对 Session 的处理基本上就是设置值、读取值、删除值、获取当前 Session id 四种操作,所以 Session 接口定义如下:
1 2 3 4 5 6
type Session interface { Set(key, value interface{}) error // set session value Get(key interface{}) interface{} // get session value Delete(key interface{}) error // delete session value SessionID() string// back current sessionID }
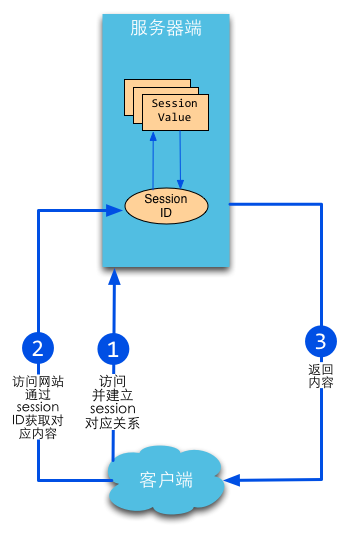
全局唯一的 Session id
Session id 用来标识每一个用户以及对应的 Session,所以必须是全局唯一的:
1 2 3 4 5 6 7 8 9
// 创建全局唯一的 session id func(manager *Manager)sessionId()string { b := make([]byte, 32) if _, err := rand.Read(b); err != nil { return"" }
// Values maps a string key to a list of values. // It is typically used for query parameters and form values. // Unlike in the http.Header map, the keys in a Values map // are case-sensitive. type Values map[string][]string
// Get gets the first value associated with the given key. // If there are no values associated with the key, Get returns // the empty string. To access multiple values, use the map // directly. func(v Values)Get(key string)string { if v == nil { return"" } vs := v[key] iflen(vs) == 0 { return"" } return vs[0] }
// Set sets the key to value. It replaces any existing // values. func(v Values)Set(key, value string) { v[key] = []string{value} }
// Add adds the value to key. It appends to any existing // values associated with key. func(v Values)Add(key, value string) { v[key] = append(v[key], value) }
// Del deletes the values associated with key. func(v Values)Del(key string) { delete(v, key) }
// Has checks whether a given key is set. func(v Values)Has(key string)bool { _, ok := v[key] return ok }
注意:
在处理表单的逻辑事,不要忘了对表单的输入的验证,不能信任用户输入的任何信息。
预防跨站脚本
对 XSS 的防护主要在于两方面:
对输入的验证,检测攻击。
对所有输出数据进行适当的处理,以防止任何已成功注入的脚本在浏览器端运行。
对于对输出数据的处理,Go 的 html/template 里面带有下面几个函数可以转义:
func HTMLEscape (w io.Writer, b [] byte):把 b 进行转义之后写到 w 中。
func HTMLEscapeString (s string) string:转义 s 之后返回结果字符串。
// A FileHeader describes a file part of a multipart request. type FileHeader struct { Filename string Header textproto.MIMEHeader Size int64 // 非导出字段 content []byte tmpfile string }
// 查询数据 rows, err := db.Query("SELECT * FROM userinfo") if err != nil { log.Fatal(err) }
for rows.Next() { var uid int var username string var department string var created string err = rows.Scan(&uid, &username, &department, &created) if err != nil { log.Fatal(err) } // ... }
删除数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// 删除数据 stmt, err = db.Prepare("delete from userinfo where uid=?") if err != nil { log.Fatal(err) }
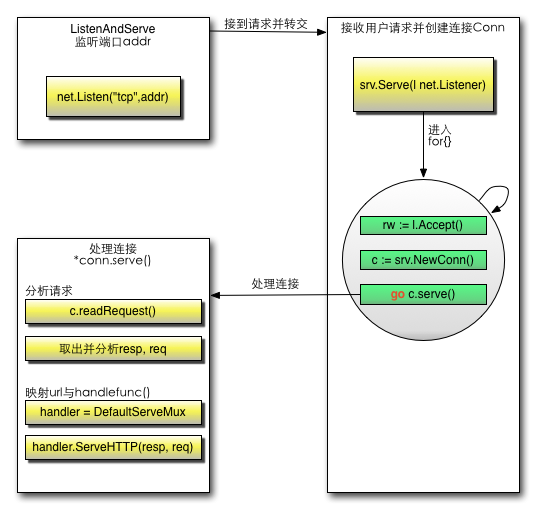
func(srv *Server)Serve(l net.Listener)error { defer l.Close() var tempDelay time.Duration // how long to sleep on accept failure for { rw, e := l.Accept() if e != nil { if ne, ok := e.(net.Error); ok && ne.Temporary() { if tempDelay == 0 { tempDelay = 5 * time.Millisecond } else { tempDelay *= 2 } if max := 1 * time.Second; tempDelay > max { tempDelay = max } log.Printf("http: Accept error: %v; retrying in %v", e, tempDelay) time.Sleep(tempDelay) continue } return e } tempDelay = 0 c, err := srv.newConn(rw) if err != nil { continue } go c.serve() } }
// HandleFunc registers the handler function for the given pattern // in the DefaultServeMux. // The documentation for ServeMux explains how patterns are matched. funcHandleFunc(pattern string, handler func(ResponseWriter, *Request)) { DefaultServeMux.HandleFunc(pattern, handler) }
// HandleFunc registers the handler function for the given pattern. func(mux *ServeMux)HandleFunc(pattern string, handler func(ResponseWriter, *Request)) { if handler == nil { panic("http: nil handler") } mux.Handle(pattern, HandlerFunc(handler)) }
// Handle registers the handler for the given pattern. // If a handler already exists for pattern, Handle panics. func(mux *ServeMux)Handle(pattern string, handler Handler) { mux.mu.Lock() defer mux.mu.Unlock()
if pattern == "" { panic("http: invalid pattern") } if handler == nil { panic("http: nil handler") } if _, exist := mux.m[pattern]; exist { panic("http: multiple registrations for " + pattern) }
if mux.m == nil { mux.m = make(map[string]muxEntry) } e := muxEntry{h: handler, pattern: pattern} mux.m[pattern] = e if pattern[len(pattern)-1] == '/' { mux.es = appendSorted(mux.es, e) }
if pattern[0] != '/' { mux.hosts = true } }
其次调用 http.ListenAndServe 函数:
实例化 Server
调用 Server 的 ListenAndServe
1 2 3 4 5 6 7 8 9 10 11
// ListenAndServe listens on the TCP network address addr and then calls // Serve with handler to handle requests on incoming connections. // Accepted connections are configured to enable TCP keep-alives. // // The handler is typically nil, in which case the DefaultServeMux is used. // // ListenAndServe always returns a non-nil error. funcListenAndServe(addr string, handler Handler)error { server := &Server{Addr: addr, Handler: handler} return server.ListenAndServe() }
// ListenAndServe listens on the TCP network address srv.Addr and then // calls Serve to handle requests on incoming connections. // Accepted connections are configured to enable TCP keep-alives. // // If srv.Addr is blank, ":http" is used. // // ListenAndServe always returns a non-nil error. After Shutdown or Close, // the returned error is ErrServerClosed. func(srv *Server)ListenAndServe()error { if srv.shuttingDown() { return ErrServerClosed } addr := srv.Addr if addr == "" { addr = ":http" } ln, err := net.Listen("tcp", addr) if err != nil { return err } return srv.Serve(ln) }
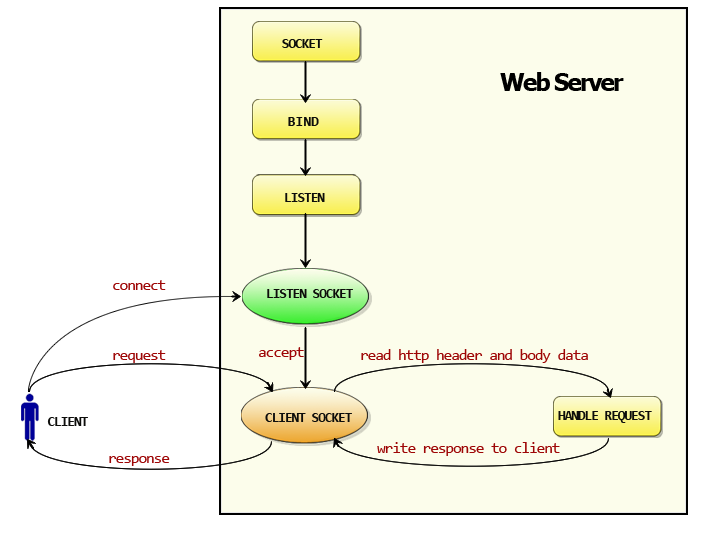
启动一个 for 循环,在循环体中 Accept 请求。对于每一个请求实例化一个 Conn,请开启一个 goroutine 运行服务 go c.serve()
C:\Users\63544>docker container logs 905b hello world hello world hello world hello world hello world hello world hello world
使用 -d 参数启动后会返回一个唯一的 id,也可以通过 docker container ls 命令来查看容器信息(docker ps 命令也可以查看容器信息):
1 2 3
C:\Users\63544>docker container ls CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 905b8470023f ubuntu:18.04 "/bin/sh -c 'while t…" About a minute ago Up About a minute stupefied_pike
$ docker search redis NAME DESCRIPTION STARS OFFICIAL AUTOMATED redis Redis is an open source key-value store that… 11669 [OK] bitnami/redis Bitnami Redis Docker Image 236 [OK] redislabs/redisinsight RedisInsight - The GUI for Redis 75 redislabs/redisearch Redis With the RedisSearch module pre-loaded… 56 redislabs/rejson RedisJSON - Enhanced JSON data type processi… 51 redislabs/redis Clustered in-memory database engine compatib… 36