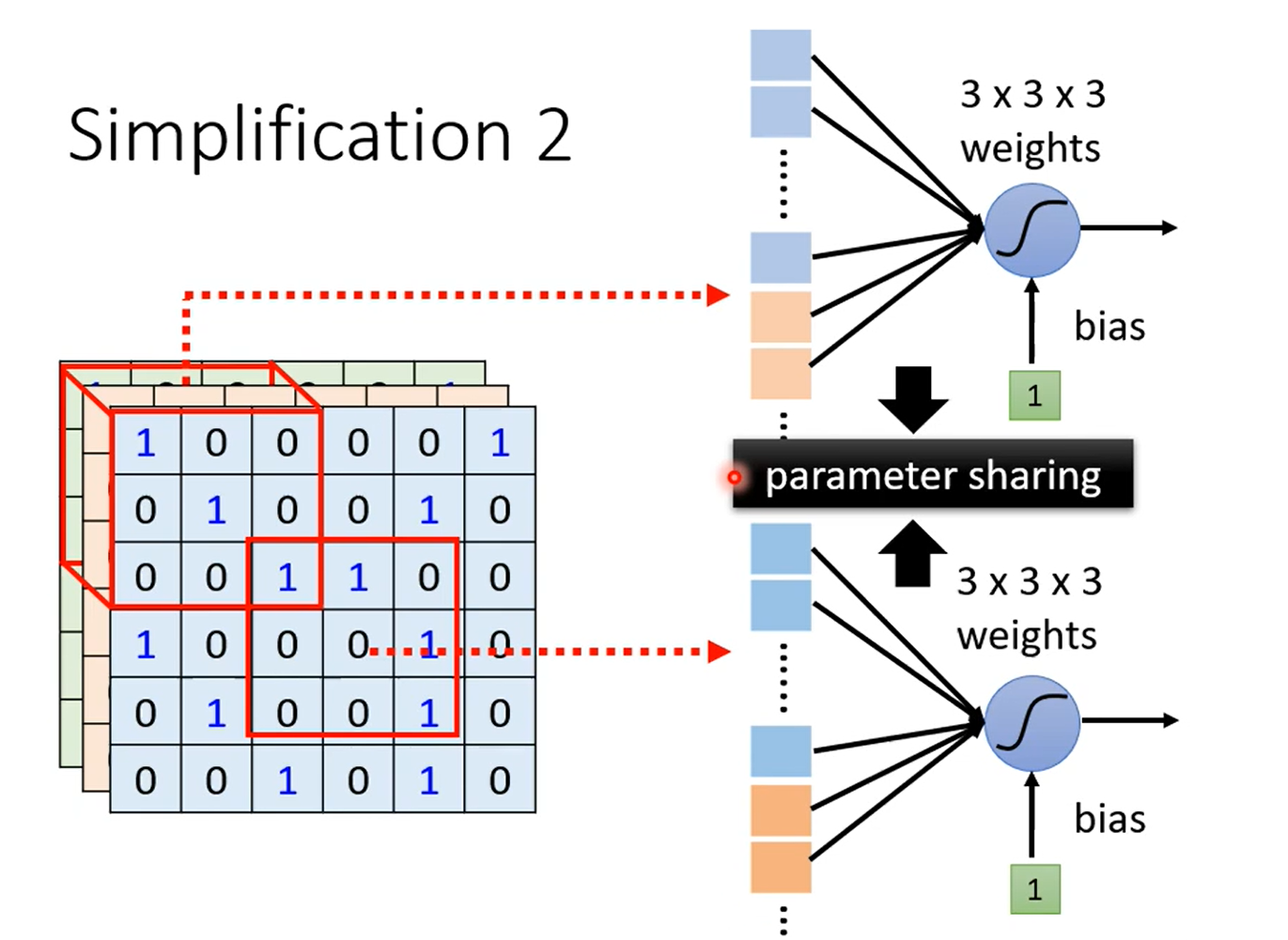
Respective Field + 参数共享 = Convolutional Layer(卷积层)。
卷积层中含有很多 filter(一个 filter 相当于一个 Respective Field,filter 中的参数相当于 Respective Field 送入神经网络单元的权重/参数)。
卷积层产生的输出称之为 Feature Map,这可以看作是一个新的图片,图片的 channel 等于 filter 的个数。
池化(Pooling)相当于缩小图片,在人类看来缩小图片,不会影响到 pattern 的检测。
如,Max Pooling:将图片分成多块,提取出每个块中最大的值。
在卷积和池化之后,将得到的结果(相比于原始图片小了很多)送入全连接神经网络,就得到了完整的 CNN 网络。
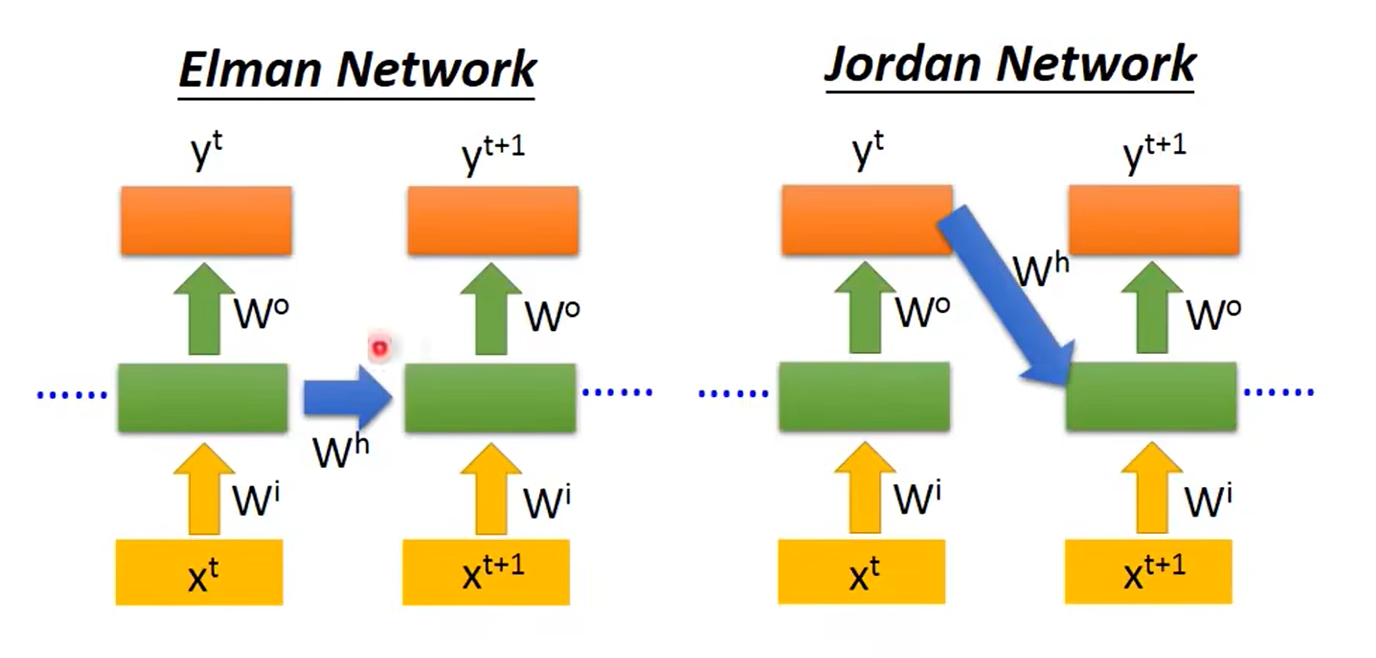
RNN 中,会将上一次输入的产生的东西保存下来,作为本次的一个输入。
分为 Elman Network 和 Jordan Network:
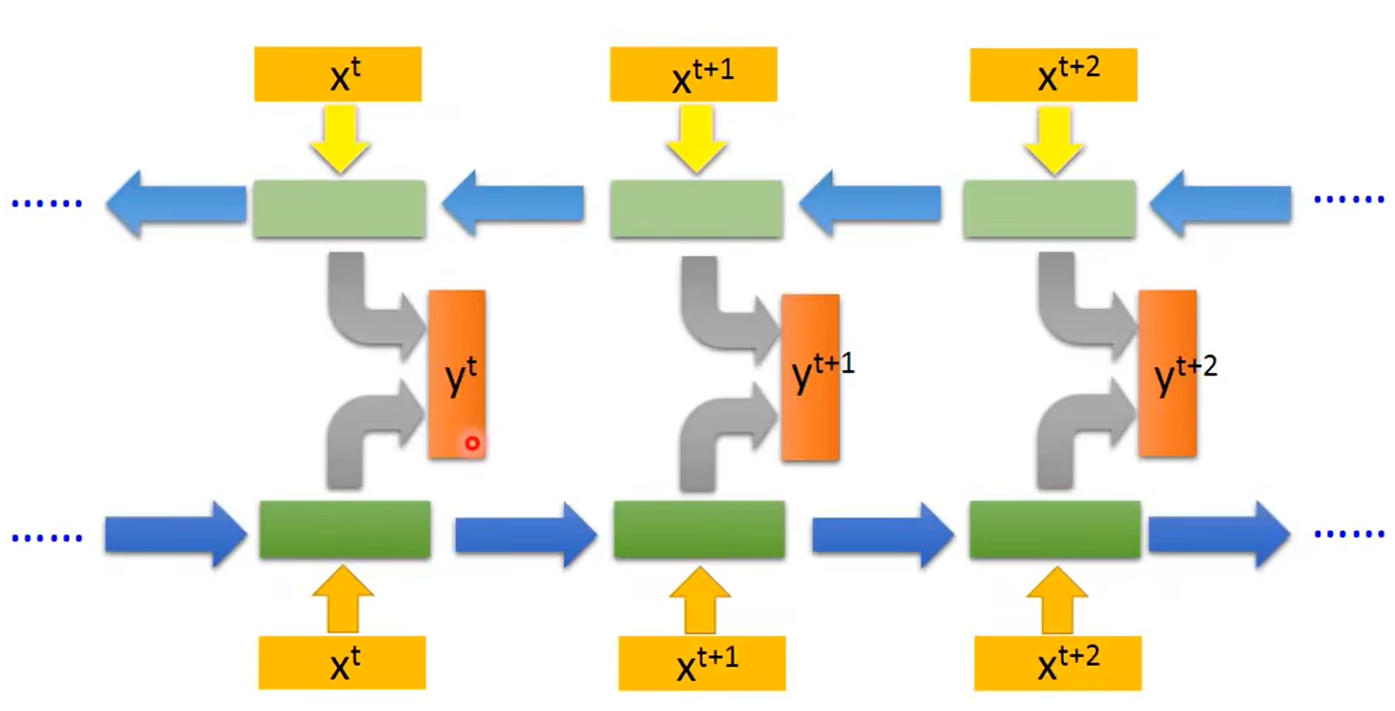
RNN 可以是双向的,训练一个正向 RNN 和一个逆向 RNN,将正向和逆向的输出合并起来进行输出。
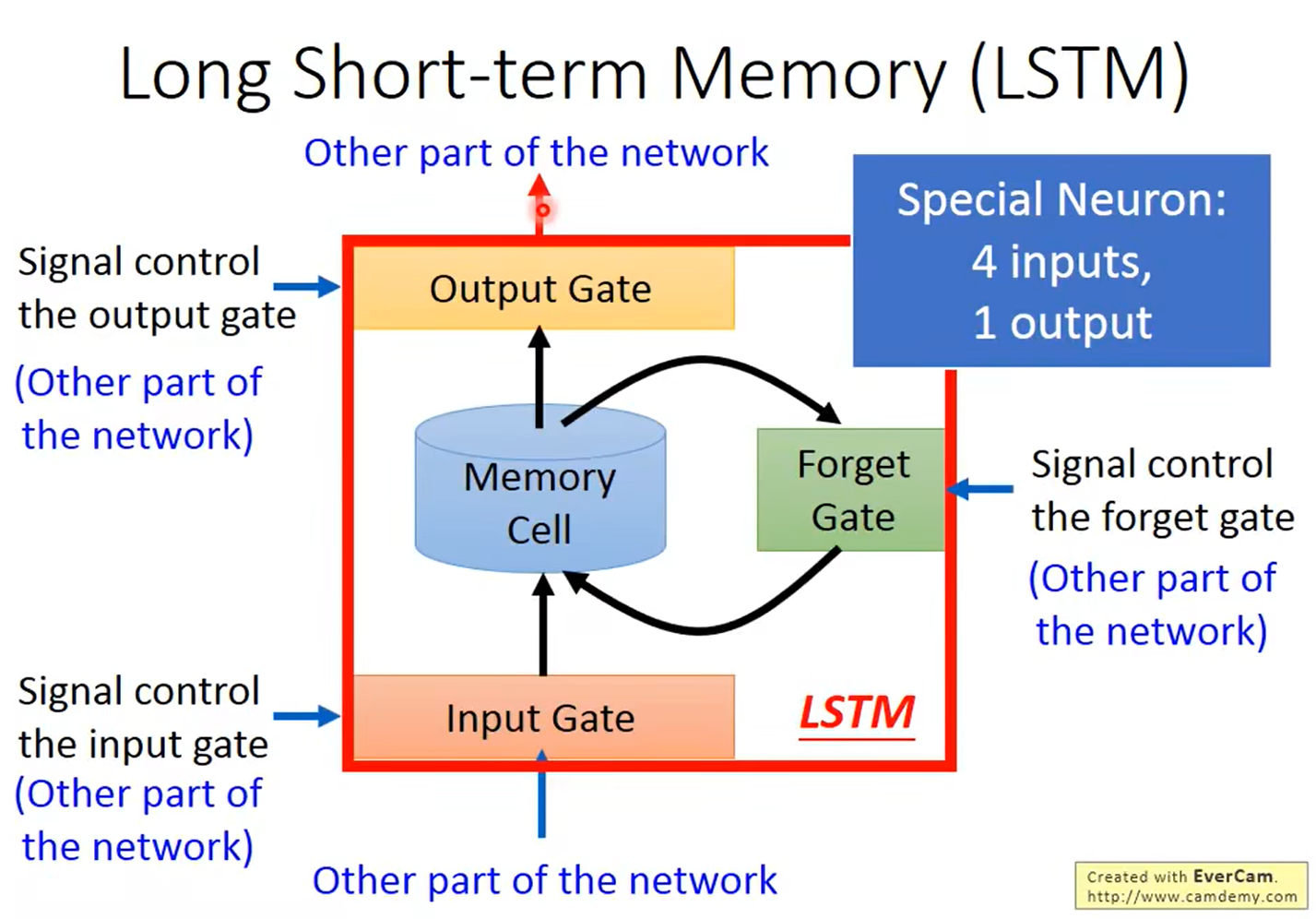
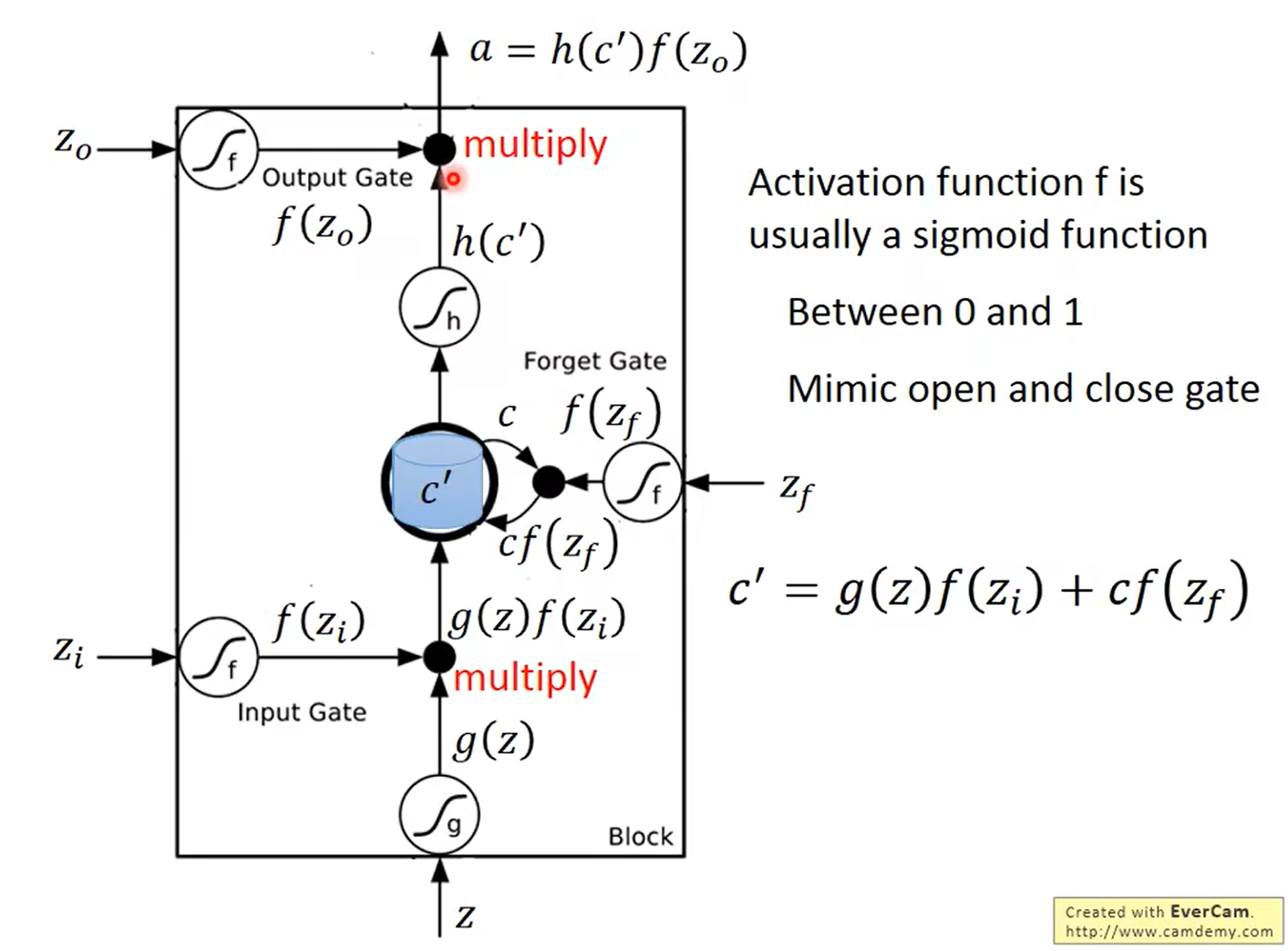
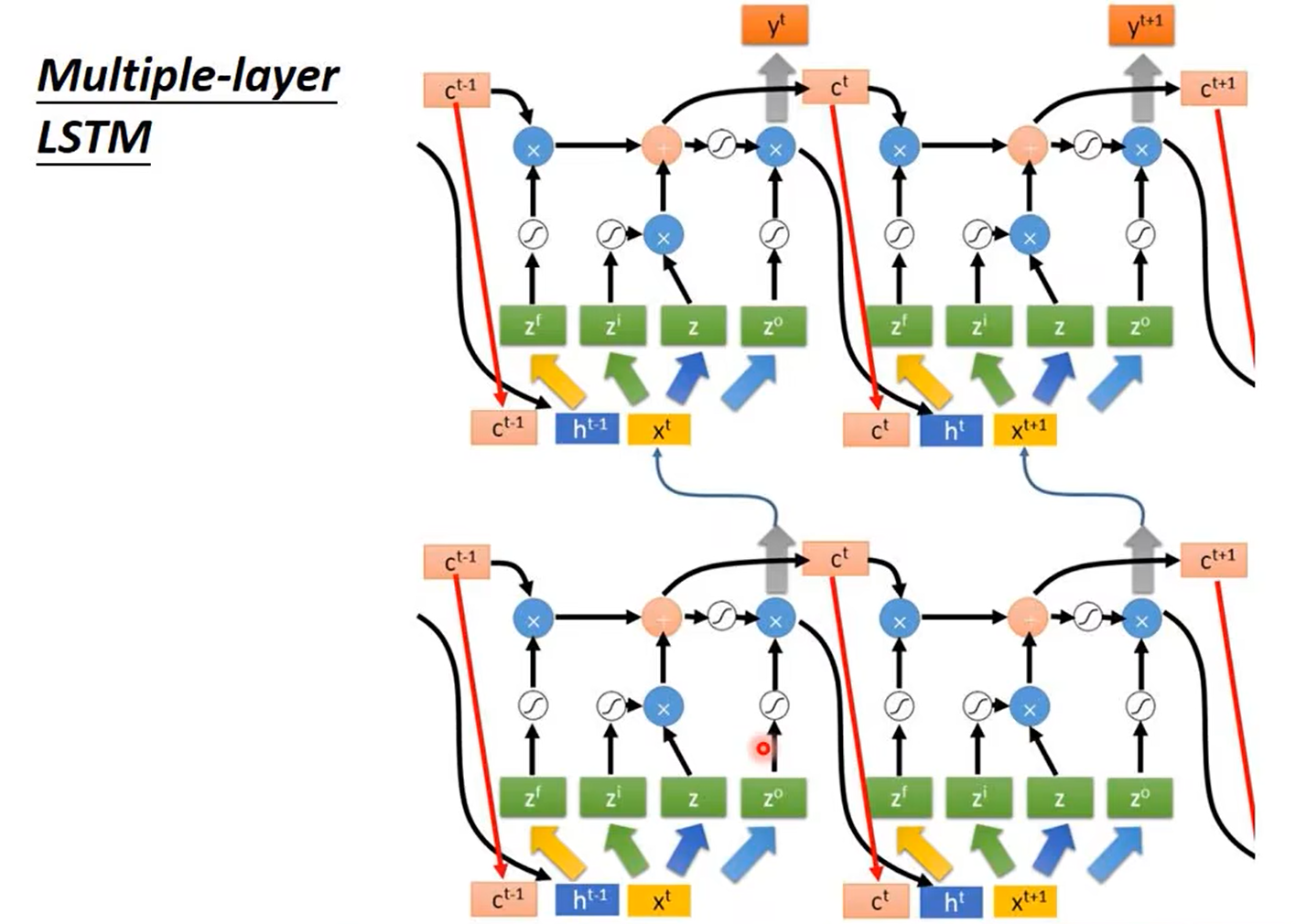
LSTM(Long Short-term Memory)
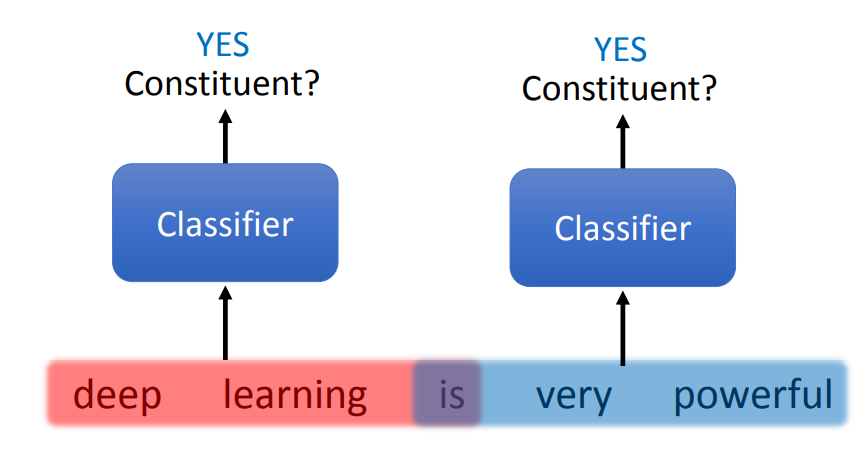
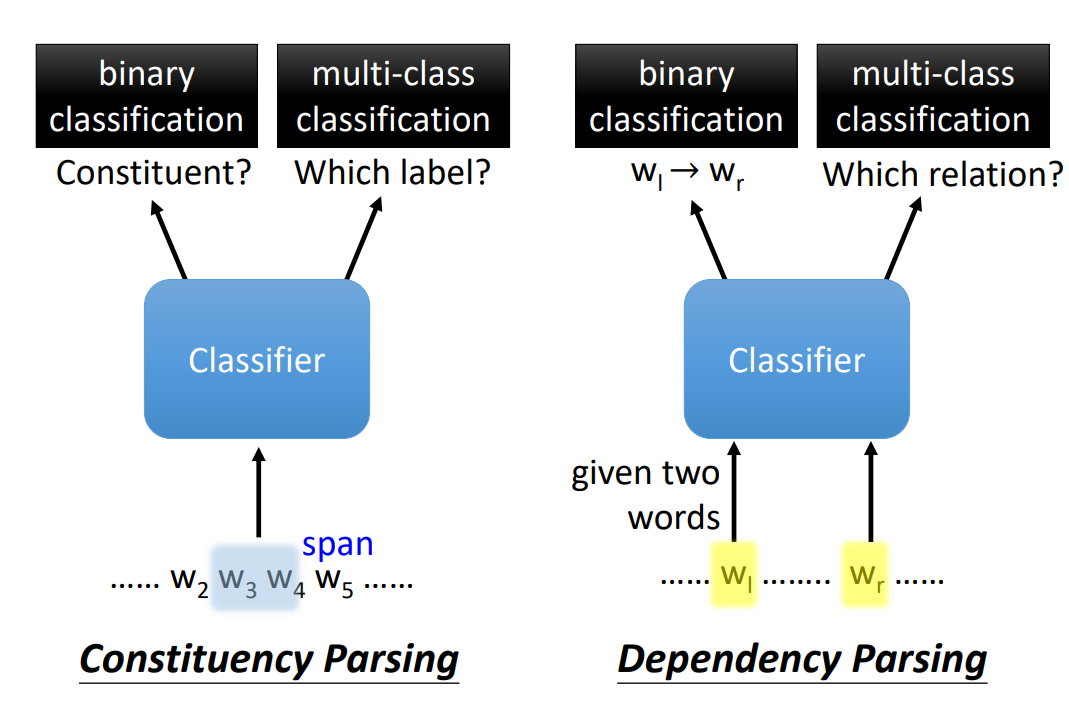
Constituency Parsing 就是:
找出一段 text span 作为 constituents
每一个 constituents 都有一个标签

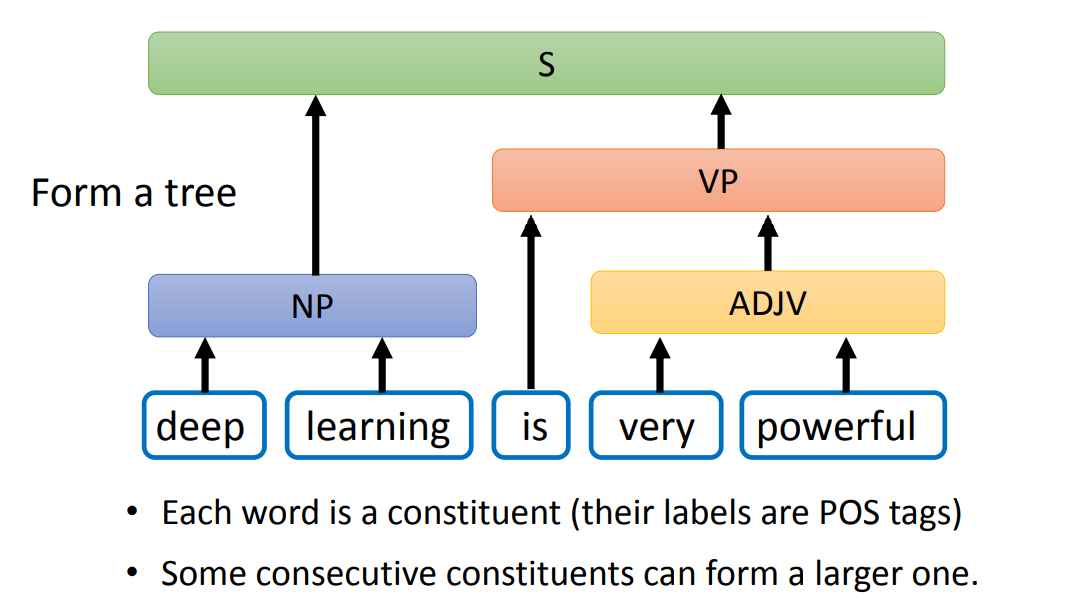
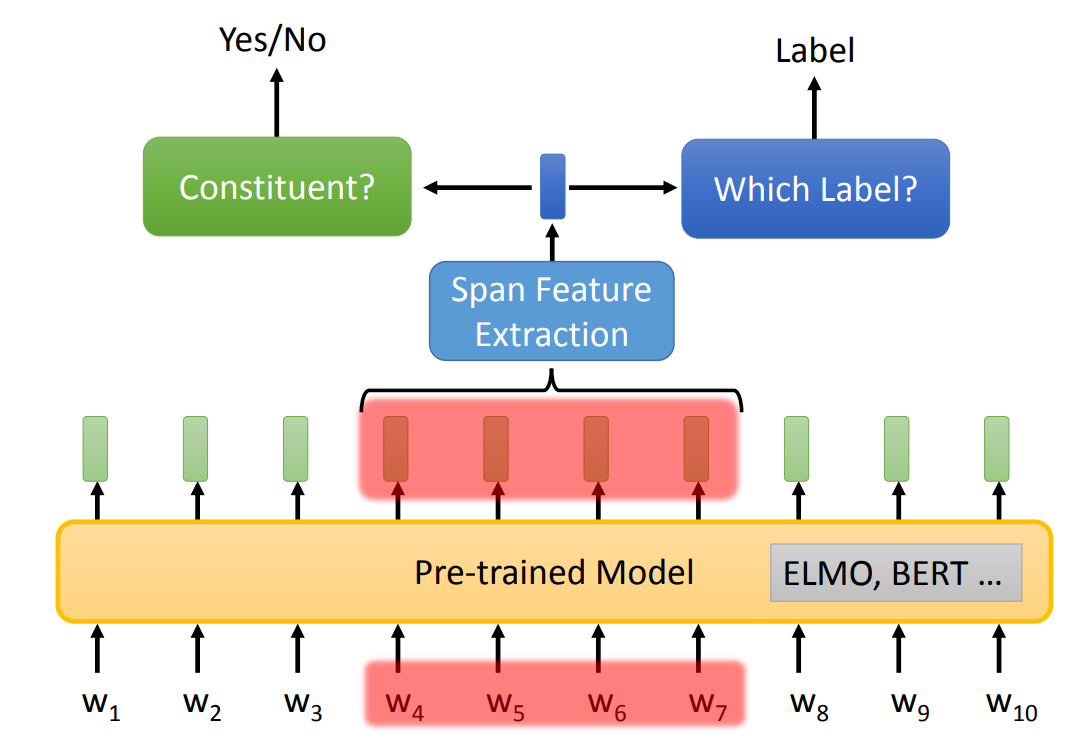
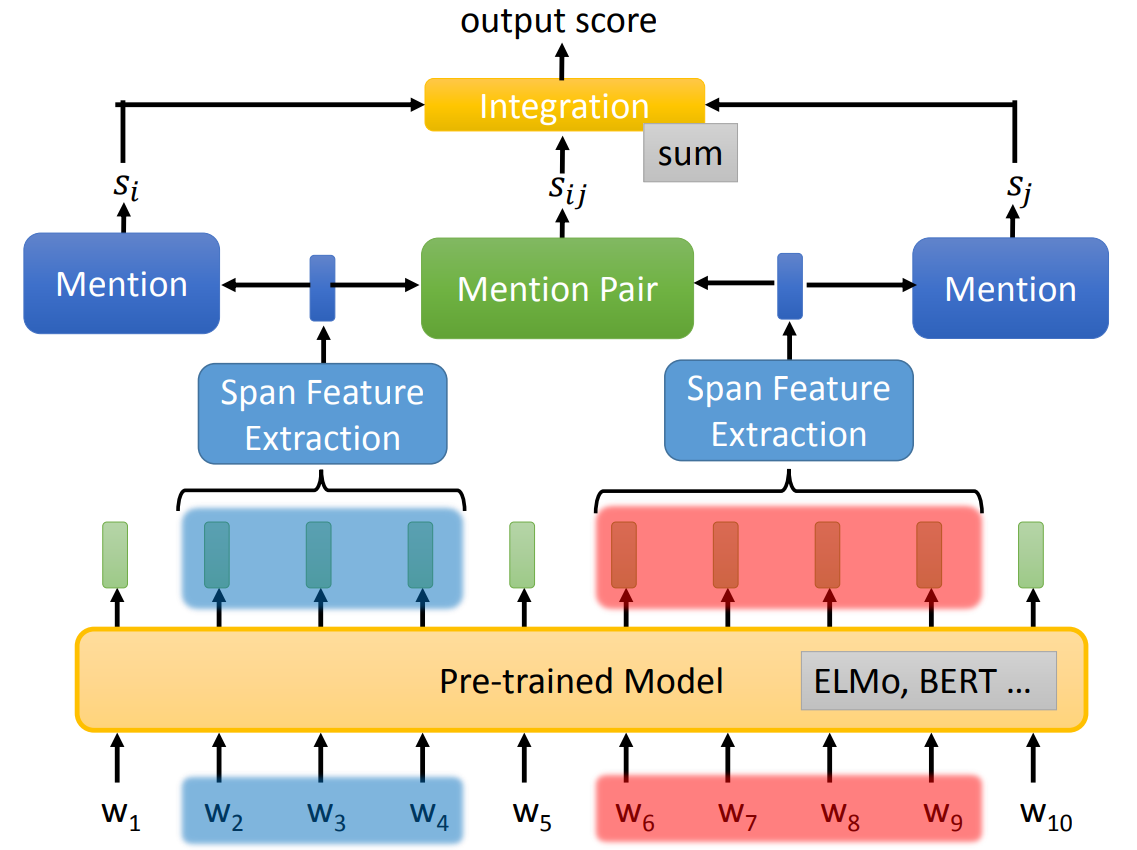
Chart-based 方法实际上就是对每一个 span 进行两次分类:
下图是 Chart-based 的结构,其中 Span Feature Extraction 与 Coreference Resolution 中的一样。
需要注意的是,对于 span 的选择可能会产生矛盾,比如两个重合的 span 都被判断出是 constituent,那么就无法组成一棵树。
解决方法就是,穷举出所有可能性的树,然后对每一棵树进行评分,选取评分最高的树。
Transition-based 中由三个部分组成:

实际上,我们需要训练一个分类模型,用于输出 Actions。
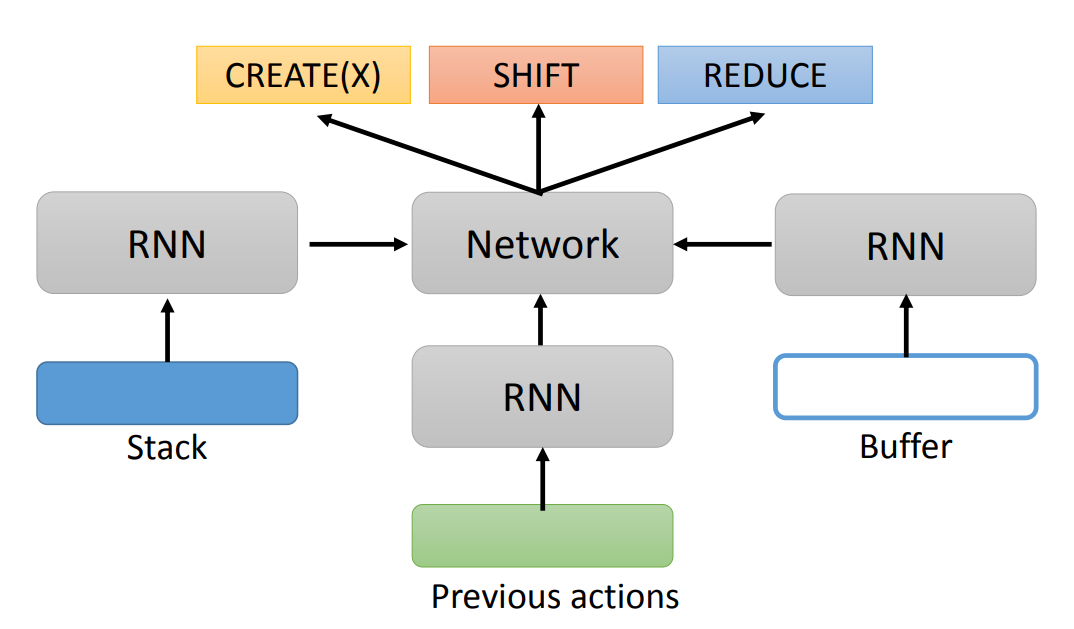
甚至,我们可以利用 Seq2seq Model,将语法树变为一个 Sequence,比如:
对树进行遍历,得到遍历序列,这个遍历序列就是 Sequence。需要注意的是,这个模型不需要输出单词(因为可能会改变输入的句子),可以用 XX 表示输入的一个单词。
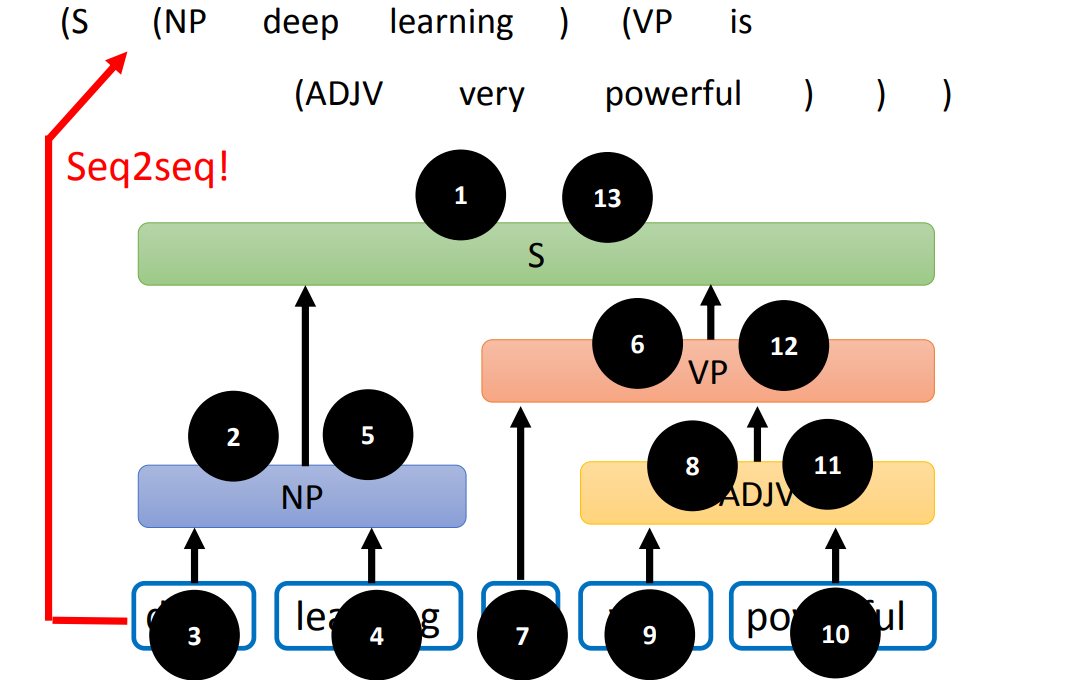
Constituency Parsing 考虑的是一个句子中,相邻单词的关系。
Dependency Parsing 考虑的是任意两个单词(不需要相邻)的关系,用箭头表示这种关系(标签为关系的类别),起始为 head,结束为 dependent。
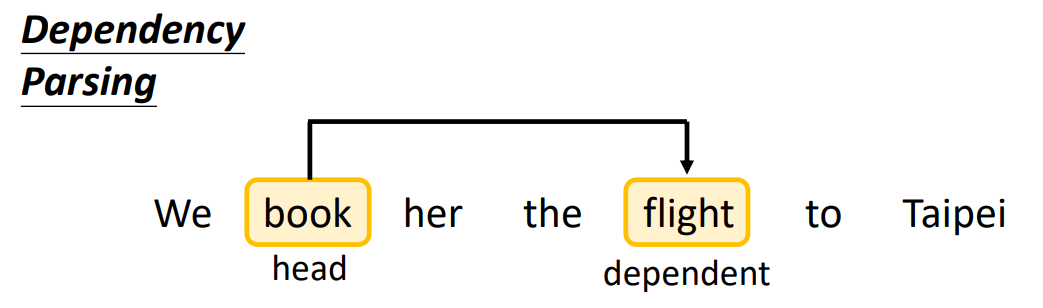
Dependency Parsing就是将一句话变为有向图(Directed Graph,实际上也是一棵树),word 变为 node,关系变为 edge。
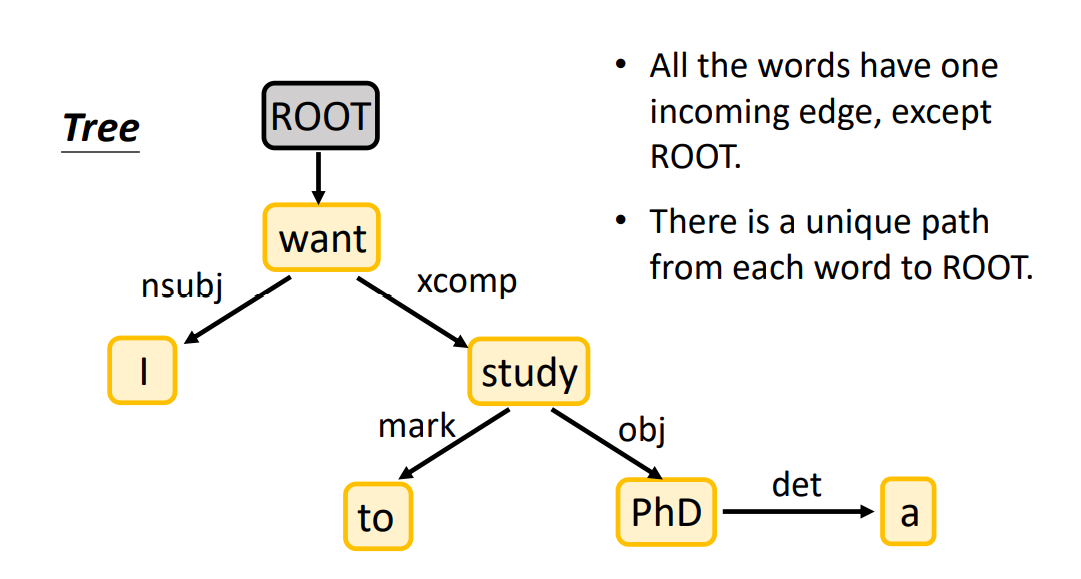
核心方法就是:两个分类器,输入是两个 word。
将各个向量放入 Self-Attention(可以使用多次) 中,得到与整个句子都相关的另外的向量。
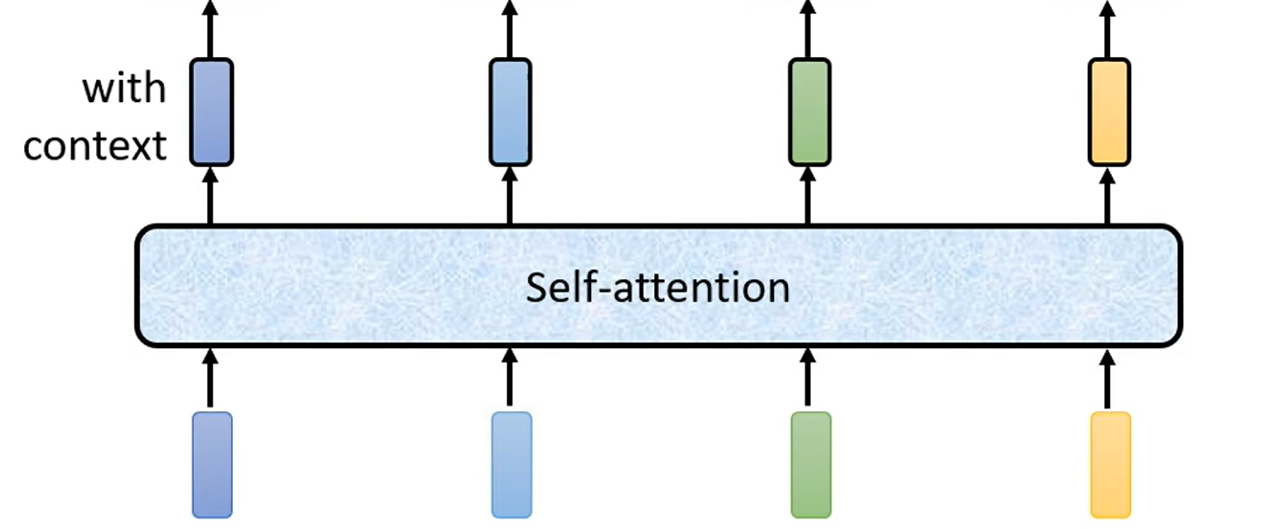
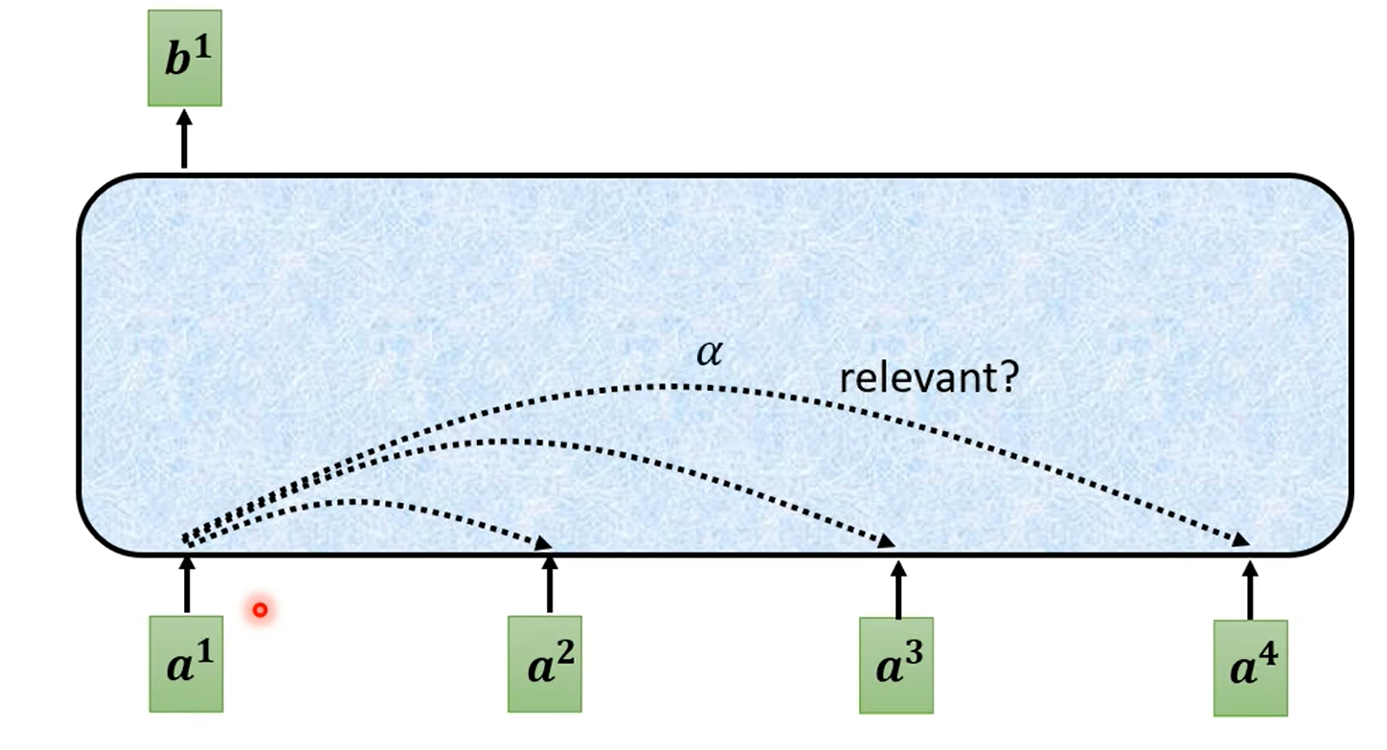
Self-Attention 层,输入一些向量,输出另一些向量。每一个输出的向量与输入的向量都有关系。
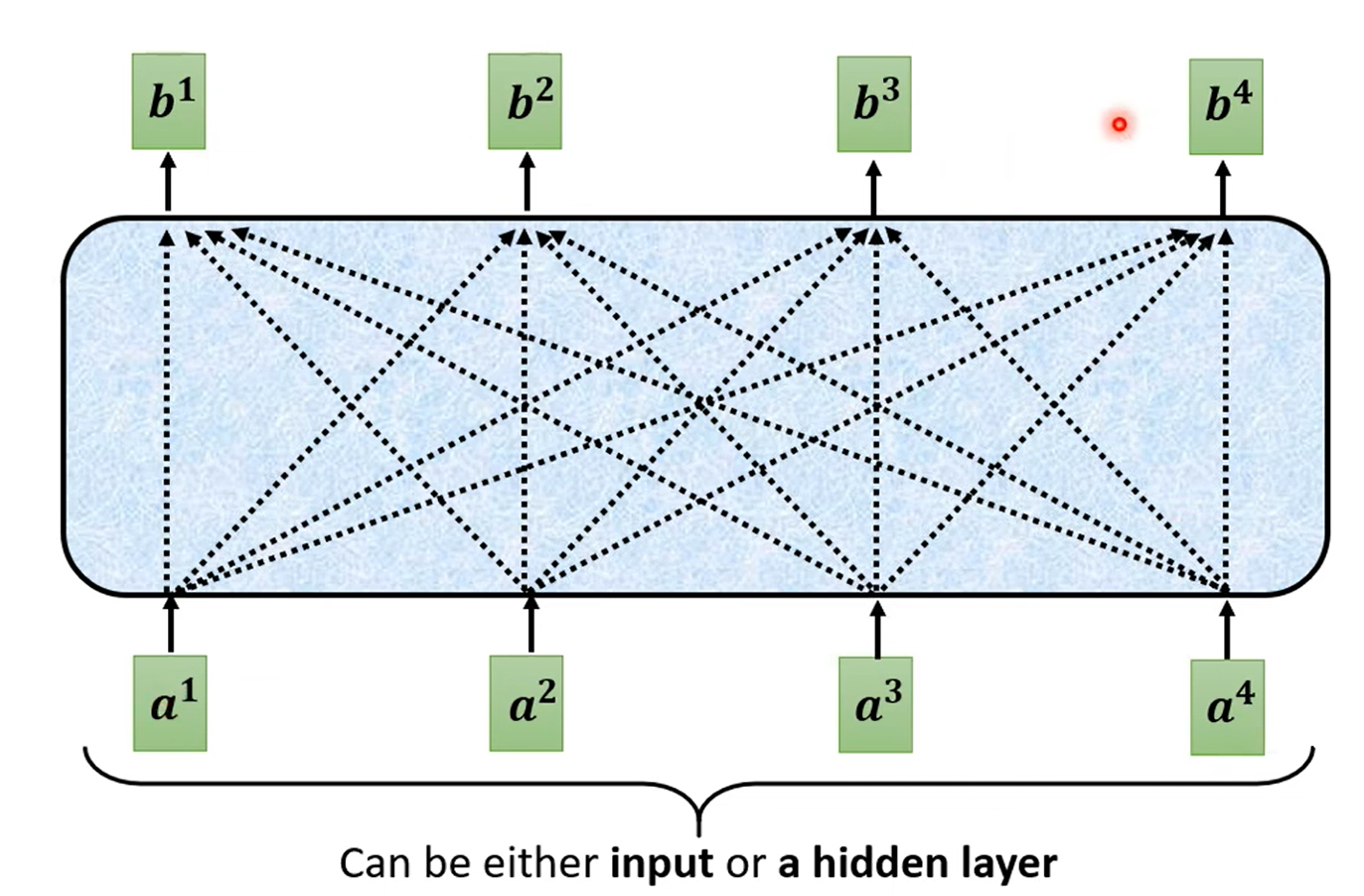
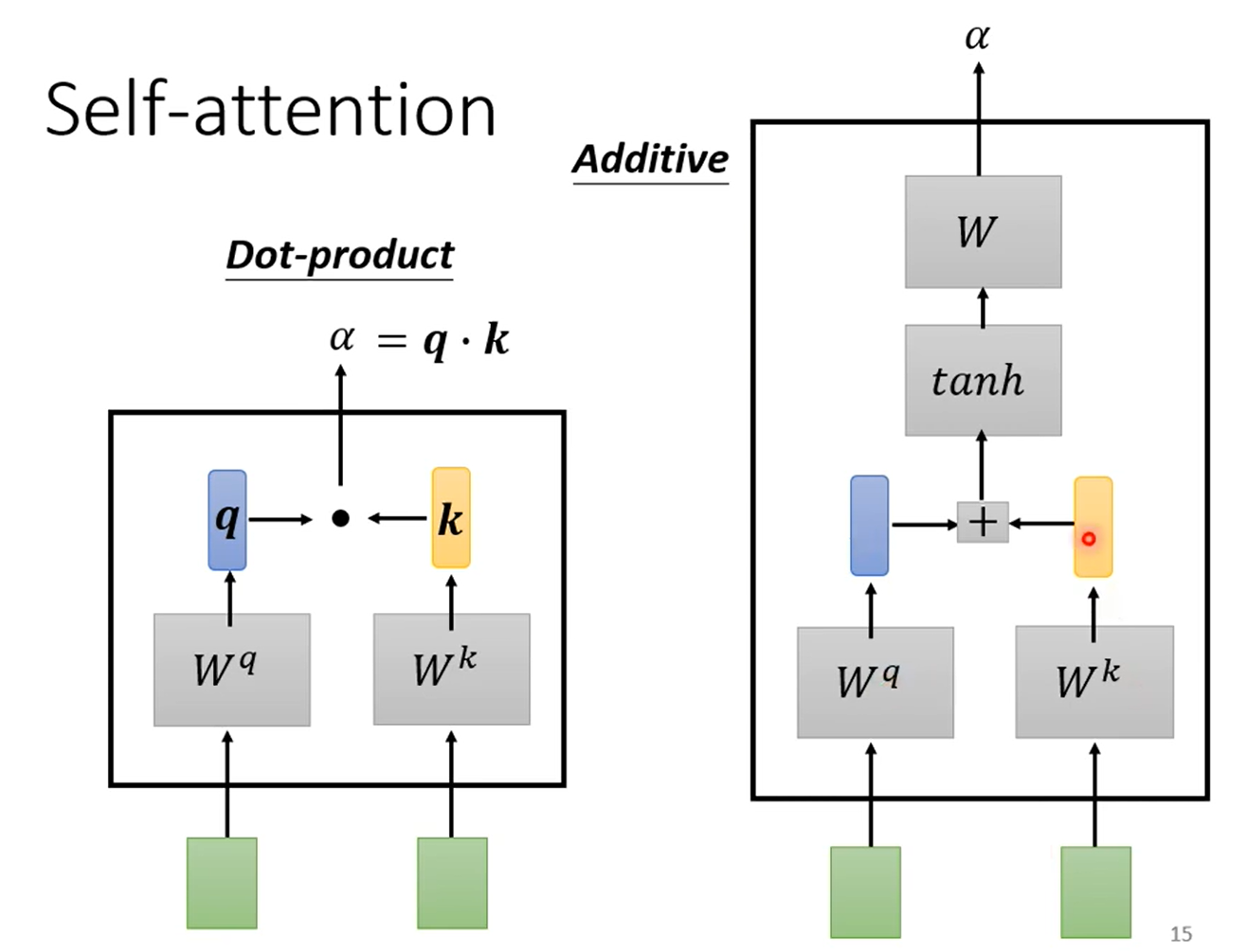
对于如何输出一个向量,实际上是看其他向量是否对应的输入有关系(relevant)。这里的有关系的程度用 α 表示:
对于如何计算 α,有两种方式:
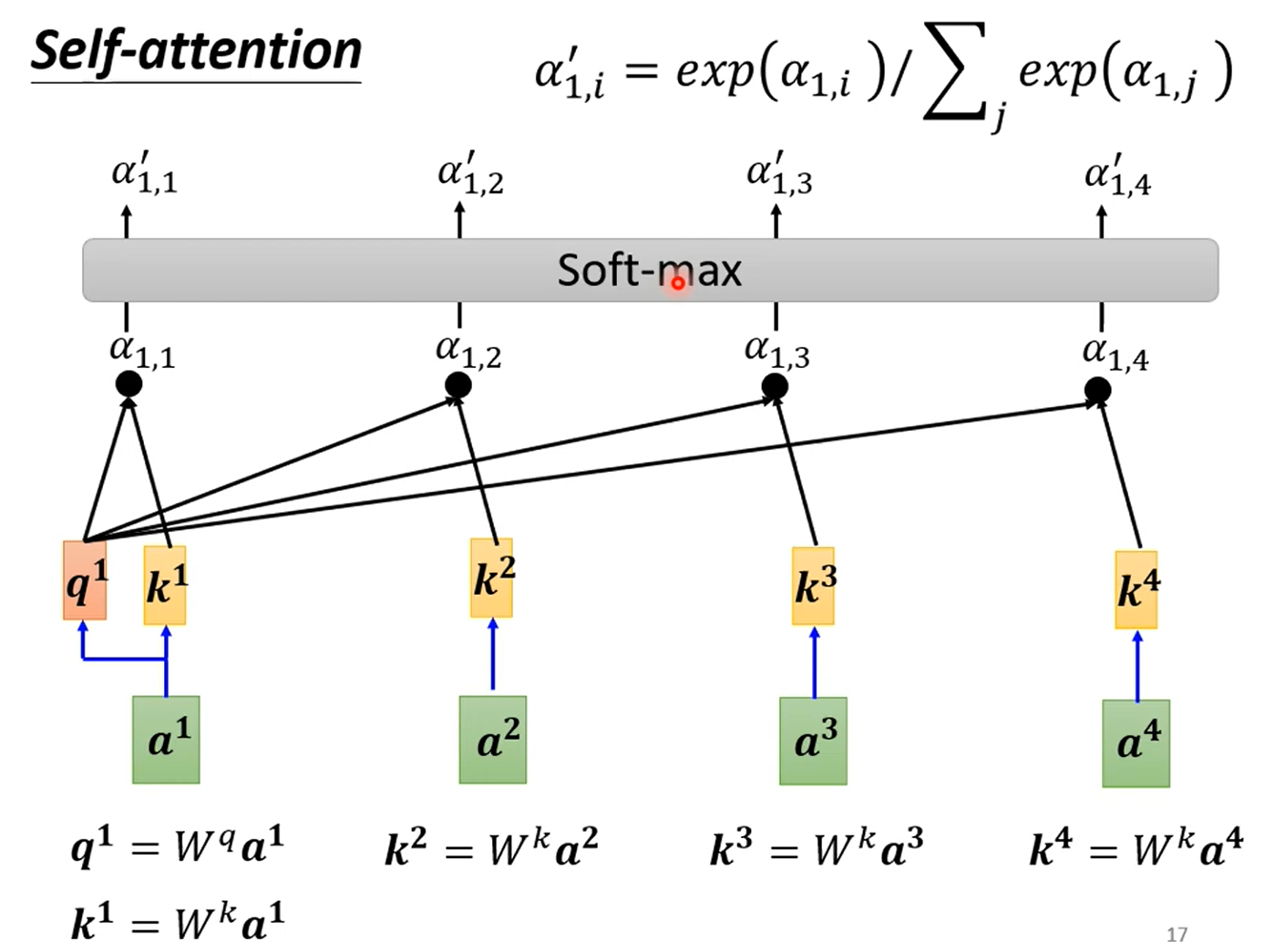
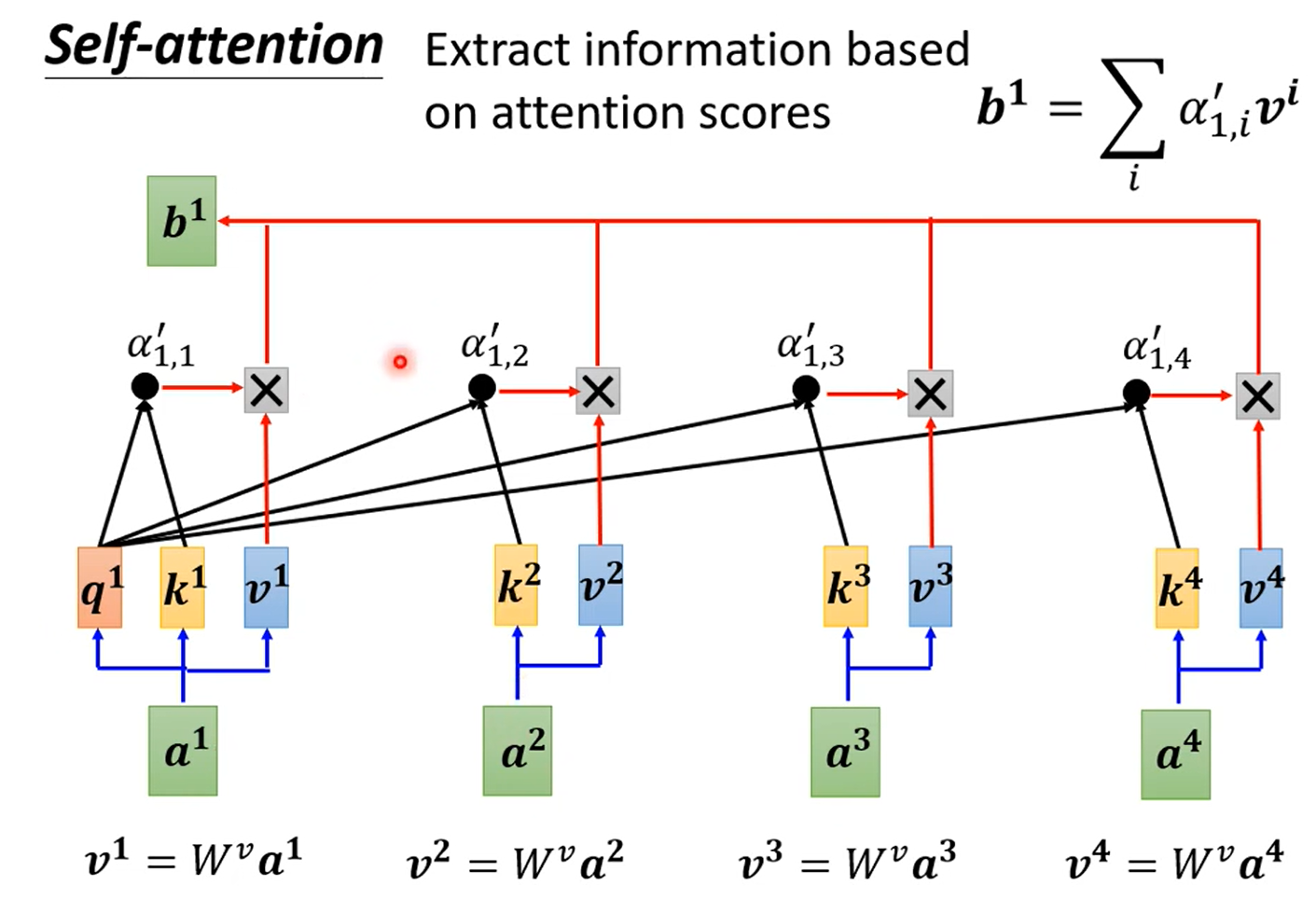
这是 Self-Attention 的变形,用于计算不同种类的相关性。
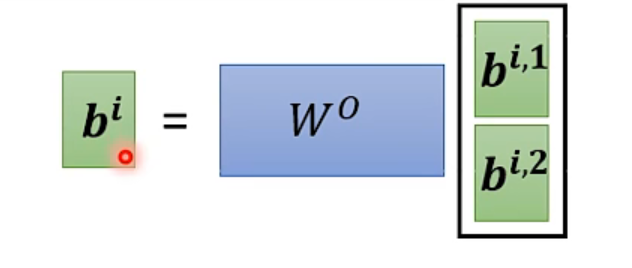
最大的不同就是 q、k、v 三种向量乘以多个矩阵(矩阵的个数就是 head 的数量,即种数)得到不同的种类,每一种单独 Attention 得到每一种对应的输出。
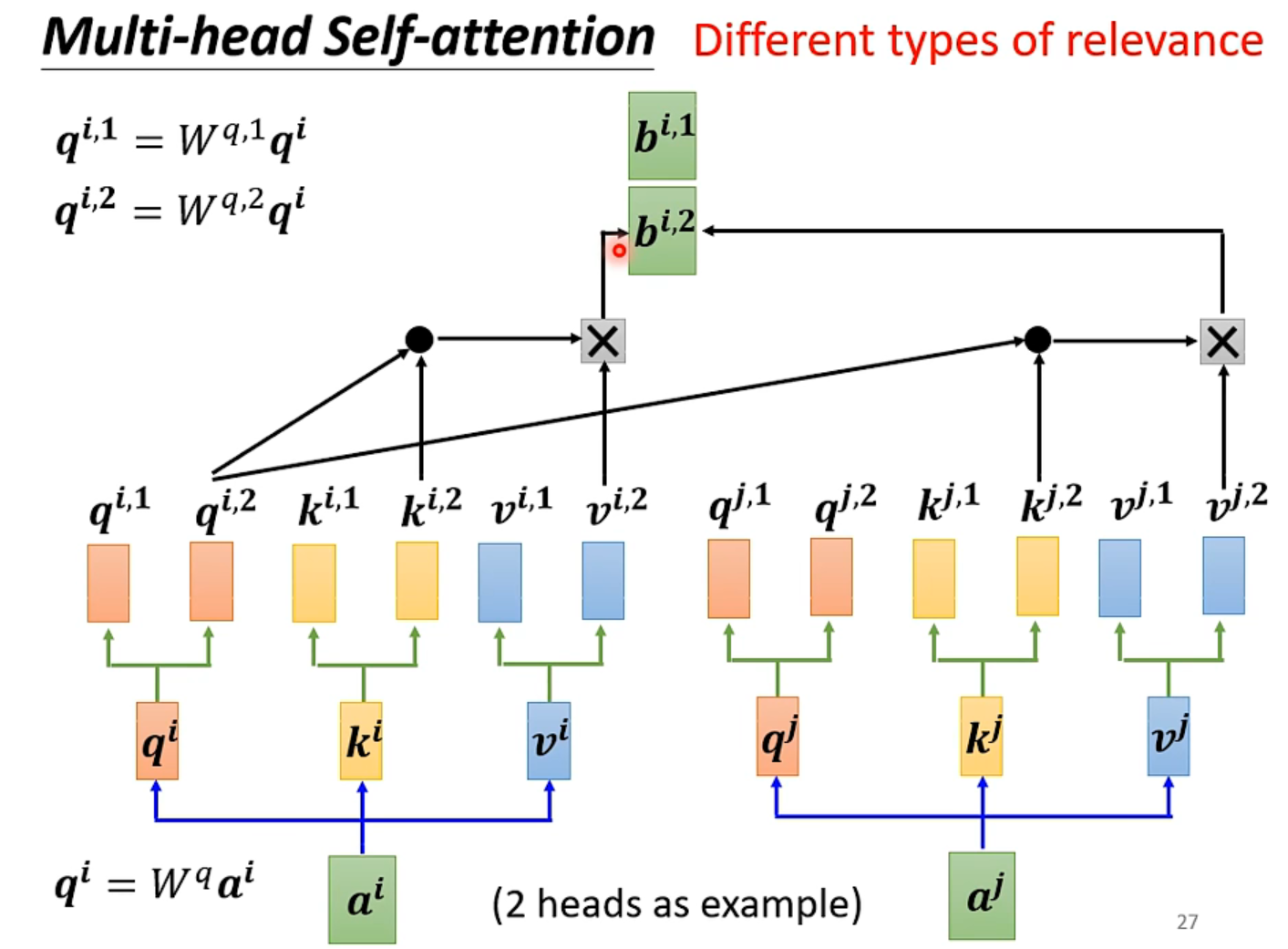
最后将每一种输出乘以一个矩阵,得到最终的输出。
上述的 Self-Attention 中,是没有位置信息的。若需要位置信息,则需要 Positional Encoding。具有工作如下:
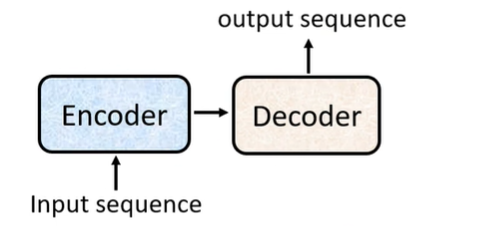
Transformer 是一种 Seq2seq Model(输入一个 sequence,输出一个 sequence)。
Seq2seq Model 的结构包括一个 Encoder 和一个 Decoder。
Encoder 输入一排向量,输出另外一排向量。
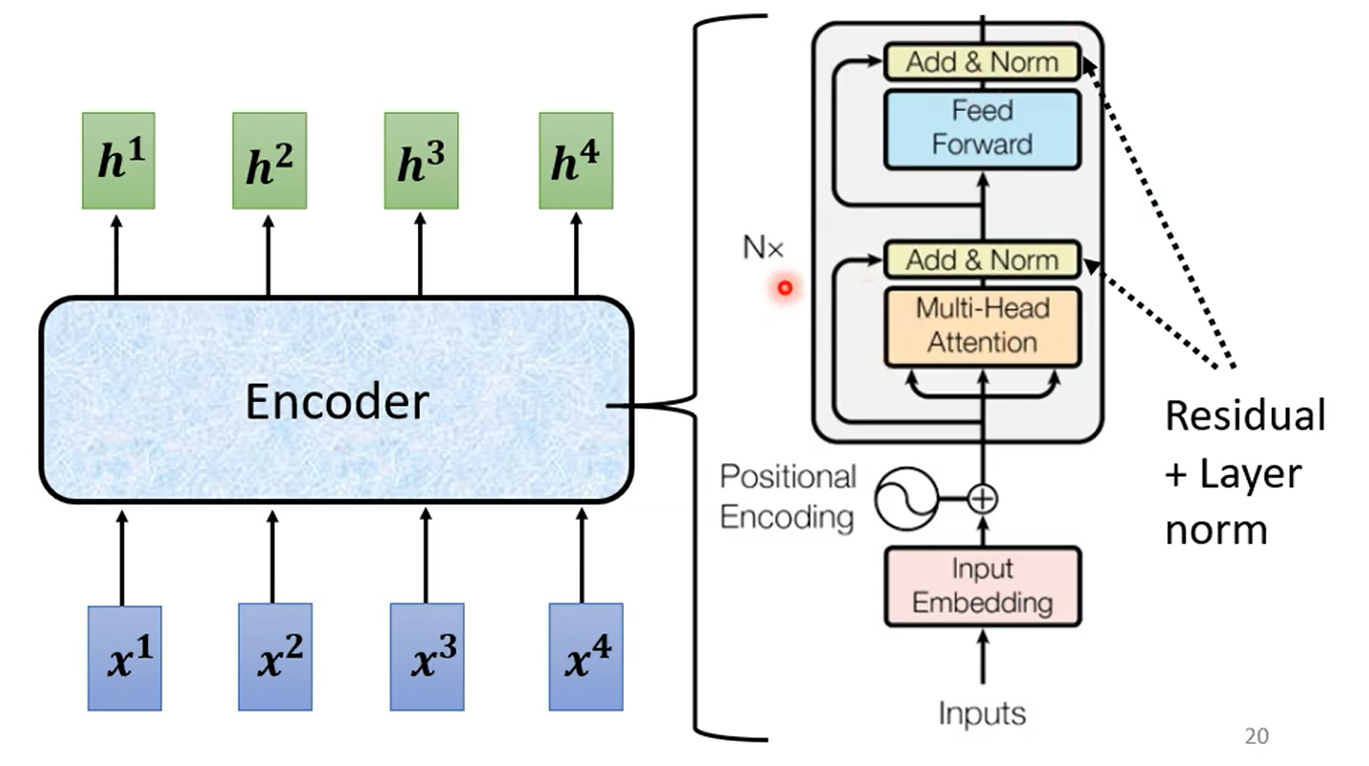
其中 Encoder 是 N 个 block 的重复,每一个 block 的结构如下:
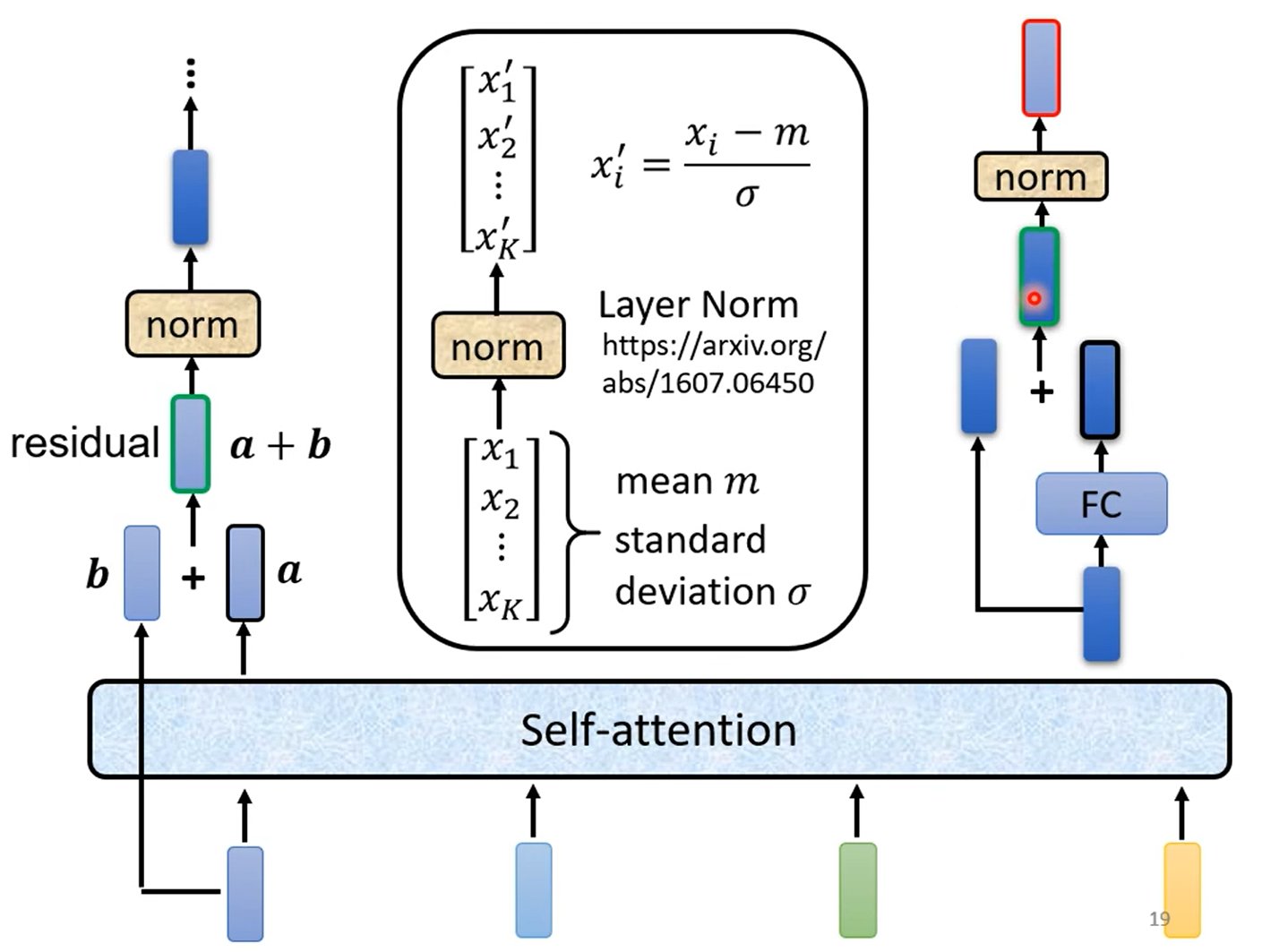
Autoregressive 就是在输出时,从左到右依次输出。其最显著的特点就是,每一个 Decoder 的输出作为下一次 Decoder 的输入。
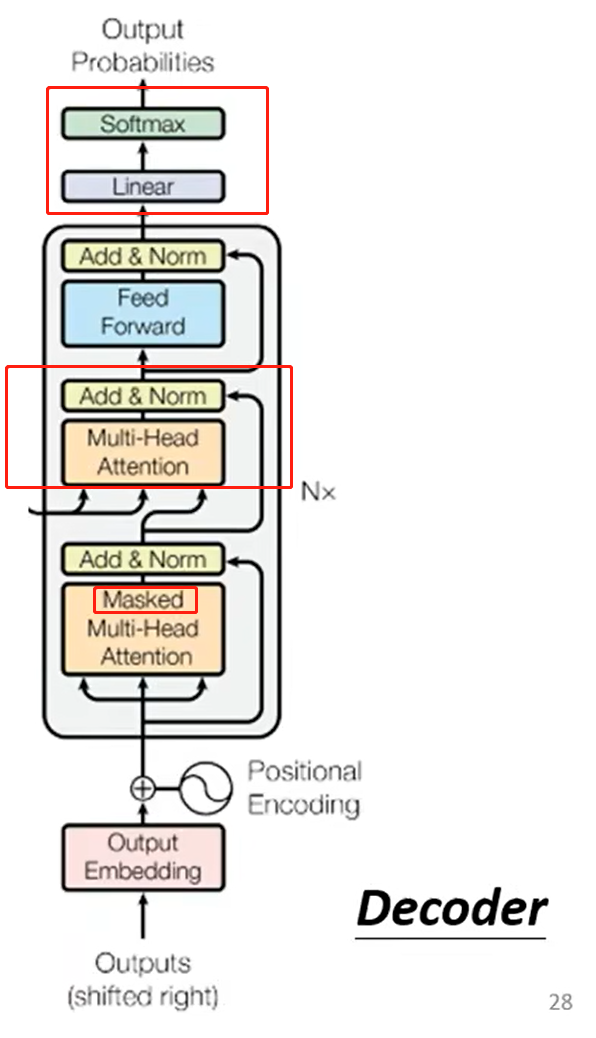
Decoder 和 Encoder 的结构比较类似,区别在于:

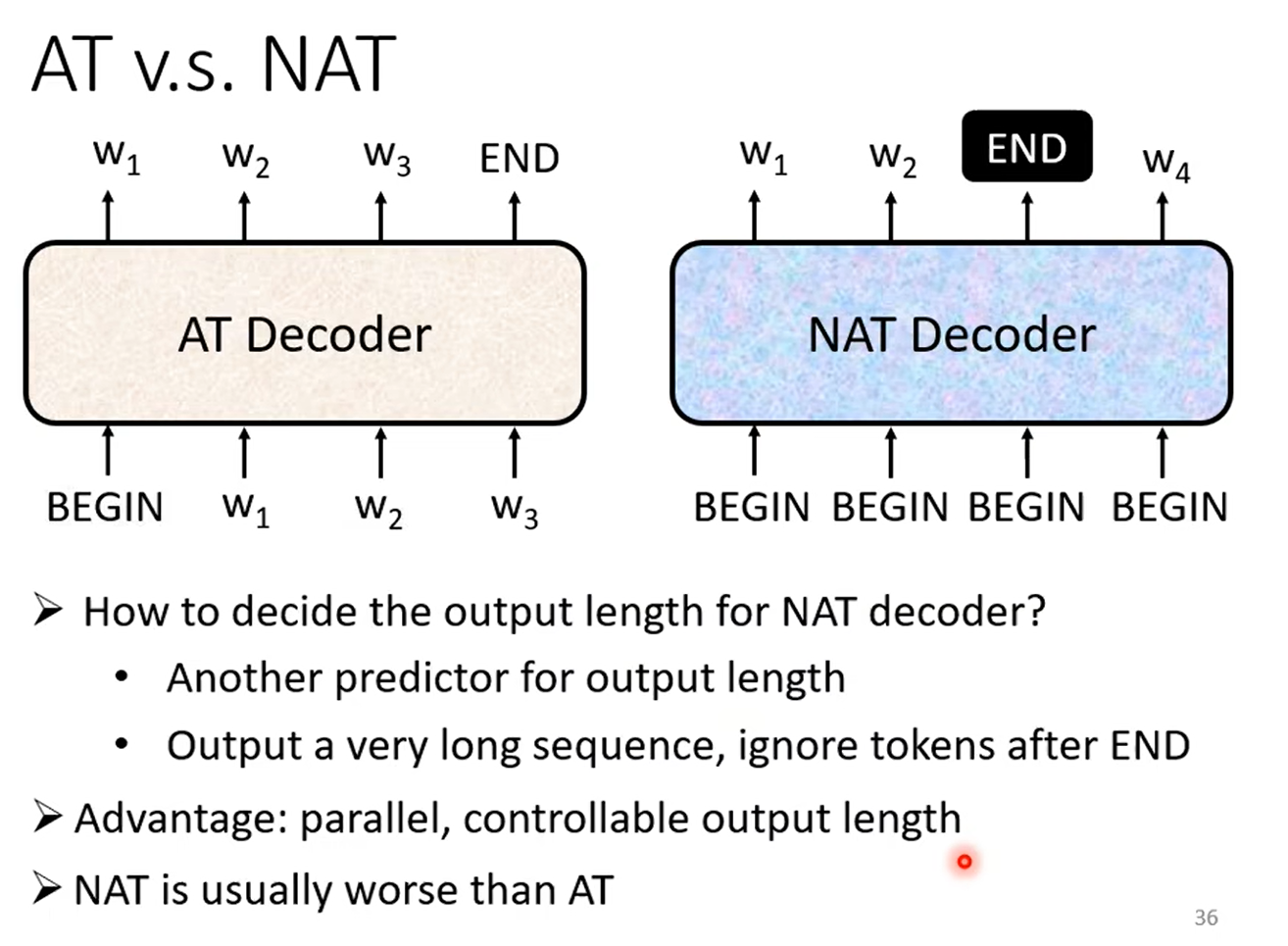
AT 和 NAT 的比较:
实际上,Decoder 中多出的一层 Multi-Head Attention 和 Add & Norm,就是用于连接 Encoder 和 Decoder。
这一部分被称为 Cross Attention。
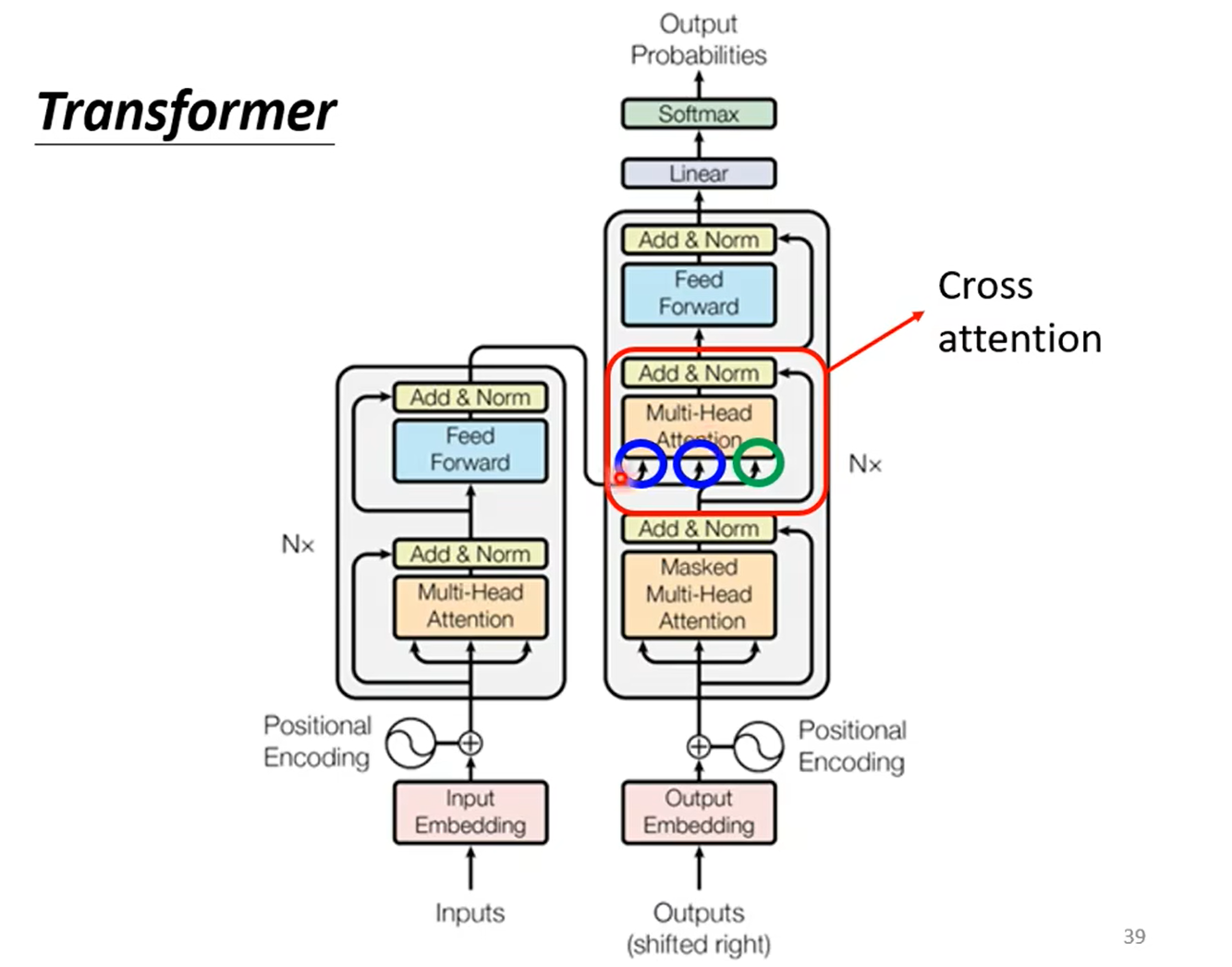
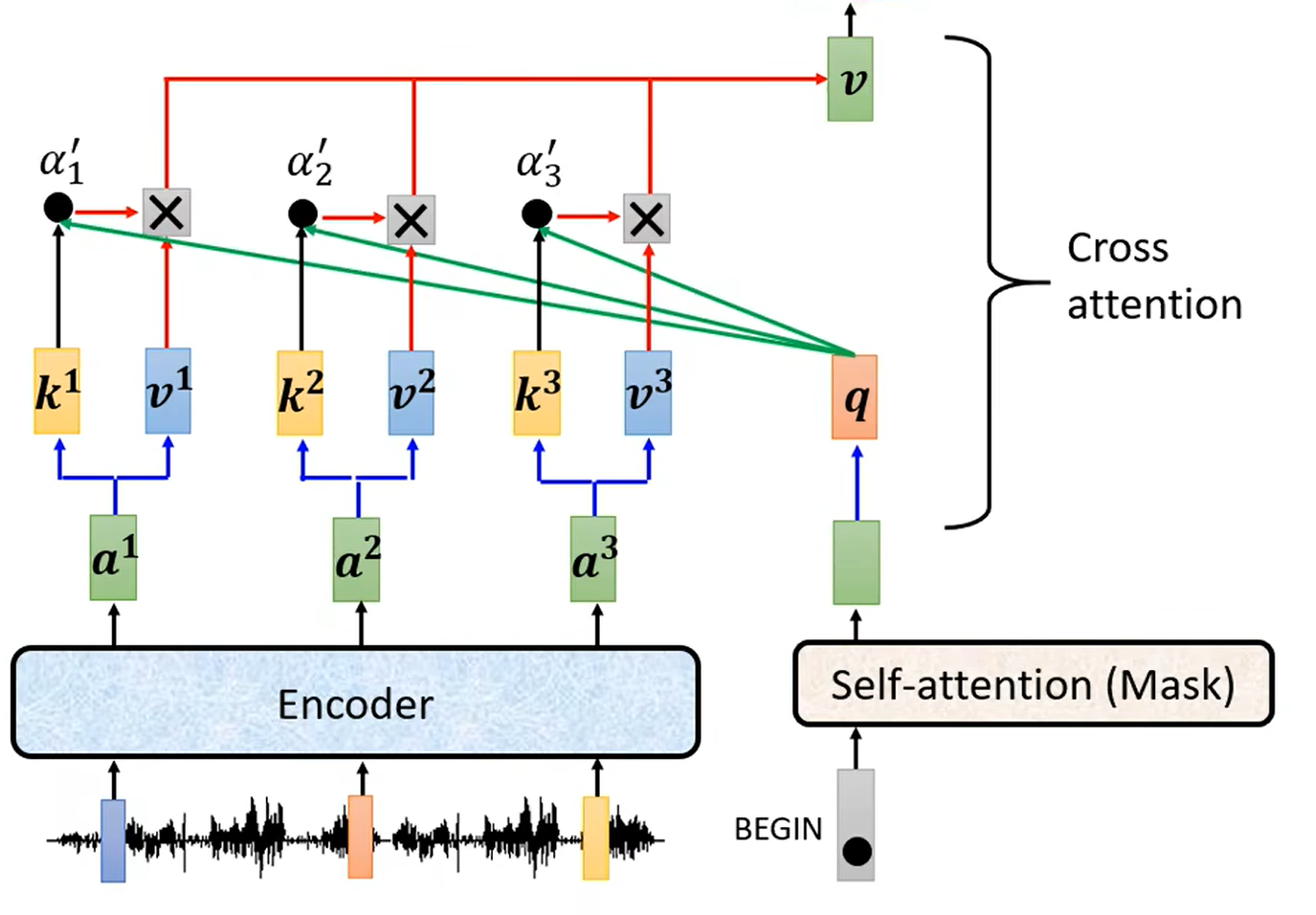
Cross Attention 的详细结构如下,计算 Decoder 中 Masked Multi-Head Attention 的输出向量与 Encoder 的输出之间的相关性(Attention)。
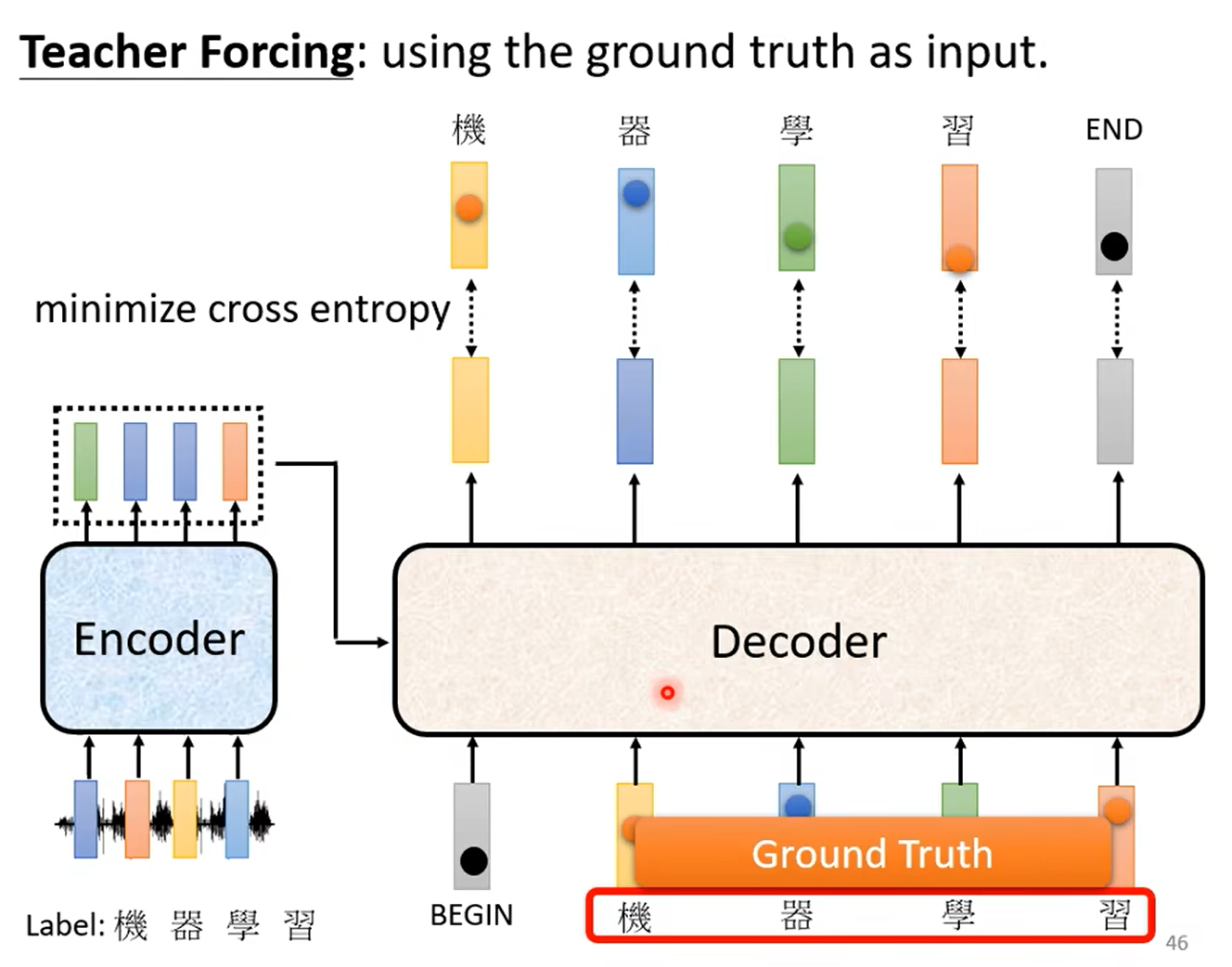
训练时,采用强制学习(Teacher Forcing):每一次向 Decoder 的输入并不是上一次 Decoder 的输出,而是正确的结果。
Coreference Resolution,即代指消解,识别出代指的相同的东西。
需要识别出代指的一段文字(如他、它的 XX 等),称为 mention。代指消解的结果就是将同一个代指的 mention,放入同一个 cluster 中。
N(N-1)/2 次。
K(K-1)/2 次。
或者可以直接输入两个 span 到二分类器中,判断这两个 span 是否代指同一个实体。若有 N 个 token,则有 K=N(N-1)/2 个 span,需要运行 K(K-1)/2 次。
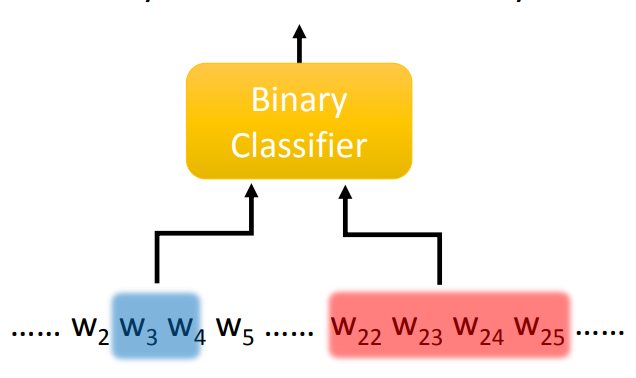
一个通常的用于 Coreference Resolution 二分类器如下:
将句子中的所有 token 输入预训练模型中,得到 embedding。
将 embedding span 输入 Span Feature Extraction,得到两个向量(每一个 Span Feature Extraction 将 embedding 汇聚成一个 embedding)。
判断两个向量是否是 mention、是否属于同一个 cluster,最终输出一个分数。
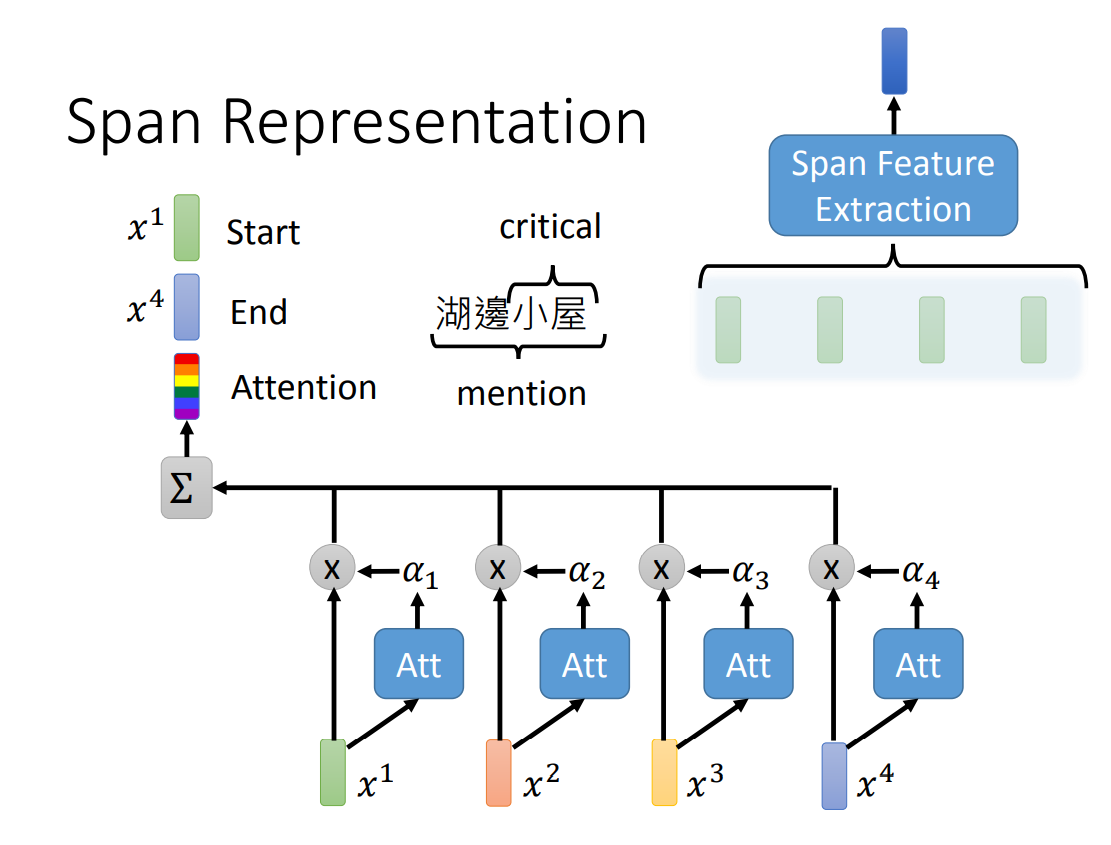
对于 Span Feature Extraction,结构如下。将 embedding span 进行 Attention,得到一个 Attention 向量,再把 span 中起始 embedding 和最后一个 embedding 与 Attention 向量相加,得到 Span Feature Extraction 的输出向量。
上述是有监督模型,那么是否可以训练一个无监督模型呢?
答案是可以的,把 mention Mask 起来,这样模型的输出就是相关的代指实体。

Go 中,内存分配主要有两个思想:
分块的思路为:
mmap() 向 OS 申请一大块内存,例如 4MB。缓存的基本思路是:
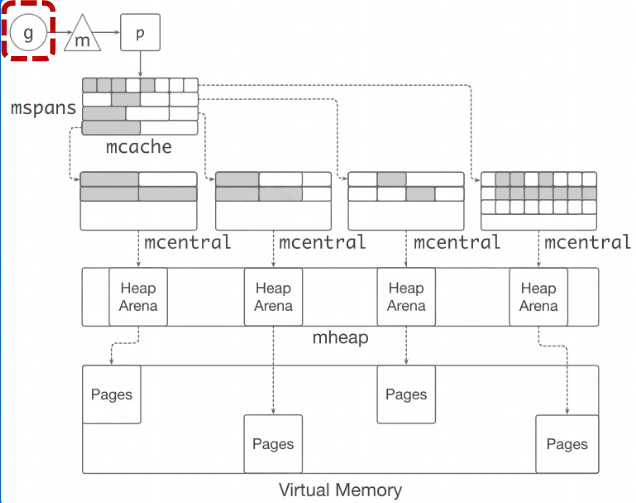
字节跳动有自己的 Go 语言内存管理优化方案,即 Balanced GC,其思路如下:
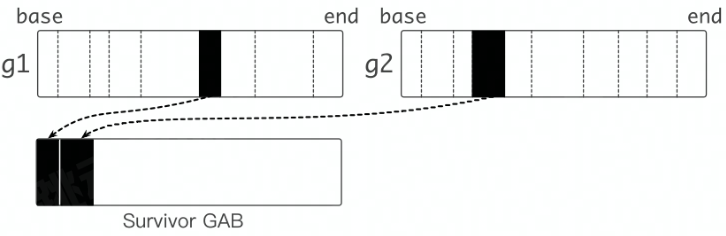
每个 G 都绑定一大块内存(1 KB),称为 Goroutine Allocation Buffer(GAB)。

GAB 有一个问题:会导致内存被延迟释放,GAB 中即使只有一个很小的对象存活,Go 内存管理也不会回收其余空闲空间。
解决方法:
当 GAB 中存活对象大小少于一定阈值时,将 GAB 中存活的对象复制到另外分配的 GAB(Survivor GAB)中,原先的 GAB 可以释放。
函数内联是指,将被调用函数的函数体的副本,替换到调用位置上,同时重写代码以反映参数的绑定。
优点:
缺点:
逃逸分析步骤:
对于未逃逸的对象,在栈上分配;逃逸对象,在堆上分配。
Go 语言中,依赖管理的演进分为三个阶段,依次是:
配置环境变量 $GOPATH,GOPATH 下有以下三个文件夹:
项目的代码直接依赖于 src 下的代码,可以通过 go get 命令将依赖包下载到 src 下。
GOPATH 的缺点在于:无法实现对 package 的多版本控制。
若 A 和 B 依赖于某一 package 的不同版本,这样的情况 GOPATH 无法解决。
项目目录下增加 vendor 文件夹,所有依赖包的副本存放在项目下的 vendor 文件夹中。
若 vendor 中没有依赖包,则会在 GOPATH 下去寻找。
Go Vendor 的缺点在于:无法控制依赖的版本、更新项目可能出现依赖冲突。
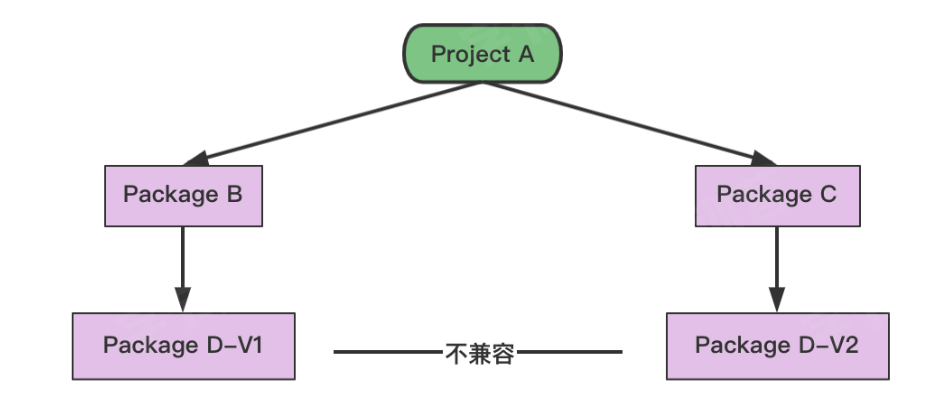
若一个项目依赖于 package B 和 packag C,而 package B 依赖于 package D-V1 版本;package C 依赖于 package D-V2 版本。这样的场景下,Go Vendor 无法很好的解决。
Go Module 通过 go.mod 文件管理依赖包版本。
通过 go get / go mod 工具,管理依赖包。
Go Module 中,依赖管理需要三要素:
go.mod 文件主要由三部分构成:
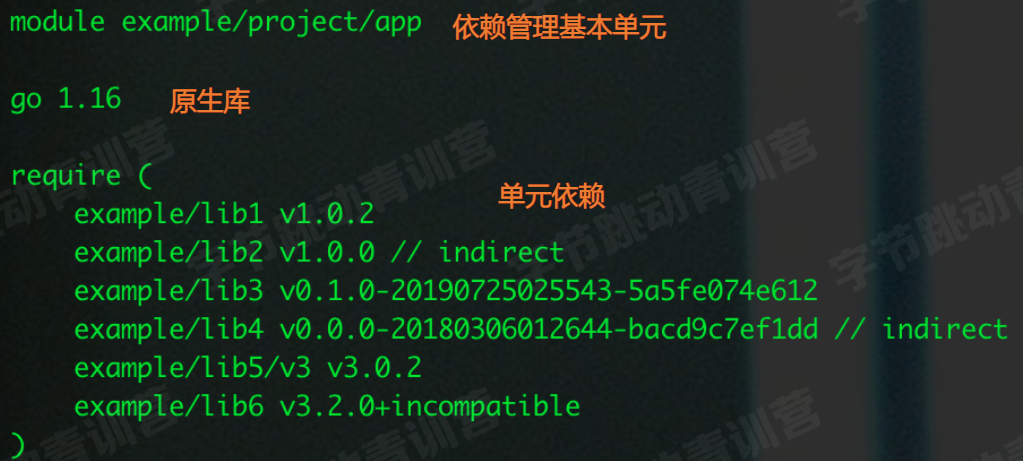
其中,可以看到单元依赖的一些配置:
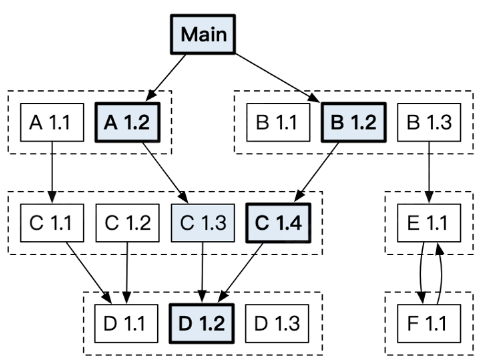
${MAJOR}.${MINOR}.${PATCH},MAJOR 是一个大版本,不同 MAJOR 可以不兼容。MINOR 做出了一些新增函数,同一个 MAJOR 下需要相互兼容。PATCH 做了一些 bug 修复。vx.0.0-yyyymmddhhmmss-abcdefgh1234。xxx/xx/v2)。但是如果 Module 名字未遵循这条规则,则会打上 incompatible 标记。Go 在选择版本时,会选择最低的兼容版本:
如下图中,最终编译时所使用的 C 项目版本为 1.4 版本。
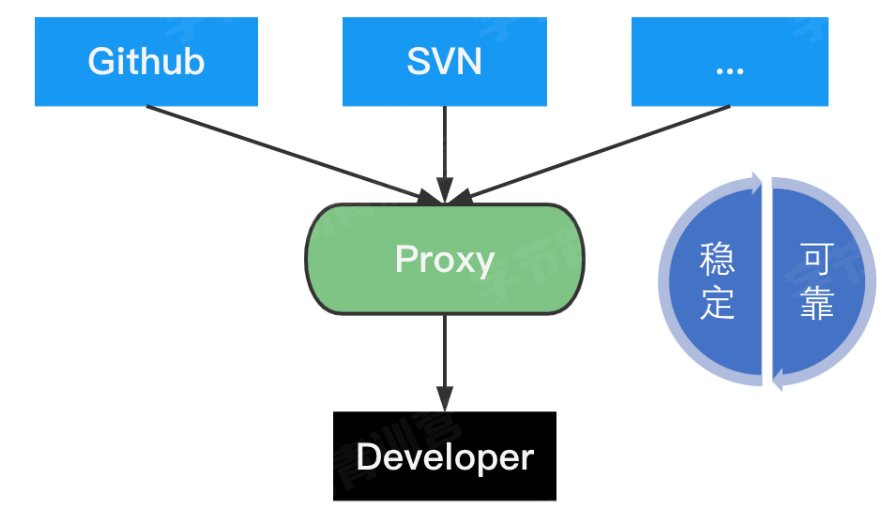
Go Proxy 是一个服务站点,他会缓存源站中的软件内容,缓存的软件版本不会改变,源站软件删除后依然可用。
GOPROXY="https://proxy1.cn,https://proxy2.cn,direct",含义是依次从 proxy1、proxy2、源站中获取 package。
go get:go get example.org/pkg,参数如下:
@update:默认,获取最新版本。@none:删除依赖。@v1.1.1:语义化版本。@45dfsf:特定的 commit。@master:分支的最新 commit。go mod:参数如下:
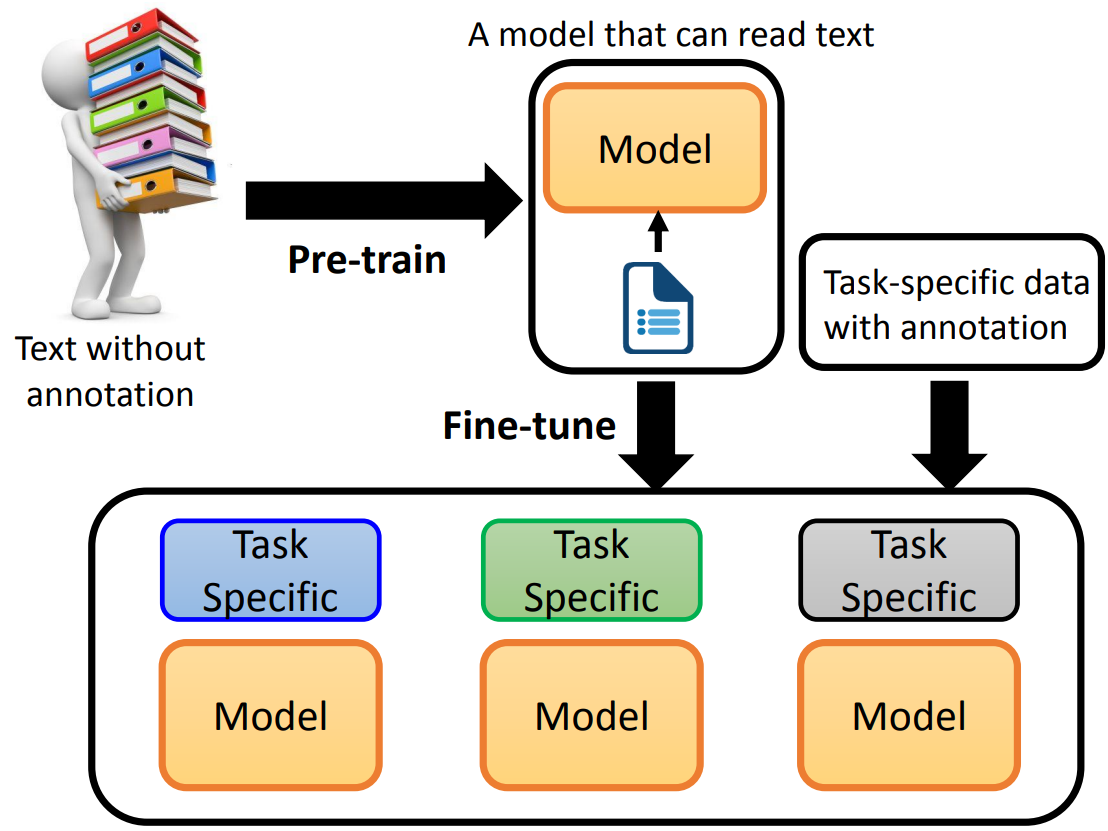
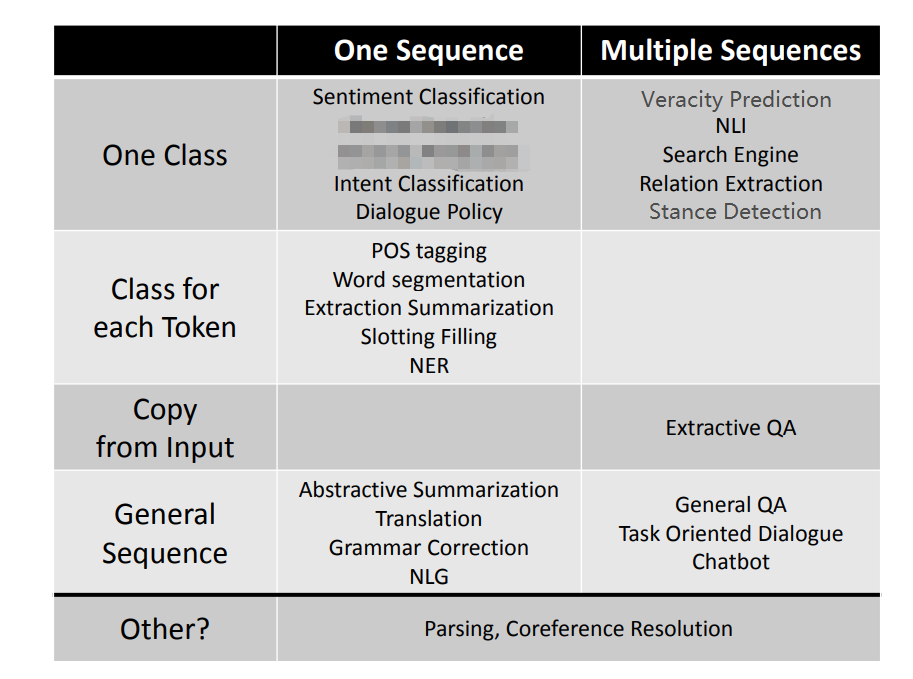
init:初始化,创建 go.mod 文件。download:下载模块到本地。tidy:增加需要的依赖,删除不需要的依赖。NLP 任务总的来说分为两类:
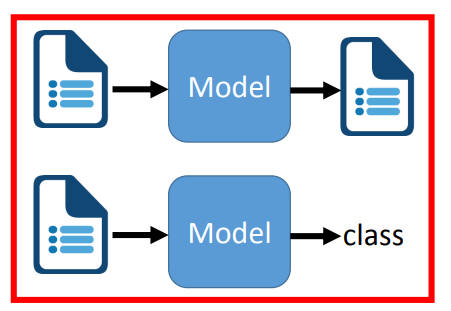
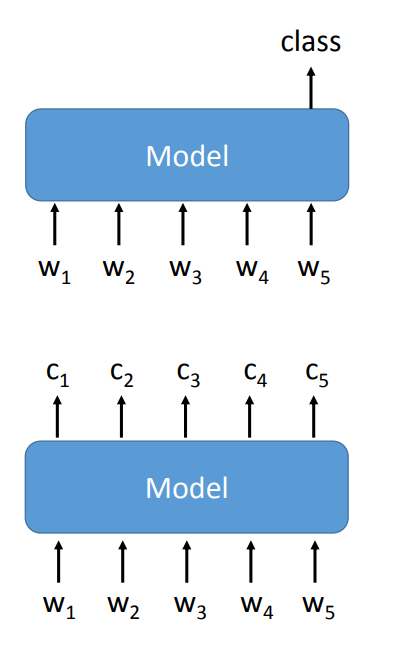
那么进一步的,可以根据输入和输出的不同,进行划分。
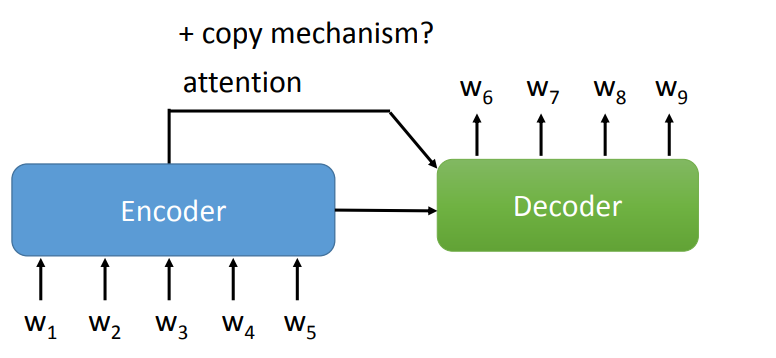
<SEP> 连接。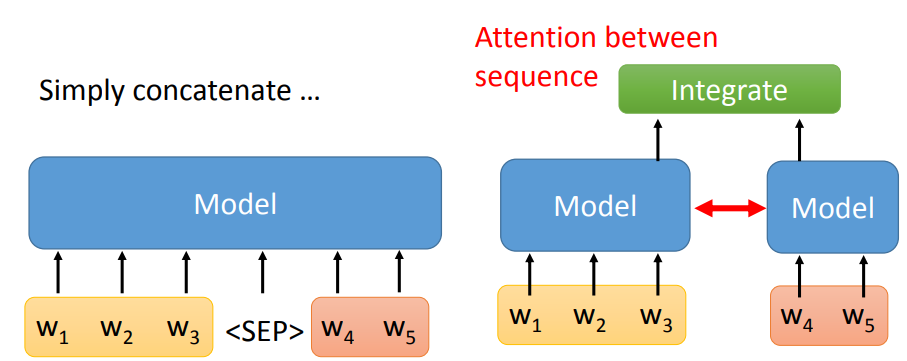
知识图谱中,最重要的就是实体(Entity)和关系(Relation)。
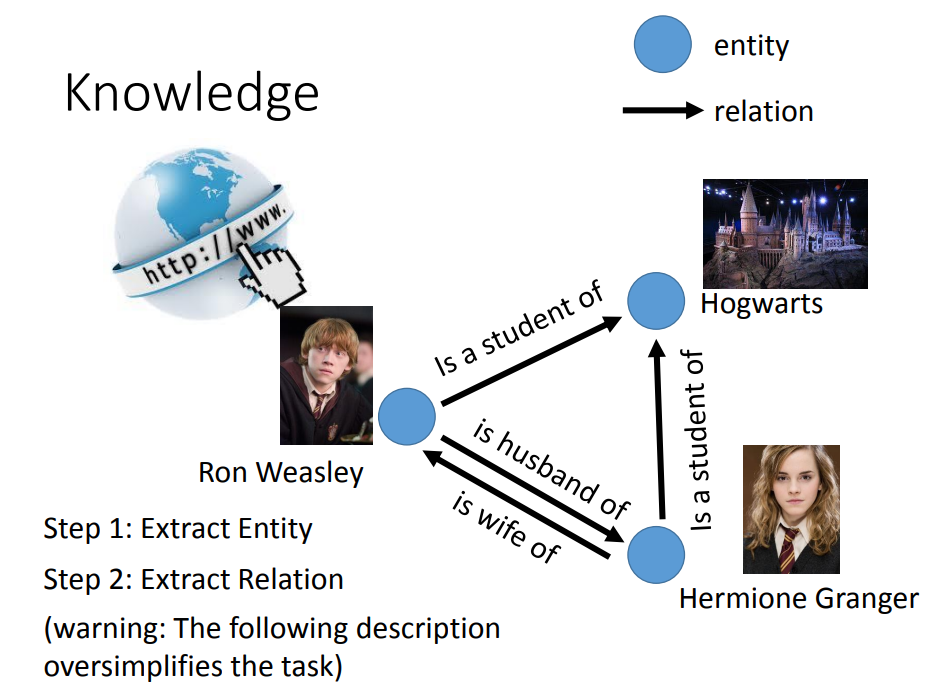
NER,Name Entity Recognition,命名实体识别。用于提取一段文字中给定的实体信息。

提取关系,可以看成是一种分类问题。