另一个树的子树
解题思路
在root的每一个节点上,判断以这个节点为根的树是否与subRoot相同。
判断两个树是否相等的三个条件是与的关系,即:
- 当前两个树的根节点值相等;
- 并且,
root1的左子树和root2的左子树相等; - 并且,
root1的右子树和root2的右子树相等。
而判断 一棵树是否是另一棵树的子树的三个条件是或的关系,即:
- 当前两棵树相等;
- 或者,
subRoot在root的左子树中; - 或者,
subRoot在root的右子树中。
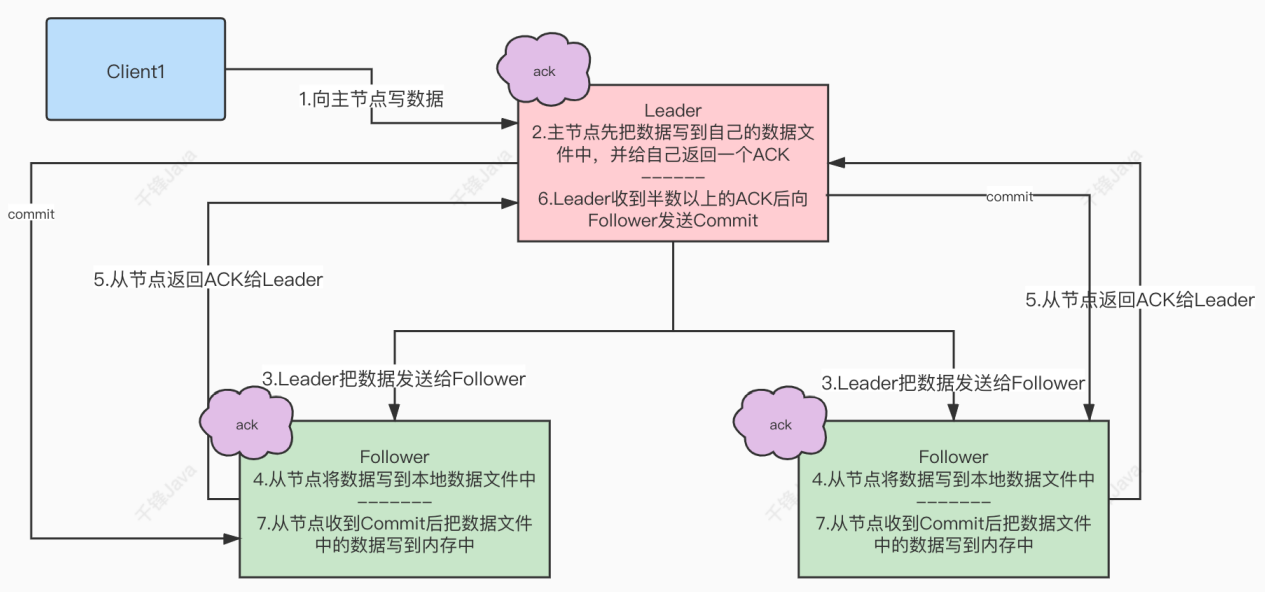
生产者:把ACK设置为1(等待leader的ACK)或者ALL(leader及其follower同步之后返回ACK)
消费者:把自动提交设置为手动提交offset
在防止消息丢失的⽅案中,如果生产者发送完消息后,因为网络抖动,没有收到ACK,但实际上broker已经收到了。此时生产者会进行重试,于是broker就会收到多条相同的消息,从而造成消费者的重复消费。
或者消费者已经消费了数据,但是offset没来得及提交,会导致重复消费。
解决方案,消费者保证幂等性:
在Kafka中若要实现顺序消费,会牺牲性能,但是Rocket MQ有专门的功能实现顺序消费。
订单创建后,超过30分钟没有⽀付,则需要取消订单,这种场景可以通过延时队列来实现。
topic_30m表示延时30分钟的延时队列在Kafka中,需要有一个管理者,称为Controller,它在ZooKeeper的帮助下管理和协调整个Kafka集群。Controller本身也是一台Broker节点,只不过需要负责一些额外的工作(追踪集群中的其他Broker,并在合适的时候处理新加入的和失败的Broker节点、Rebalance分区、分配新的leader分区等)。
Kafka集群中始终只有一个Controller Broker。
Broker 在启动时,会尝试去 ZooKeeper 中创建/controller的临时序号节点,获得的序号最小的那个broker将会作为集群中的controller。
Controller的作用:
Controller可以依据ZooKeeper的Watch机制,来监听Broker的变化。
每个 Broker 启动后,会在zookeeper的/Brokers/ids下创建临时znode。当Broker宕机或主动关闭后,该Broker与ZooKeeper的会话结束,这个znode会自动删除。
ZooKeeper的Watch机制会将节点的变化情况推送给Controller,这样Controller就知道某个Broker宕机了,可以采取行动决定哪些Broker上的分区成为leader分区(选择isr列表中最靠前的作为新的leader)。然后,它会通知每个相关的Broker。
大部分情况下,Broker的失败很短暂,这意味着Broker通常会在短时间内恢复。所以当节点离开群集时,与其相关联的元数据并不会被立即删除。
当Controller注意到Broker已加入集群时,它将使用Broker ID来检查该Broker上是否存在分区,如果存在,则Controller通知新加入的Broker和现有的Broker,新的Broker上面的follower分区再次开始复制现有leader分区的消息。为了保证负载均衡,Controller会将新加入的Broker上的follower分区选举为leader分区。
如果controller Broker 挂掉了,Kafka集群必须找到可以替代的controller,集群将不能正常运转。这里面存在一个问题,很难确定Broker是挂掉了,还是仅仅只是短暂性的故障。但是,集群为了正常运转,必须选出新的controller。如果之前被取代的controller又正常了,他并不知道自己已经被取代了,那么此时集群中会出现两台controller。
比如,某个controller由于GC而被认为已经挂掉,并选择了一个新的controller。在GC的情况下,在最初的controller眼中,并没有改变任何东西,该Broker甚至不知道它已经暂停了。因此,它将继续充当当前controller。现在,集群中出现了两个controller,它们可能一起发出具有冲突的命令,就会出现脑裂的现象。
Kafka种,使用使用epoch number(纪元编号)来避免脑裂问题。epoch number只是单调递增的数字,第一次选出Controller时,epoch number值为1,如果再次选出新的Controller,则epoch number将为2,依次单调递增。
每个新选出的controller通过Zookeeper获得获得一个全新的、数值更大的epoch number 。其他Broker 在知道当前epoch number 后,如果收到由controller发出的包含较小epoch number的消息,就会忽略它们。
LEO(Log End Offset)是某个副本最后消息的消息位置。
HW(High Watermark)高水位,是指已完成同步的位置。消费者最多只能消费到HW所在的位置。
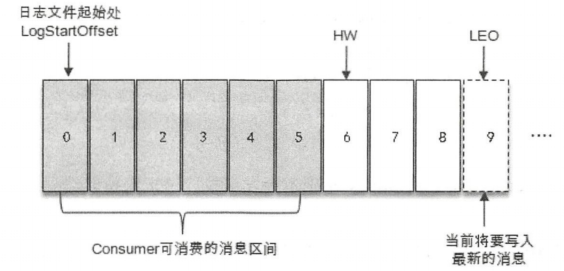
另外,每一个leader和follower各⾃负责更新自己的HW的状态。对于leader新写⼊的消息,consumer不能立刻消费,leader会等待该消息被所有ISR中的副本同步后更新HW,此时消息才能被consumer消费。这样就保证了如果leader所在的broker失效,该消息仍然可以从新选举的leader中获取。
1 | 已知 rand_N() 可以等概率的生成[1, N]范围的随机数 |
要实现rand10(),就需要实现rand_N(),并且保证N大于10且是10的倍数。这样就可以通过rand_N() % 10 + 1得到[1, 10]范围内的随机数了。
(rand7()-1) × 7 + rand7() ==> rand49(),但是49不是10的倍数。这里就涉及到了“拒绝采样”的知识了,也就是说,如果某个采样结果不在要求的范围内,则丢弃它。
1 | func rand10() int { |
1 | func rand10() int { |
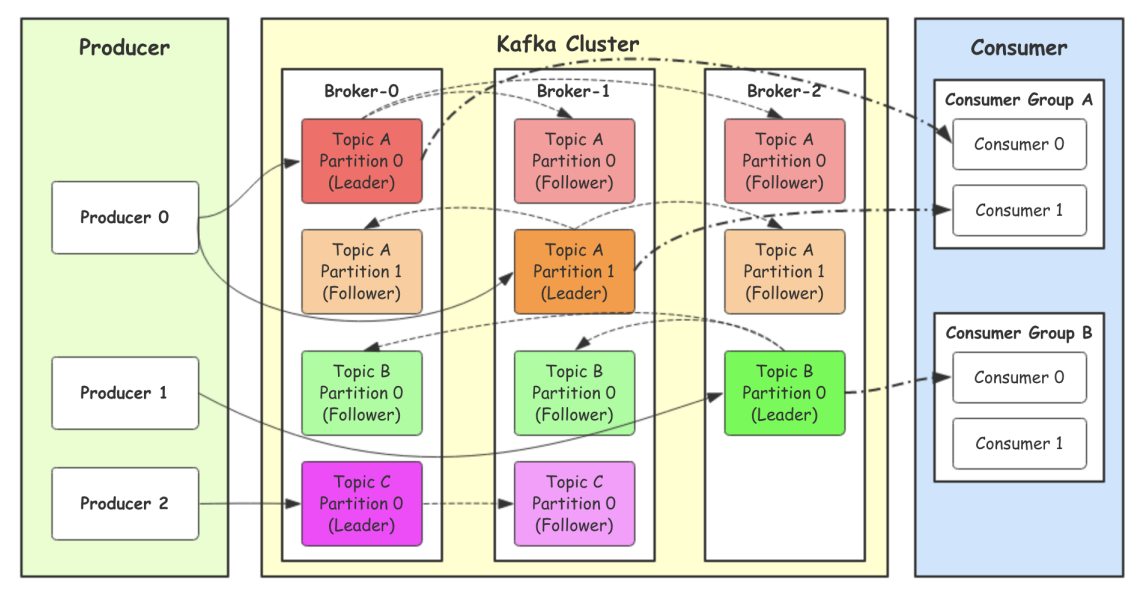
在kafka中,一个topic指定了多个partition,生产者选择partition的方式:
⽣产者同步发消息,在收到kafka的ACK告知发送成功之前⼀直处于阻塞状态。
⽣产者发消息,发送完后不用等待broker给回复,直接执⾏下面的业务逻辑。
注意:异步发送可能会丢失消息。
同步发送的前提下,生产者向集群发送消息时,关于ACK应答机制有3个配置:
0代表producer往集群发送数据不需要等待集群的返回。也就是说,集群不需要任何broker收到消息,就立刻返回ACK给生产者。不确保消息发送成功。安全性最低但是效率最⾼。1代表producer往集群发送数据只要leader应答(Leader将消息写入本地日志中)就可以发送下⼀条,只确保leader发送成功。默认选项。all代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下⼀条,确保leader发送成功和所有的副本都完成备份。安全性最⾼,但是效率最低。副本是为了为主题中的分区创建多个备份,多个副本在kafka集群的多个broker中,会有⼀个副本作为leader,其他是follower。
下图是拥有2个分区,3个副本的主题:
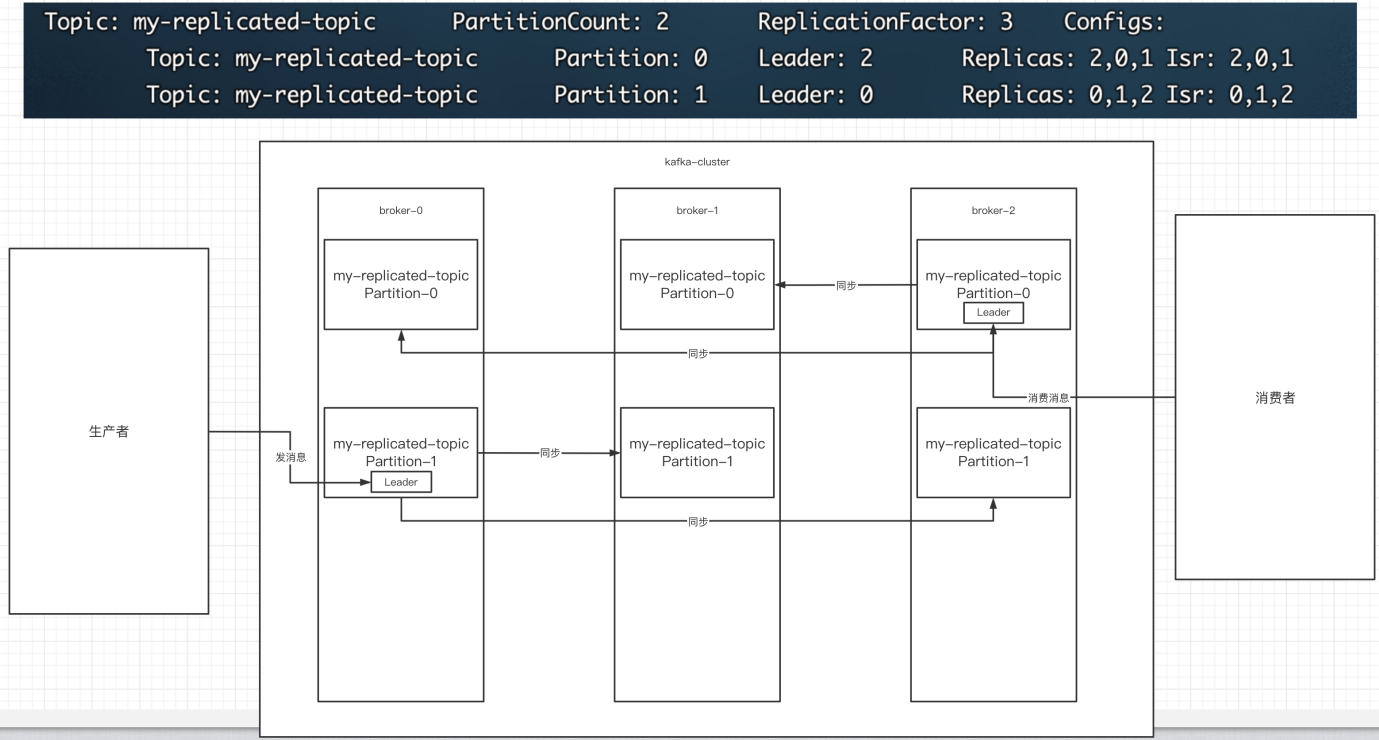
图中Kafka集群有两个broker,每个broker中有多个partition。
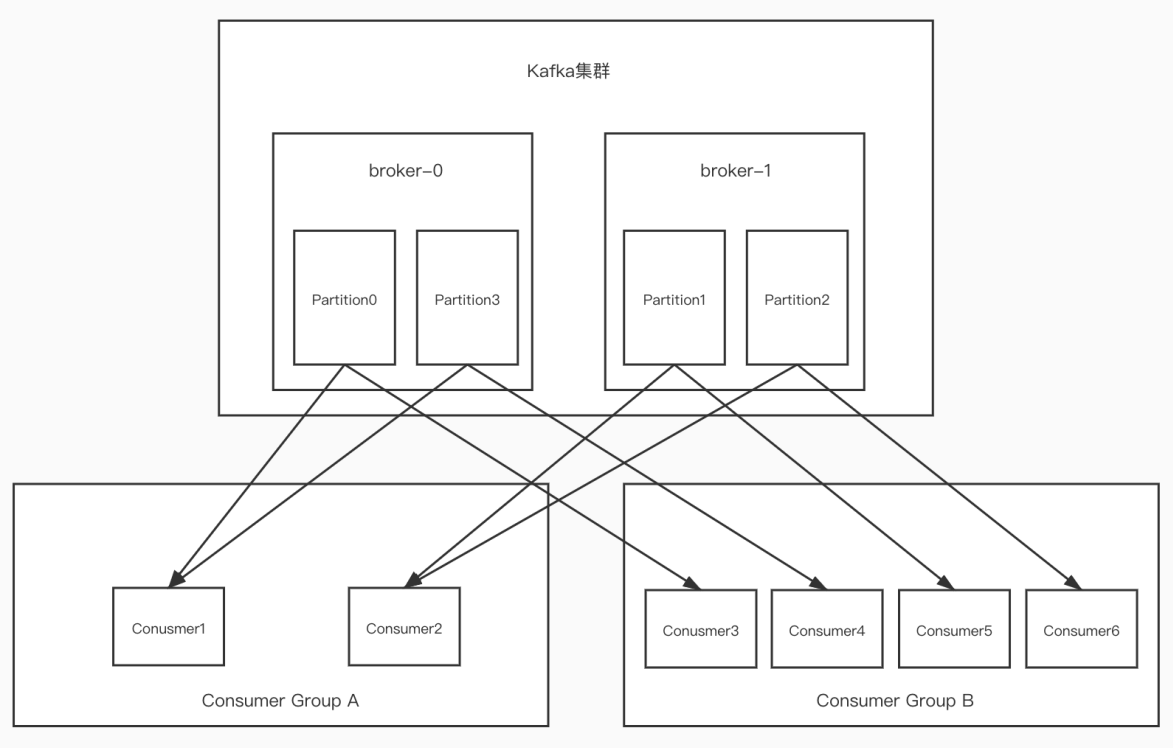
一个partition只能被一个消费组里的某一个消费者消费,从而保证消费顺序。
Kafka只在partition的范围内保证消息消费的局部顺序性,不能在同⼀个topic中的多个partition中保证总的消费顺序性。
一个消费者可以消费多个partition,但是消费者组中的消费者数量不能比一个topic中的partition数量多,否则多出来的消费者消费不到消息。
如果消费者宕机,会触发rebalance机制,让其他消费者来消费该分区。
划分为两种遍历形式:朝着右上方遍历和朝着左下方遍历。
1 | func findDiagonalOrder(mat [][]int) []int { |
利用滑动窗口的思想,start指向窗口的起始位置,end指向窗口的终止位置的后一位,sum为窗口内数字之和:
sum < target,end需要向后移动sum > target,start需要向前移动1 | func minSubArrayLen(target int, nums []int) int { |
当待删除节点是叶子节点时,直接删除
待删除节点只有一个分支时,用其分支节点代替待删除的节点
待删除节点的左右子树均存在时:
key的节点1 | /** |
CAP理论为:⼀个分布式系统最多只能同时满足⼀致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
BASE理论是对CAP理论的延申,核心思想就是即使无法做到强一致性(CAP的一致性就是强一致性),但可以采取适当的方式达到最终一致性。
ZooKeeper保证的最终一致性又叫做顺序一致性,即每个结点的数据都是严格按事务的发起顺序生效的。
zookeeper中的事务ID为ZXID,ZXID由Leader节点生成,有新写入事件时,Leader生成新ZXID并随提案一起广播,每个结点本地都保存了当前最近一次事务的ZXID,ZXID是递增的,所以谁的ZXID越大,就表示谁的数据是最新的。
ZXID的生成规则如下:
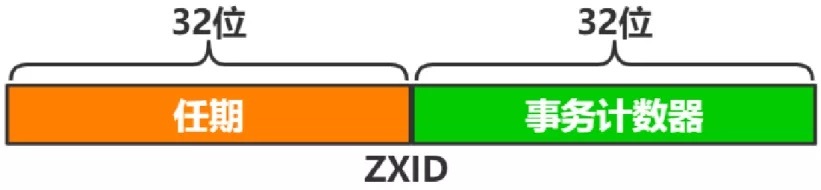
ZXID由两部分组成:
ZXID的低32位是计数器,所以同一任期内,ZXID是连续的,每个结点又都保存着自身最新生效的ZXID,通过对比新提案的ZXID与自身最新ZXID是否相差1,来保证事务严格按照顺序生效的。
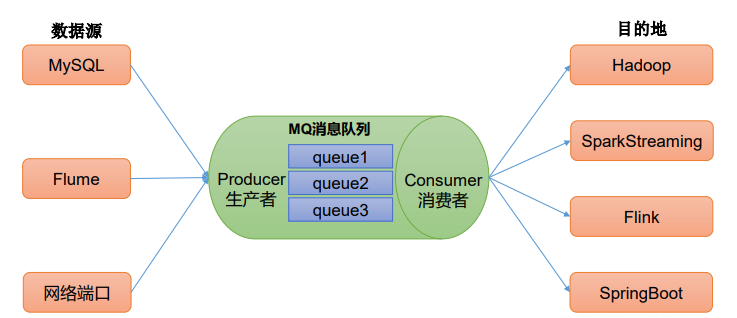
类似于队列,消费者消费消息后会清除消息。
消息⽣产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点⽅式不同,发布到topic的消息会被所有订阅者消费。
Kafka是一种高吞吐量的分布式发布订阅消息系统。
同时Kafka结合点对点模型和发布订阅模型:
zookeeper集群中的节点共有三种角色:
zookeeper作为⾮常重要的分布式协调组件,需要进行集群部署,集群中通常会以一主多从的方式进行部署。zookeeper为了保证数据的一致性,使用ZAB(zookeeper atomic broadcast)协议,这一协议解决了zookeeper的崩溃恢复和主从数据同步的问题。
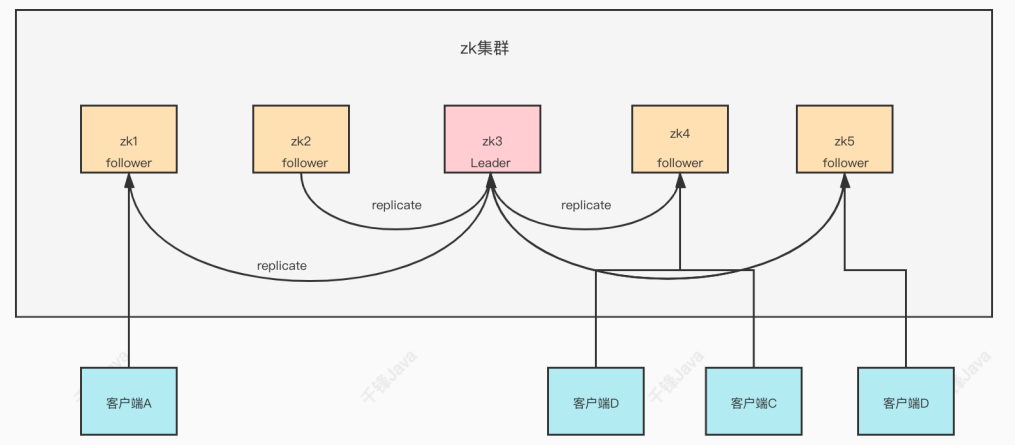
ZAB中协议定义了四种节点状态:
若进行Leader选举,则至少需要两台机器,这里选取3台机器组成的服务器集群为例。在集群初始化阶段,当有一台服务器Server1启动时,其单独无法进行和完成Leader选举,当第二台服务器Server2启动时,此时两台机器可以相互通信,每台机器都试图找到Leader,于是进入Leader选举过程。选举过程如下:
每个Server发出一个投票。由于是初始情况,Server1和Server2都会将自己作为Leader服务器来进行投票,每次投票会包含所推举的服务器的myid和ZXID,使用(myid, ZXID)来表示,其中myid为服务器的唯一标识,ZXID为事务号。此时Server1的投票为(1, 0),Server2的投票为(2, 0),然后各自将这个投票发给集群中其他机器。
接受来自各个服务器的投票。集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票、是否来自LOOKING状态的服务器。
处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行PK,PK规则如下:
对于对于Server1而言,它的投票是(1, 0),接收Server2的投票为(2, 0),首先会比较两者的ZXID,均为0,再比较myid,此时Server2的myid最大,于是更新自己的投票为(2, 0),然后重新投票,对于Server2而言,其无须更新自己的投票,只是再次向集群中所有机器发出上一次投票信息即可。
统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,对于Server1、Server2而言,都统计出集群中已经有两台机器接受了(2, 0)的投票信息,此时便认为已经选出了Leader。
改变服务器状态。一旦确定了Leader,每个服务器就会更新自己的状态。
Leader建立完成后,Leader会周期性的不断向Follower发送心跳。当Leader崩溃后,Follower会进入Looking状态,重新进行Leader选举,此时集群不能对外服务。