基本操作
连接zookeeper
1 | // 连接zookeeper服务器 |
增
1 | /* |
删
1 | // 删除 |
改
1 | // 更新节点 |
查
1 | // 查询 |
Watch机制
只监听一次
调用zk.WithEventCallback(callback)设置回调
1 | package main |
开启一个channel处理
可以开一一个协程来处理chanel中传来的event事件,可以持续监听
1 | package main |
1 | // 连接zookeeper服务器 |
1 | /* |
1 | // 删除 |
1 | // 更新节点 |
1 | // 查询 |
调用zk.WithEventCallback(callback)设置回调
1 | package main |
可以开一一个协程来处理chanel中传来的event事件,可以持续监听
1 | package main |
zookeeper中可以实现两种锁:
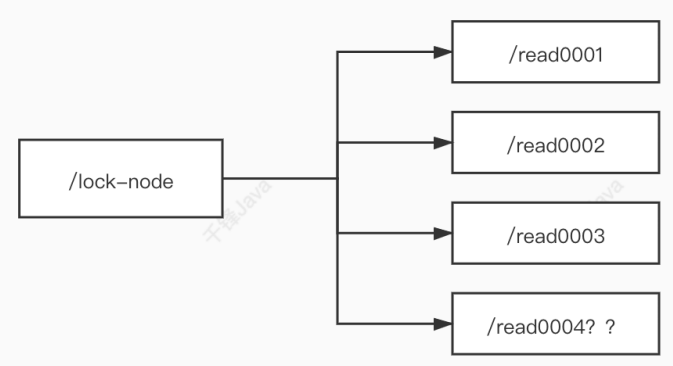
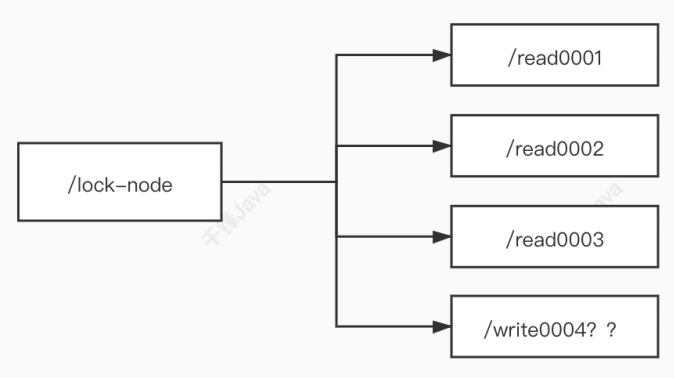
羊群效应:如果采用上述的上锁方式,只要有节点发生变化,就会触发其他节点的监听事件,这样对于zookeeper的压力非常大。
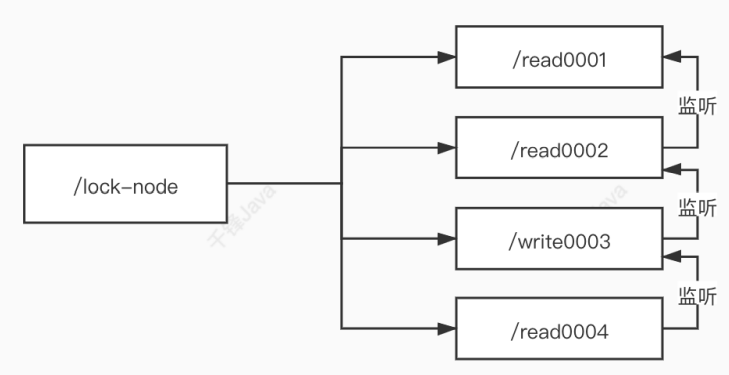
可以调整成链式监听:
ZooKeeper是一种分布式协调服务,用于管理大型分布式集群。在分布式环境中协调和管理服务是一个复杂的过程,但是ZooKeeper通过其简单的架构和API解决了这个问题。
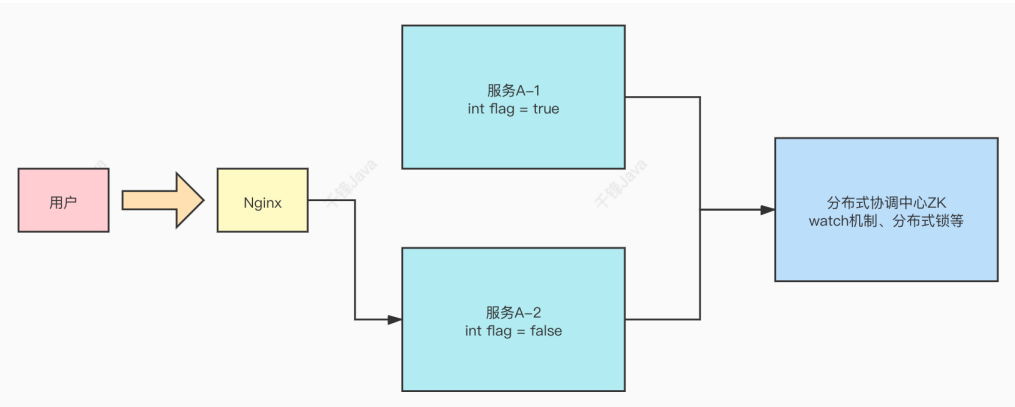
在分布式系统中,需要zookeeper作为分布式协调组件,协调分布式系统中的状态。如下图,用户更改了一台服务器A-2上的状态,但是另一台主机A-1上的flag没有做出及时的更改,这就需要zookeeper进行协调,更改A-1的状态,以协调分布式系统中所有服务器的状态。
zookeeper在实现分布式锁上,可以做到强⼀致性。
分布式锁就是将锁放在zookeeper上,当需要上锁时到zookeeper中获取锁。
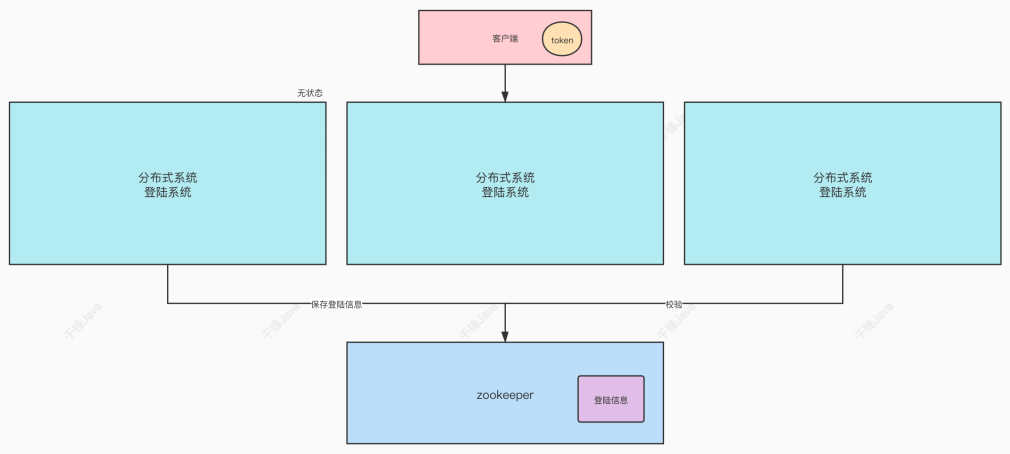
对于分布式系统,将Session或者Cookie等状态信息保存在各个主机上是不现实的。可以利用zookeeper实现分布式系统的无状态化,将登录信息统一保存在zookeeper中,各个分布式主机在zookeeper中获取状态信息。
因为log agent可以部署在多台机器上,每一台机器上需要收集的日志可能不尽相同,所以需要针对不同机器部署不同的配置文件。
因为不同的机器上拥有不同的配置文件,所以etcd中每一台机器对应的配置文件的key应该是唯一可标识的,这样可以区分不同的机器。在key中加入IP地址以区别不同的key,故config.ini做出以下更改:
1 | # 原来是collect_conf_key = collect_conf |
相对应的增加一个获取IP地址的函数,用于获取IP地址:
1 | // GetOutboundIP 获取本机的IP地址 |
在main主函数中,首先获取本机的IP地址:
1 | // 获取本机ip |
根据配置文件中的collect_conf_key = collect_%s_conf项格式化字符串,替换配置文件结构体中的相应字段:
1 | // 用ip替换collect_conf_key中的%s |
目前,已经完成了日志收集log agent的构建。
现在来构建用于收集系统日志的sys info agent,需要收集的系统信息包括CPU、主存、磁盘、网络信息,将收集到的系统信息发送给Kafka。基本思路与log agent相同:
influxDB是时间序列数据库,主键是时间戳。
| influxDB名词 | 传统数据库概念 |
|---|---|
| database | 数据库 |
| measurement | 数据表 |
| point | 数据行 |
1 | measurement [,tag_key1=tag_value1...] field_key=field_value[,field_key2=field_value2] [timestamp] |
measurements, tag keys, field keys,tag values 全局存一份;field values 和 timestamps 每条数据存一份
influxDB中的point相当于传统数据库里的一行数据,由时间戳(time)、数据(field)、标签(tag)组成。
| Point属性 | 传统数据库概念 |
|---|---|
| time | 每个数据记录时间,是数据库中的主索引 |
| field | 各种记录值(没有索引的属性),例如温度、湿度 |
| tags | 各种有索引的属性,例如地区、海拔 |
measurement、tag set、retention policy相同的数据集合,称为一个series。同一个series的数据,在物理上会按照时间顺序排列存储在一起。
series的key为measurement + 所有tags的序列化字符串
保留策略RP,包括数据保存的时间以及在集群中的副本个数。
默认的保留策略为,保存时间无限制、副本个数为1
shard与RP相关联,每一个存储策略下会存在许多shard,每一个shard存储一个指定时间段内的数据,并且不会重复。
shard保存数据的始阶段计算函数如下:
1 | func shardGroupDuration(d time.Duration) time.Duration { |
每一个shard都对应底层的一个TSM存储引擎,这样做的目的就是为了可以通过时间来快速定位到要查询数据的相关资源,加速查询的过程,并且也让之后的批量删除数据的操作变得非常简单且高效。
首先来看上一版本的配置文件:
1 | [kafka] |
通过配置文件指定需要收集的日志时,主要有两个问题:
tail.Tail对象,来收集多个日志上述问题的原因在于ini配置文件无法同时定义多个日志文件路径。解决的方法就是通过etcd管理日志收集配置,在etcd中以json的格式存储日志收集配置信息,如下方:
1 | [ |
相应的,需要修改config.ini配置文件,配置etcd的相关设置:
1 | [kafka] |
etcd是使用Go语言开发的一个开源的、高可用的分布式key-value存储系统,可以用于配置共享和服务的注册和发现。
etcd具有以下特点:
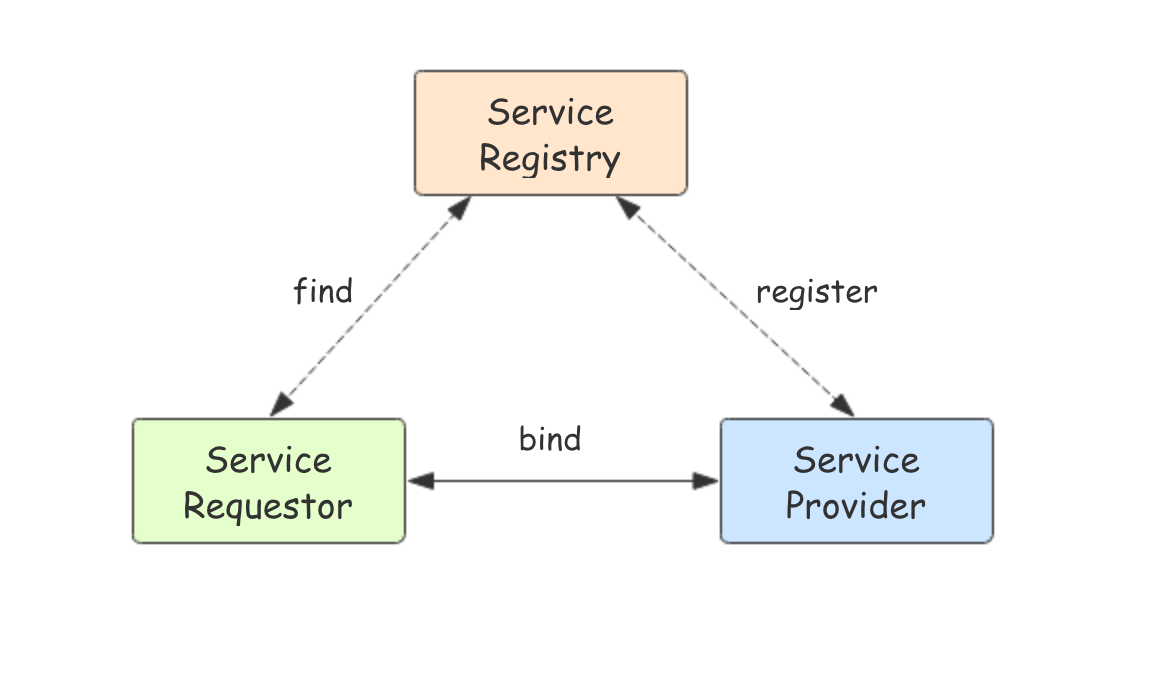
在一个分布式集群中,如何找到提供某项服务的主机并与之建立连接,这就是服务发现所完成的功能:
将一些配置信息放到 etcd 上进行集中管理。
这类场景的使用方式通常是这样:应用在启动的时候主动从 etcd 获取一次配置信息,同时,在 etcd 节点上注册一个 Watcher 并等待,以后每次配置有更新的时候,etcd 都会实时通知订阅者,以此达到获取最新配置信息的目的。
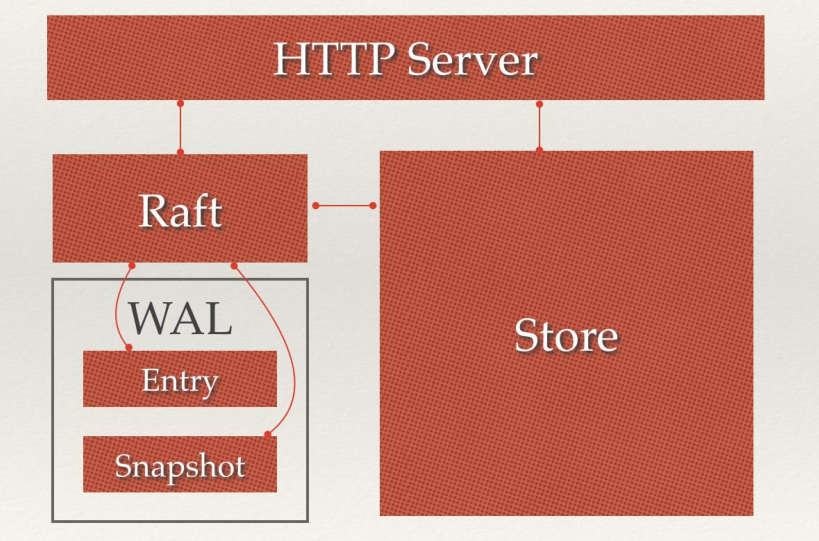
因为 etcd 使用 Raft 算法保持了数据的强一致性,某次操作存储到集群中的值必然是全局一致的,所以很容易实现分布式锁。锁服务有两种使用方式,一是保持独占,二是控制时序。
CompareAndSwap)的 API。通过设置prevExist值,可以保证在多个节点同时去创建某个目录时,只有一个成功。而创建成功的用户就可以认为是获得了锁。POST动作,这样 etcd 会自动在目录下生成一个当前最大的值为键,存储这个新的值(客户端编号)。同时还可以使用 API 按顺序列出所有当前目录下的键值。此时这些键的值就是客户端的时序,而这些键中存储的值可以是代表客户端的编号。etcd主要分为四个部分:
etcd一般部署集群推荐奇数个节点,推荐的数量为 3、5 或者 7 个节点构成一个集群。
1 | package main |
用于监控etcd中的key的变化(创建/更改/删除)
1 | func main() { |
ini格式的文件是配置文件中常用的格式。
=隔开#开头的为注释[name]作为标志1 | [mysql] |
go-ini为GO语言提供了读写ini文件的功能。如使用go-ini读取上面的配置文件:
1 | package main |
使用go-ini读取配置文件的步骤如下:
ini.Load加载配置文件,得到配置对象cfgcfg.Section获取分区对象,使用Key方法得到对应配置项的对象Key对象需根据类型调用对应的方法返回具体类型,可以使用String、Int、Float64等方法。配置文件中存储的都是字符串,所以类型为字符串的配置项不会出现类型转换失败的,故String方法只返回一个值。但是Int和Uint等方法可能会转换失败,返回一个值和一个错误。
如果每次取值都需要进行错误判断,那么代码写起来会非常繁琐。go-ini为此提供了对应的MustType方法(Type为Int/Uint/Float64等),这个方法只返回一个值。同时它接收可变参数,如果类型无法转换,取参数中第一个值返回,并且该参数设置为这个配置的值,下次调用返回这个值。
在加载配置之后
Sections方法获取所有分区SectionStrings()方法获取所有的分区名Section(name)获取名为name的分区,如果该分区不存在,则自动创建一个分区并返回NewSection(name)手动创建一个新分区,如果分区已存在,则返回错误可以在分区名中使用.表示两个或多个分区之间的父子关系。
例如package.sub的父分区为package,package的父分区为默认分区。如果某个键在子分区中不存在,则会在它的父分区中再次查找,直到没有父分区为止。
可以将生成的配置对象写入到文件中,保存有两种类型的接口,一种直接保存到文件,另一种写入到io.Writer中:
1 | err = cfg.SaveTo("my.ini") |
*Indent方法会对分区下的键进行缩进。
定义结构变量,加载完配置文件后,调用MapTo将配置项赋值到结构变量的对应字段中。
1 | type Config struct { |
也可以通过结构体生成配置:
1 | func NewIni() { |
首先,初步编写一个logagent:
tail.Tail对象TailObj。TailObj从日志中读取数据,封装成msg送入消息管道。协程从消息管道中取出数据并发送给Kafka配置文件conf/config.ini:
1 | [kafka] |
读取配置文件:
1 | // 读配置文件 |
kafka/kafka.go:
1 | package kafka |
tailfile.tailfile.go:
1 | package tailfile |
1 | // 从TailObj中从log中读取数据,封装成msg放入到通道中 |
所以main.go中的流程为:
1 | package main |
tail包用于输出文件的最后几行。假设该档案有更新,tail会自己主动刷新,确保你看到最新的档案内容 ,在日志收集中可以实时的监测日志的变化。
1 | func TailFile(filename string, config Config) (*Tail, error) |
tail2.TailFile()函数的参数是文件路径和配置文件,会生成一个Tail结构体。在Tail结构体中,最重要的属性是文件名Filename和用于存储文件一行Line的通道Lines:
1 | type Tail struct { |
其中表示文件中一行的结构体为Line,这个结构体用于存储读取的一行信息:
1 | type Line struct { |