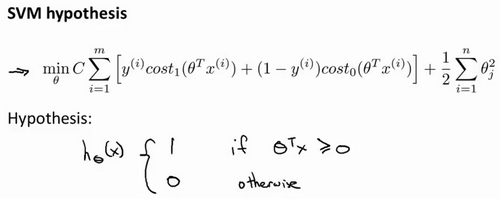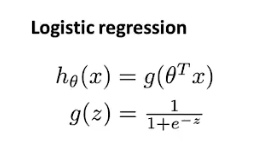支持向量机
目标函数
以下是支持向量机SVM的目标函数,其形式于逻辑回归的形式类似,其中需要注意的是:
- 在SVM中,删除了在逻辑回归里第一项中的1/m。因为1/m仅仅是一个常量,因此,你在这个最小化问题中,无论前面是否有这一项,最终所得到的最优值θ都是一样的。
- 对于逻辑回归的目标函数中,有两项:第一个是训练样本的代价,第二个是我们的正则化项,其形式为A+λB。但是在SVM中,我们将使用一个不同的参数替换这里使用的λ来权衡这两项,其形式为CA+B。因此,在逻辑回归中,如果给定λ一个非常大的值,意味着给予B更大的权重。在SVM中,就对应于将C设定为非常小的值,那么,相应的将会给B比给A更大的权重。
- 在逻辑回归中,输出的是y=1的概率。而在SVM中,当θ^Tx大于等于0时,会输出1,否则输出0