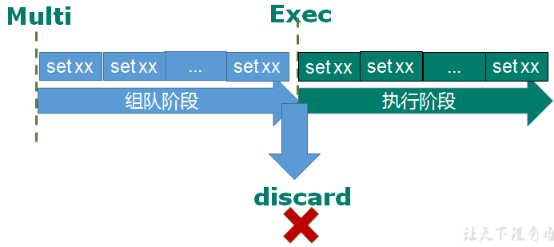
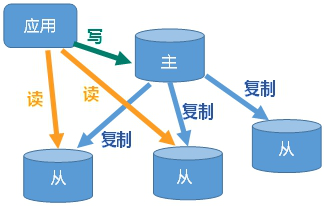
概述
主从复制就是,主机数据更新后,自动同步到备机的master/slaver机制,master以写为主,slaver以读为主。
好处:
- 读写分离
- 容灾快速恢复(一台服务器宕机了,转到其他服务器)
1 | # 在从机上使用slaveof命令加入主机,host为主机地址,port为主机端口 |
利用动态规划,dp[i]表示金额为i的硬币组合数,边界条件是dp[0] = 1,表示组成金额0有一种组合数。
dp[0] = 1coins,对于其中的每个元素coin:i从coin到amount,dp[i] += dp[i-coin]dp[amount]为最终答案1 | func change(amount int, coins []int) int { |
MySQL中利用锁来保证事务的隔离性,对并发操作进行控制。同时,锁冲突也是影响数据库并发访问性能的重要因素。
对于两个事务都进行写数据(写-写情况)的操作,可能会产生脏写问题,这是任何一种隔离级别都不允许这种问题的发生的。
所以在多个未提交事务相继对一条记录做改动时,需要让它们排队执行(通过锁实现)。
对于一个事务进行读取操作,一个事务进行写数据的操作(读-写情况),可能会产生脏读、不可重复读和幻读的问题。对于这些问题,有两种解决方案。
所谓MVCC,就是生成一个ReadView,通过ReadView找到符合条件的记录版本。查询语句只能读到生成ReadView之前已提交事务所做的更改。而写操作肯定针对的是最新的版本信息,读记录的历史版本和改动记录的最新版本并不冲突,也就是采用MVCC时,读-写并不冲突。
普通的SELECT语句在READ COMMITTED和REPEATABLE READ隔离级别下会使用到MVCC读取记录:
READ COMMITTED隔离级别下,一个事务在执行过程中每次执行SELECT操作时都会生成一个ReadView,ReadView的存在本身就保证了事务不可以读取到未提交的事务所做的更改,也就是避免了脏读现象。REPEATABLE READ隔离级别下,一个事务在执行过程中只有第一次执行SELECT操作才会生成一个ReadView,之后的SELECT操作都复用这个ReadView,这样也就避免了不可重复读和幻读的问题。Redis提供了两种不同形式的持久化方式:
RDB持久化指在指定的时间间隔内将内存中的数据集快照写入磁盘。它也是默认的持久化方式,这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb
对于RDB来说,提供了三种机制:
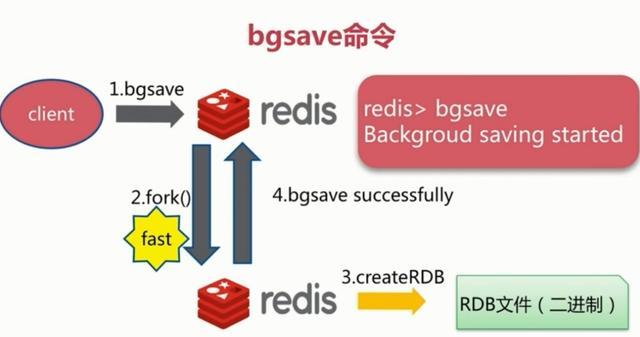
save会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。
Redis会fork一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。阻塞只发生在fork阶段,一般时间很短。
事务的隔离性由锁机制实现。
而事务的原子性、一致性和持久性由事物的redo日志和undo日志来保证。
undo日志不是redo日志的逆过程,redo和undo都可以是看作是恢复操作:
InnoDB是以页为单位来管理存储空间的。在访问页面时,需要先把磁盘上的页缓存到内存中的缓冲池中,所有的修改必须先更新缓冲池中的数据,然后缓冲区中的脏页(写入缓冲池但还没有写回磁盘的页)以一定频率被刷新到磁盘中。
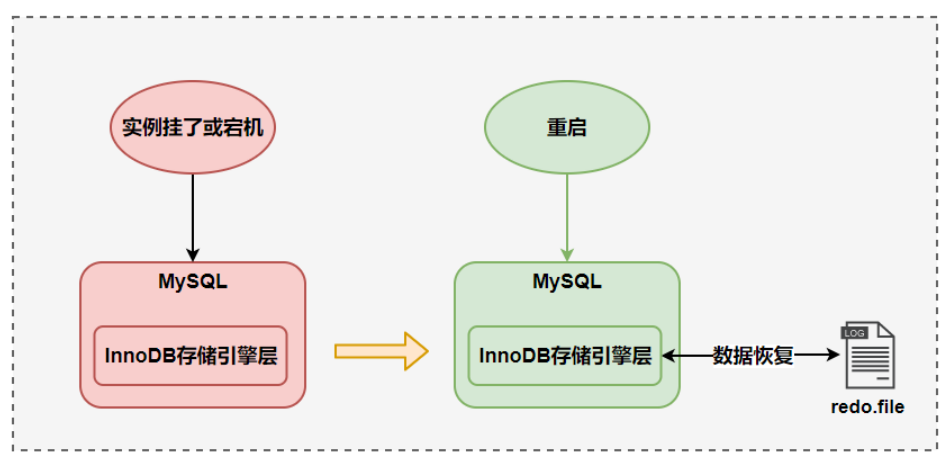
若有这样一种场景,当事务提交后,刚写完缓冲池还没来得及将修改写回磁盘,数据库宕机了,那么这段数据就丢失了。
但是,事务包含了持久性的特点,对于一个已经提交的事务,在事务提交后即使系统发生了崩溃,这个事务对数据库中所做的更改也不能丢失。
所以,这就引入了redo日志:只需要把修改了哪些东西记录一下就好。InnoDB的事务采用了WAL(Write-Ahead Logging)技术,这种技术的思想就是先写日志(redo日志),再写磁盘,只有日志成功写入,事务才算提交成功。当服务器宕机还未刷新磁盘时,可以通过redo日志恢复,以保证事务的持久性。
Bitmaps数据类型提供了对比特位的操作:

setbit <key> <offset> <value>:设置Bitmaps中某个偏移量的值
getbit <key> <offset>:获取Bitmaps中某个偏移量的值
bitcount <key> [start end]:统计字符串从start字节到end字节比特值为1的数量
bitop and(or/not/xor) <destkey> [key…]:对多个Bitmaps进行与、或、非、异或运算
HyperLogLog用于做基数(基数就是集合中不同元素的个数)统计,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
但是,HyperLogLog只会根据输入元素来计算基数,而不会储存输入元素本身,所以HyperLogLog不能像集合那样,返回输入的各个元素。
pfadd <key> < element> [element ...]:添加指定元素到HyperLogLog中
pfcount <key> [key ...]:计算多个HyperLogLog中的近似基数
pfmerge <destkey> <sourcekey> [sourcekey ...]:将一个或多个HyperLogLog合并后存储在另一个HyperLogLog中
Geospatial类型用于记录地理位置信息,即经纬度坐标。
InnoDB是支持事务的
事务:一组逻辑操作单元,使数据从一种状态变换到另一种状态
事务处理的原则:保证所有事务都作为一个工作单元来执行,即使出现了故障,都不能改变这种执行方式。当在一个事务中执行多个操作时,要么所有的事务都被提交( commit ),那么这些修改就永久地保存下来;要么数据库管理系统将放弃所作的所有修改,整个事务回滚(rollback )到最初状态。
ACID即原子性(atomicity)、一致性(consistency)、隔离性(isolation)和持久性(durability)