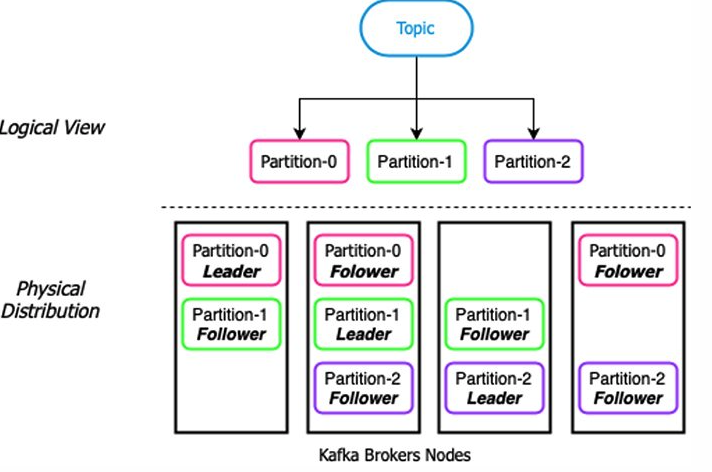
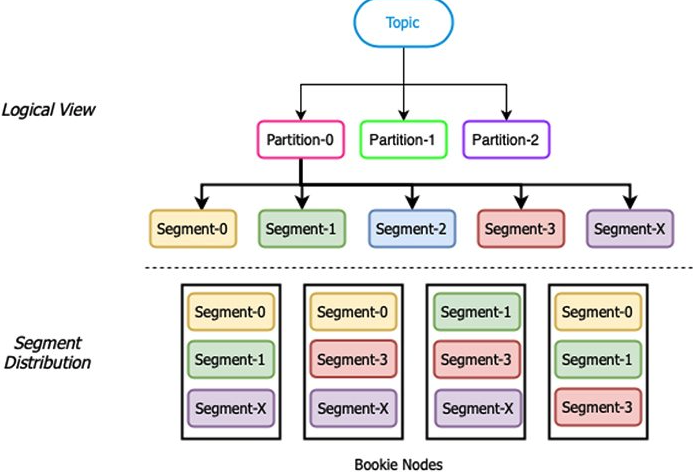
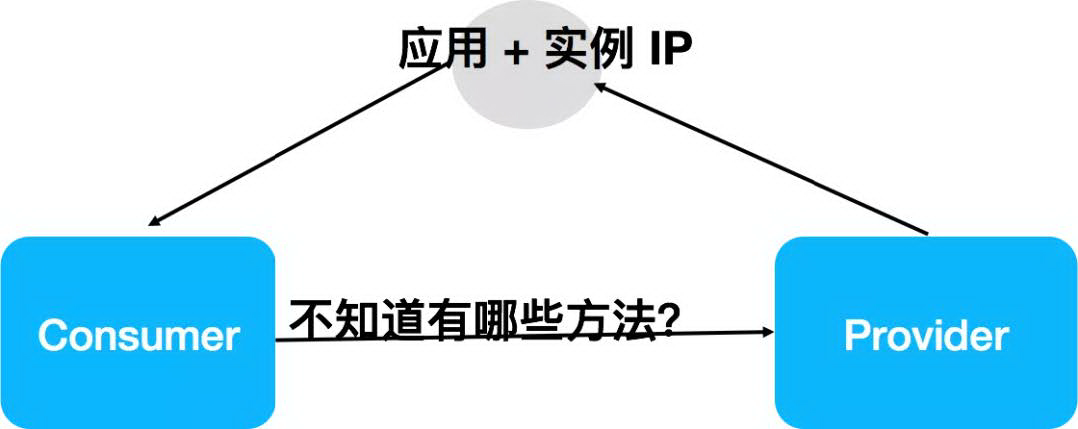
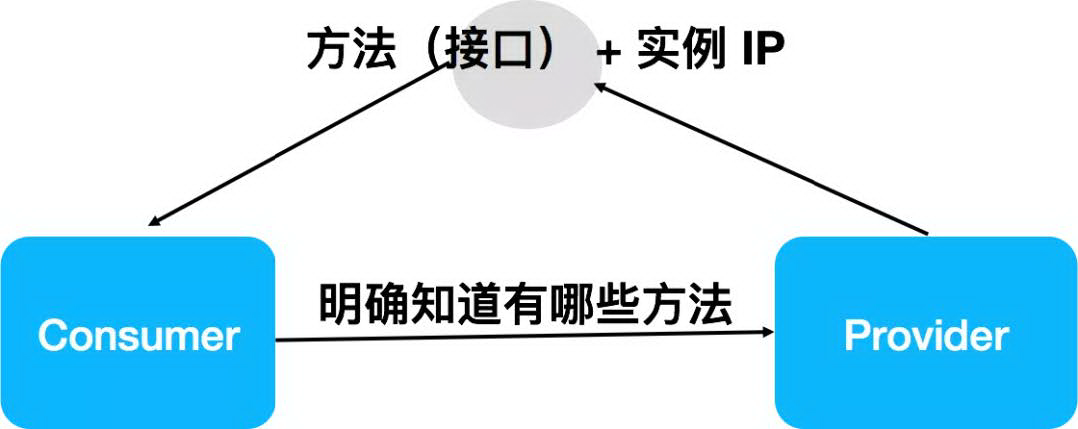
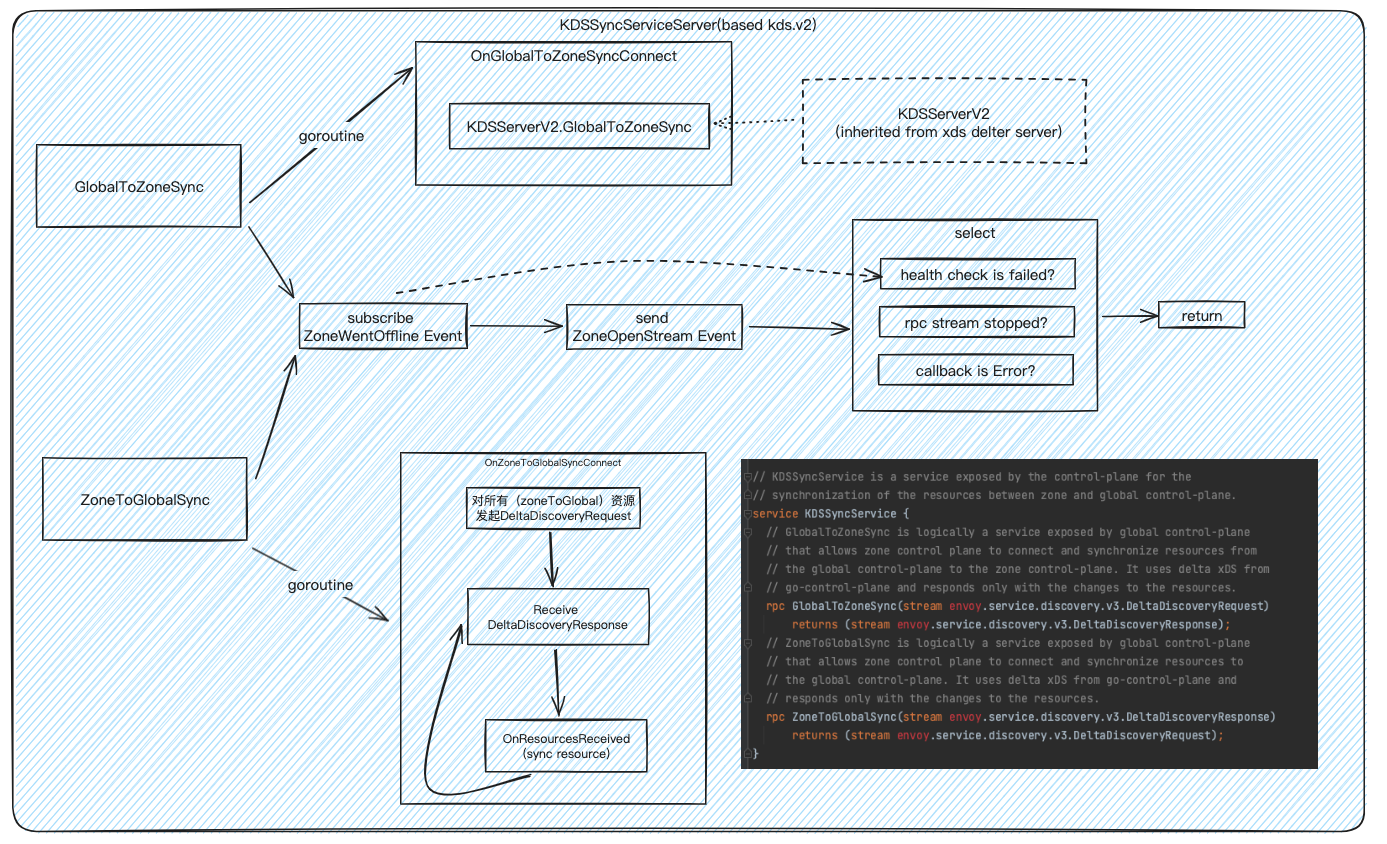
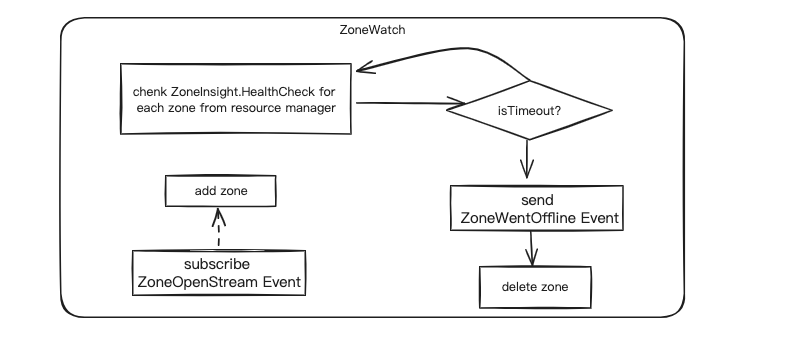
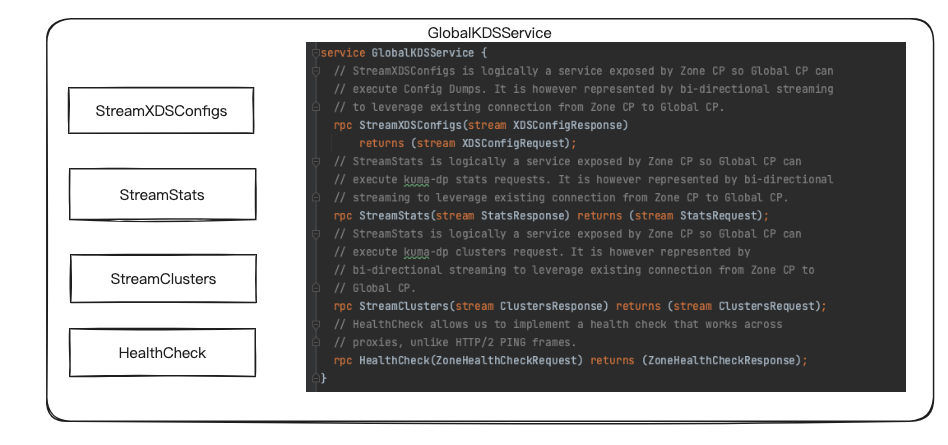
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
| func initializeResourceManager(cfg kuma_cp.Config, builder *core_runtime.Builder) error {
defaultManager := core_manager.NewResourceManager(builder.ResourceStore())
customizableManager := core_manager.NewCustomizableResourceManager(defaultManager, nil)
customizableManager.Customize(
mesh.MeshType,
mesh_managers.NewMeshManager(
builder.ResourceStore(),
customizableManager,
builder.CaManagers(),
registry.Global(),
builder.ResourceValidators().Mesh,
cfg.Store.UnsafeDelete,
builder.Extensions(),
),
)
rateLimitValidator := ratelimit_managers.RateLimitValidator{
Store: builder.ResourceStore(),
}
customizableManager.Customize(
mesh.RateLimitType,
ratelimit_managers.NewRateLimitManager(builder.ResourceStore(), rateLimitValidator),
)
externalServiceValidator := externalservice_managers.ExternalServiceValidator{
Store: builder.ResourceStore(),
}
customizableManager.Customize(
mesh.ExternalServiceType,
externalservice_managers.NewExternalServiceManager(builder.ResourceStore(), externalServiceValidator),
)
customizableManager.Customize(
mesh.DataplaneType,
dataplane.NewDataplaneManager(builder.ResourceStore(), builder.Config().Multizone.Zone.Name, builder.ResourceValidators().Dataplane),
)
customizableManager.Customize(
mesh.DataplaneInsightType,
dataplaneinsight.NewDataplaneInsightManager(builder.ResourceStore(), builder.Config().Metrics.Dataplane),
)
customizableManager.Customize(
system.ZoneType,
zone.NewZoneManager(builder.ResourceStore(), zone.Validator{Store: builder.ResourceStore()}, builder.Config().Store.UnsafeDelete),
)
customizableManager.Customize(
system.ZoneInsightType,
zoneinsight.NewZoneInsightManager(builder.ResourceStore(), builder.Config().Metrics.Zone),
)
customizableManager.Customize(
mesh.ZoneIngressInsightType,
zoneingressinsight.NewZoneIngressInsightManager(builder.ResourceStore(), builder.Config().Metrics.Dataplane),
)
customizableManager.Customize(
mesh.ZoneEgressInsightType,
zoneegressinsight.NewZoneEgressInsightManager(builder.ResourceStore(), builder.Config().Metrics.Dataplane),
)
var cipher secret_cipher.Cipher
switch cfg.Store.Type {
case store.KubernetesStore:
cipher = secret_cipher.None()
case store.MemoryStore, store.PostgresStore:
cipher = secret_cipher.TODO()
default:
return errors.Errorf("unknown store type %s", cfg.Store.Type)
}
var secretValidator secret_manager.SecretValidator
if cfg.IsFederatedZoneCP() {
secretValidator = secret_manager.ValidateDelete(func(ctx context.Context, secretName string, secretMesh string) error { return nil })
} else {
secretValidator = secret_manager.NewSecretValidator(builder.CaManagers(), builder.ResourceStore())
}
customizableManager.Customize(
system.SecretType,
secret_manager.NewSecretManager(builder.SecretStore(), cipher, secretValidator, cfg.Store.UnsafeDelete),
)
customizableManager.Customize(
system.GlobalSecretType,
secret_manager.NewGlobalSecretManager(builder.SecretStore(), cipher),
)
builder.WithResourceManager(customizableManager)
if builder.Config().Store.Cache.Enabled {
cachedManager, err := core_manager.NewCachedManager(
customizableManager,
builder.Config().Store.Cache.ExpirationTime.Duration,
builder.Metrics(),
builder.Tenants(),
)
if err != nil {
return err
}
builder.WithReadOnlyResourceManager(cachedManager)
} else {
builder.WithReadOnlyResourceManager(customizableManager)
}
return nil
}
|