Spring 并不直接管理事务,而是提供了多种事务管理器 。Spring 事务管理器的接口是 PlatformTransactionManager,通过这个接口 Spring 可以为各个平台如 JDBC(DataSourceTransactionManager)、Hibernate(HibernateTransactionManager)等提供了对应的事务管理器。
这是因为 Spring AOP 工作原理决定的。因为 Spring AOP 使用动态代理来实现事务的管理,它会在运行的时候为带有 @Transactional 注解的方法生成代理对象,并在方法调用的前后应用事物逻辑。如果该方法被其他类调用代理对象就会拦截方法调用并处理事务。但是在一个类中的其他方法内部调用的时候,代理对象就无法拦截到这个内部调用,因此事务也就失效了。
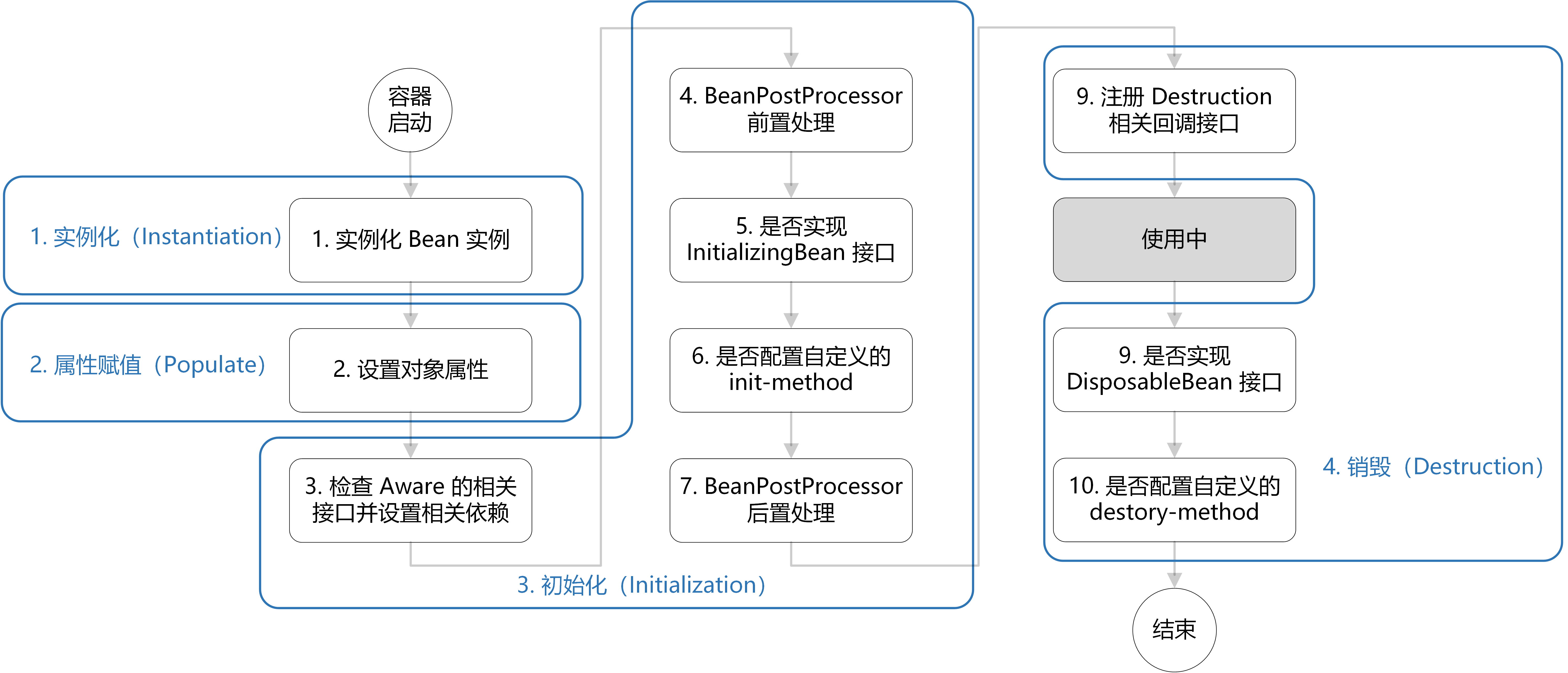
Spring 通过三级缓存来解决循环依赖问题,确保即使在循环依赖的情况下也能正确创建 Bean。Spring 中的三级缓存其实就是三个 Map,如下:
1 2 3 4 5 6 7 8 9 10 11
// 一级缓存 /** Cache of singleton objects: bean name to bean instance. */ privatefinal Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
// 二级缓存 /** Cache of early singleton objects: bean name to bean instance. */ privatefinal Map<String, Object> earlySingletonObjects = new HashMap<>(16);
// 三级缓存 /** Cache of singleton factories: bean name to ObjectFactory. */ privatefinal Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
Spring 是一款开源 Java 开发框架,旨在提高开发人员的开发效率以及系统的可维护性。Spring 指的是 Spring Framework,包含很多模块,这些模块可以协助开发。如 Spring 支持 IOC 和 AOP,可以很方便地对数据库进行访问、可以很方便地集成第三方组件电子邮件,任务,调度,缓存等等)、对单元测试支持比较好、支持 RESTful Java 应用程序的开发。
Spring 最核心的思想就是不重新造轮子,开箱即用,提高开发效率。
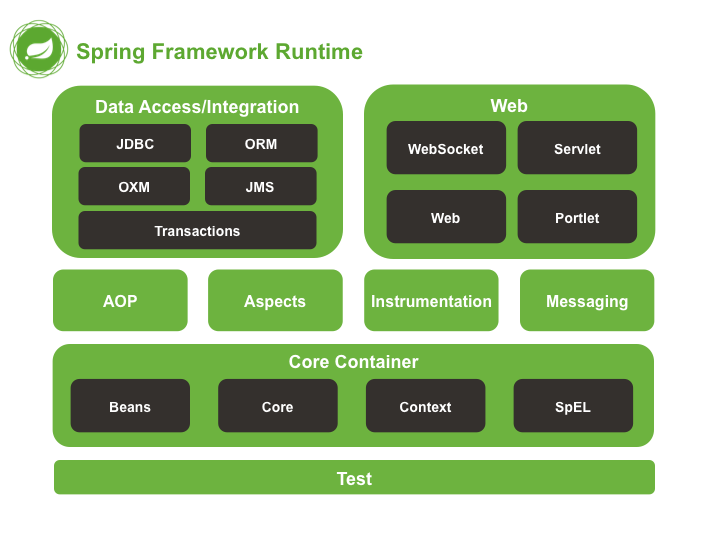
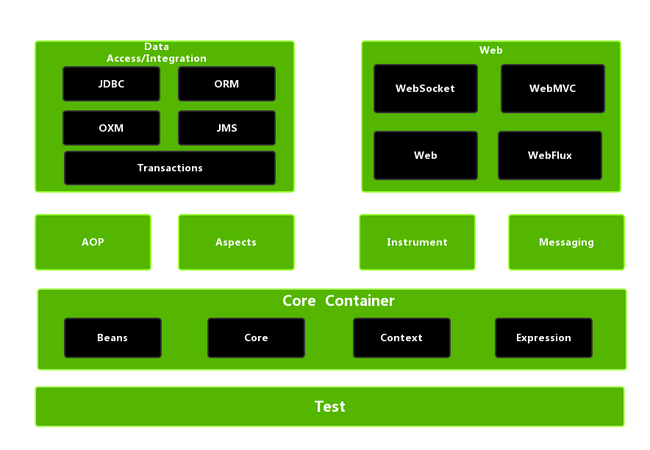
Spring 模块
Spring 1 仅仅支持配置文件,Spring 2 开始引入注解,Spring 3 引入纯注解模式(Spring 配置类代替配置文件)。
Spring 4 的模块架构图:
Spring 5 的模块架构图:
Spring5.x 版本中 Web 模块的 Portlet 组件已经被废弃掉,同时增加了用于异步响应式处理的 WebFlux 组件。
从模块架构图中可以看到,Spring 的模块组织如下:
Core Container(核心容器):提供了对 IOC 控制反转的支持,即对象管理的支持,是 Spring 的基础模块。
再比如,假设我们的项目中有 Spring 的 jar 包,由于其是 Web 应用之间共享的,因此会由 SharedClassLoader 加载(Web 服务器是 Tomcat)。我们项目中有一些用到了 Spring 的业务类,比如实现了 Spring 提供的接口、用到了 Spring 提供的注解。所以,加载 Spring 的类加载器(也就是 SharedClassLoader)也会用来加载这些业务类。但是业务类在 Web 应用目录下,不在 SharedClassLoader 的加载路径下,所以 SharedClassLoader 无法找到业务类,也就无法加载它们。
拿 Spring 这个例子来说,当 Spring 需要加载业务类的时候,它不是用自己的类加载器,而是用当前线程的上下文类加载器。还记得我上面说的吗?每个 Web 应用都会创建一个单独的 WebAppClassLoader,并在启动 Web 应用的线程里设置线程线程上下文类加载器为 WebAppClassLoader。这样就可以让高层的类加载器(SharedClassLoader)借助子类加载器( WebAppClassLoader)来加载业务类,破坏了 Java 的类加载委托机制,让应用逆向使用类加载器。