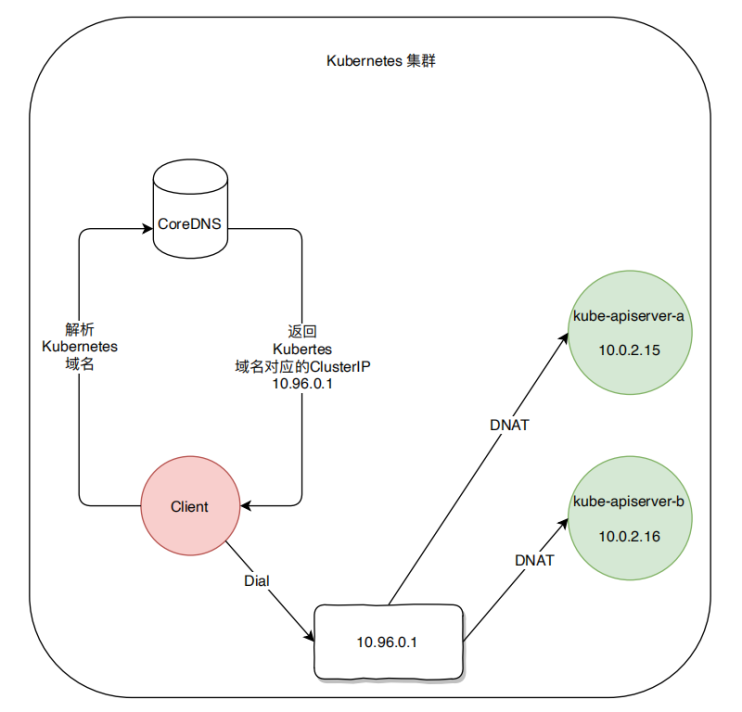
原子类都存放在java.util.concurrent.atomic下:
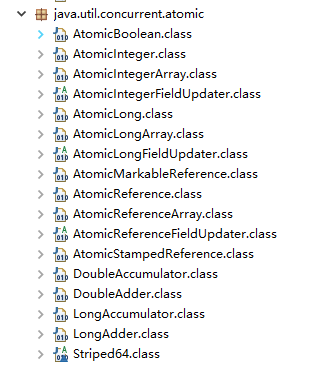
根据操作的数据类型,可以将 JUC 包中的原子类分为 4 类:
基本类型
AtomicInteger:整型原子类。AtomicLong:长整型原子类。AtomicBoolean:布尔型原子类。
数组类型
AtomicIntegerArray:整型数组原子类。AtomicLongArray:长整型数组原子类。AtomicReferenceArray:引用类型数组原子类。
引用类型
AtomicReference:引用类型原子类。AtomicMarkableReference:原子更新带有标记的引用类型,该类将 boolean 标记与引用关联起来。AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
对象的属性修改类型
AtomicIntegerFieldUpdater:原子更新整型字段的更新器。AtomicLongFieldUpdater:原子更新长整型字段的更新器。AtomicReferenceFieldUpdater:原子更新引用类型里的字段。