多集群部署方案
Kuma 支持多区域部署,甚至是 Kubernetes 集群和 Universal 集群的混合部署。

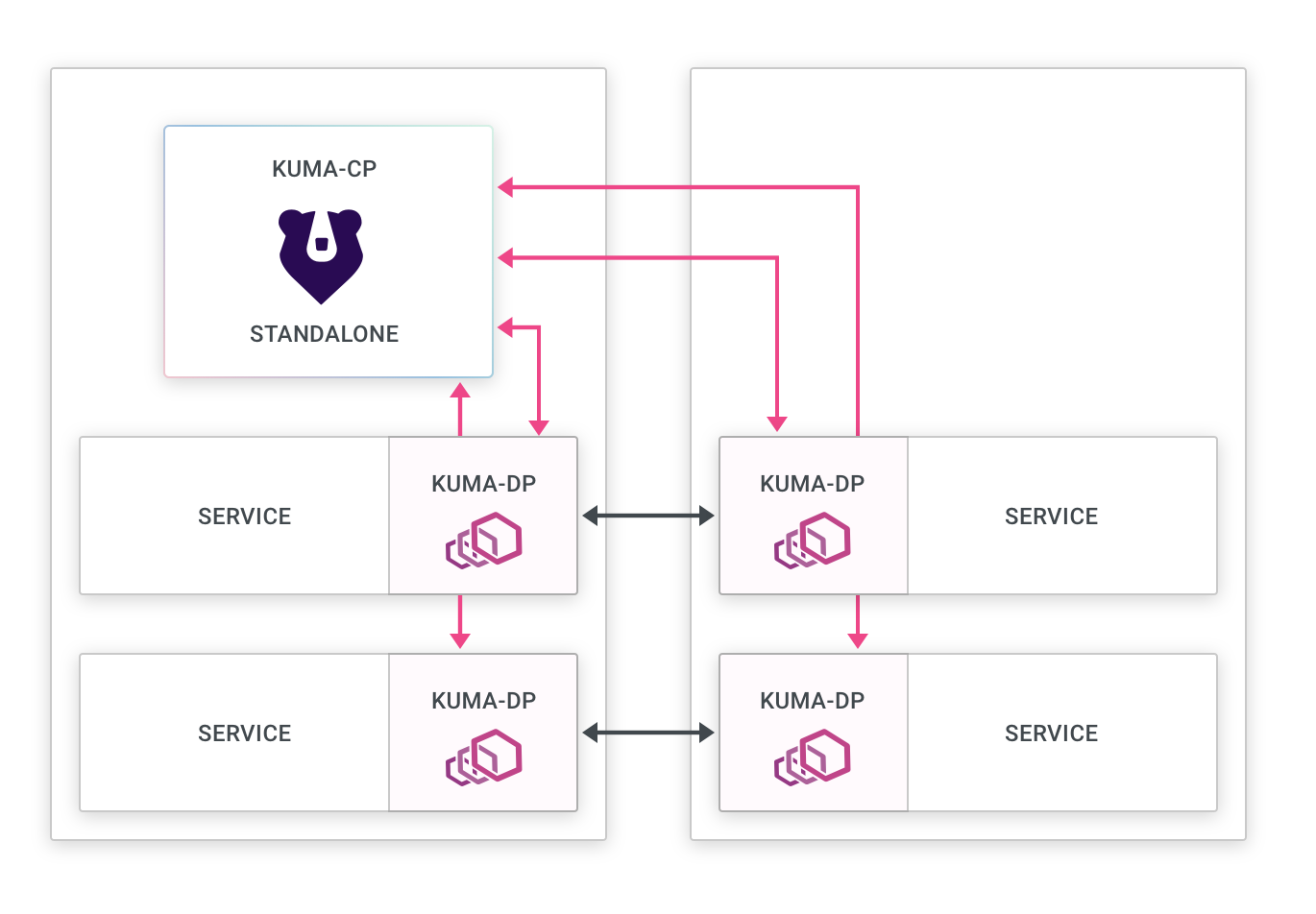
运行机制
在 Kuma 中将服务标记以 kuma.io/service 标签标记,这意味着运行在任何地方的数据平面代理可以通过 kuma.io/service 标签值找到该服务。不同区域上的同一服务用相同的 kuma.io/service 标记,可以在特定区域发生故障时自动进行服务故障转移。
如果一个新的后端服务 serviceA 部署在区域 zone-b,下面看这两个问题。
- 这个新的后端服务如何被通告到 zone-a 区域(区域间的同步)。
- 一个来自于 zone-a 区域的请求如何被路由到 zone-b 区域(区域间的请求路由)。
区域间的信息同步
当 zone-b 区域中加入了一个新的服务 serviceA 后,区域间的信息同步如下:
- zone-b 的控制面将该服务加入到 zone-b Ingress 资源的 availableServices(可用服务列表)中,Ingress 持有可用服务列表,以便可以路由区域外的请求。
- zone-b 的控制平面也会将该区域的 Ingress 资源信息(Ingress 的地址等),同步到 Global 全局控制平面。
- 全局控制平面将通过 Kuma 发现服务(KDS,基于 xDS 的协议)将区域入口 Ingress 资源和所有策略传播到所有其他区域。
区域间的请求路由
当 zone-a 中有请求想请求 serviceA 服务时:
- 首先会进行本地服务和远程服务之间的负载均衡,决定发往本区域服务还是远程区域服务。
- 如果存在区域 Egress,流量会先通过本地区域 zone-a 出口进行路由,然后再发送到远程区域 zone-b 入口。
- 远程区域 zone-b 入口收到请求后,路由到本地服务 ServiceA。
对于负载平衡,是根据其后面运行的实例数量进行加权。因此,具有 2 个实例的区域接收的流量是具有 1 个实例的区域的两倍。可以配置位置感知的负载均衡,来支持本地服务实例。
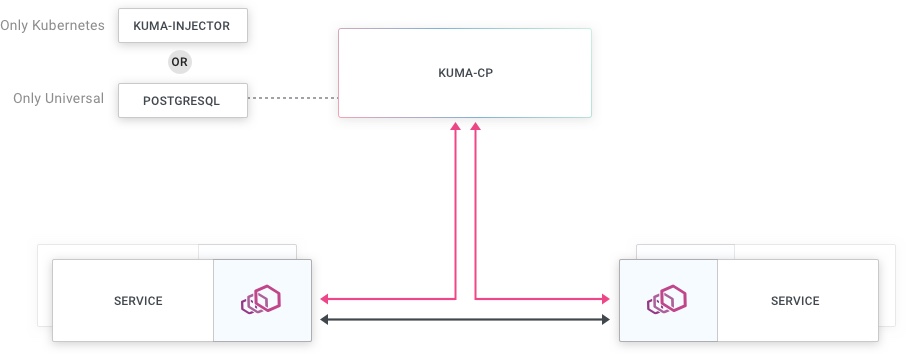
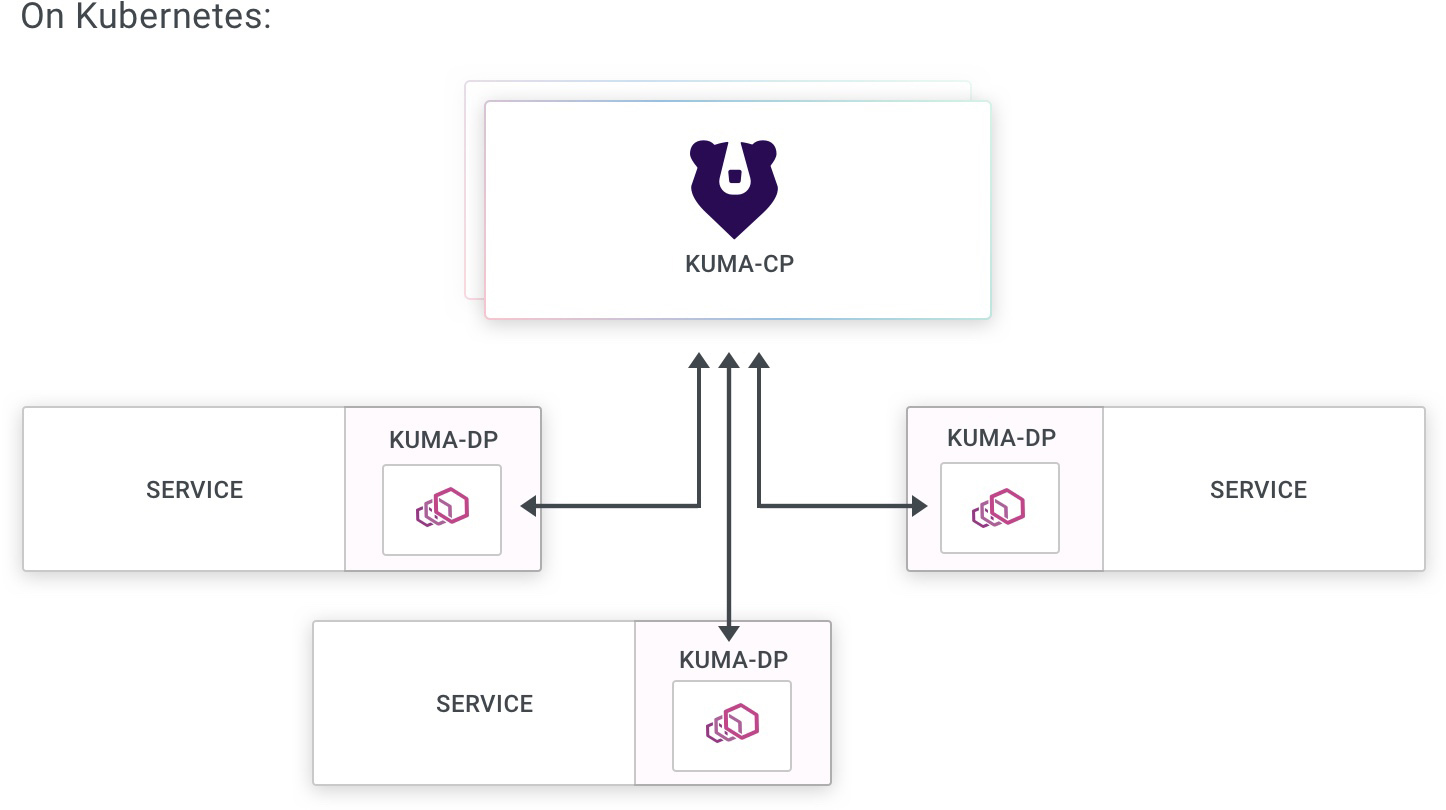
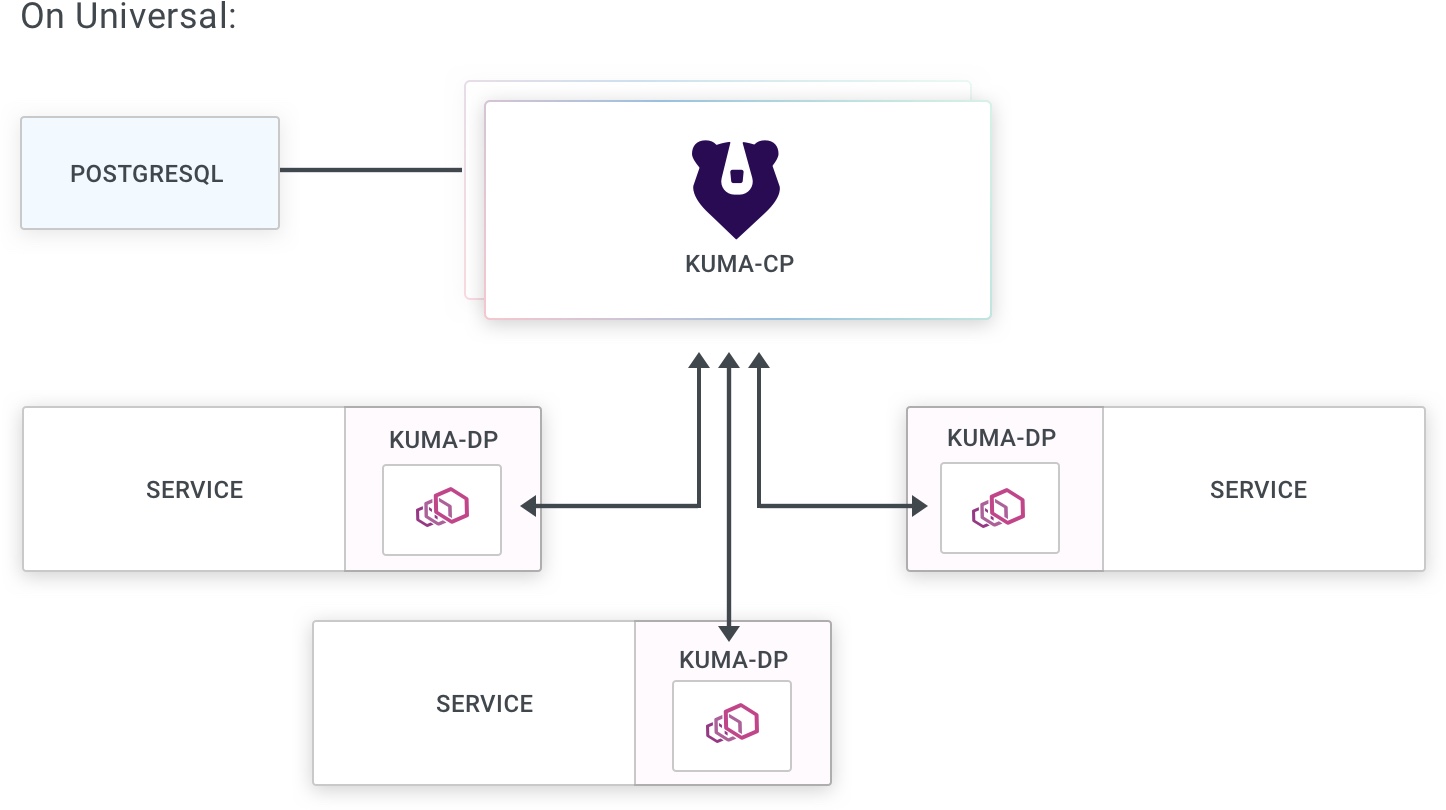
组件
多区域部署包括:
- 全局控制平面(Global kuma-cp):
- 仅接受来自区域控制平面的连接。
- 接受对将应用于数据平面代理的策略的创建和更改。
- 将策略发送到区域控制平面。
- 将区域入口向下发送到区域控制平面。
- 保留所有区域中运行的所有数据平面代理的清单(这样做只是为了可观察性,但对于操作不是必需的)。
- 拒绝来自数据平面代理的连接。
- 区域控制平面(Zone kuma-cp):
- 接受来自该区域内启动的数据平面代理的连接。
- 从全局控制平面接收策略更新。
- 将数据平面代理和区域入口的更改发送到全局控制平面。
- 使用 XDS 计算配置并将其发送到本地数据平面代理。
- 更新区域入口中区域中存在的服务列表。
- 拒绝非来自全球的政策变化。
- 数据平面代理(Envoy):
- 连接到本地区域控制平面。
- 使用 XDS 从本地区域控制平面接收配置。
- 连接到其他本地数据平面代理。
- 连接到区域入口以发送跨区域流量。
- 从本地数据平面代理和本地区域入口接收流量。
- 区域入口(Ingress):
- 从本地区域控制平面接收 XDS 配置。
- 从其他区域数据平面代理到本地数据平面代理的代理流量。
- (可选)区域出口(Egress):
- 从本地区域控制平面接收 XDS 配置。
- 来自本地数据平面代理的代理流量:
- 来自其他区域的区域入口代理;
- 从本地区域到外部服务。
跨区域服务发现和连接
KDS
在多区域部署中,Kuma 提供了几个重要功能:
- 有两种控制平面,global 和 zone 控制面。
- 一种新的 DNS,用于跨集群通信。
- 一种新的 Ingress 数据平面代理,可以在 Kuma service mesh 实现区域之间的连接。
在分布式部署中,global 控制平面将负责接受 Kuma 资源,通过原生 Kubernetes CRD 或基于 VM 的部署中的 YAML 来确定服务网格的行为。
介绍
Global 将负责将这些资源传播到 zone 控制平面。zone 控制平面和 global 控制平面通过 KDS(Kuma Discovery Service)以 gRPC(H2)的方式进行资源的同步。Zone 控制面还会接收来自于数据面的请求,zone 控制面和其下的所有控制平面代理属于同一区域。
Zone 控制平面还嵌入一个 DNS 服务发现,可用于跨不同区域的服务。
分层的好处
global 和 zone 架构有几个好处:
- 可以通过拓展 zone 控制平面来独立拓展每个区域,并且在某个区域出现问题的时候实现 HA 故障转移。
- 没有单点故障。即使 global 控制平面发生故障,仍然可以在 zone 控制平面上创建和销毁数据平面代理,并且每个服务的最新地址仍然可以传播到 sidecar 中。
- global 控制平面自动传播每个区域的状态,同时确保“远程”控制平面了解每个区域的Kuma Ingress,以实现跨区域连接。