论文
End-to-End Relation Extraction using LSTMs on Sequences and Tree
发布年份:2016
会议:ACL
作者:Mokoto Miwa, Mohit Bansal
机构:Toyota Technological Institute
贡献:
- 这是深度学习联合(Joint)模型的开篇之作。
- 在训练种加入两个功能,这些功能缓解了训练早期阶段实体检测性能低的问题,并允许实体信息进一步帮助下游关系分类任务。
- 实体预训练 entity pretraining:预训练实体检测模型。
- 预定抽样 scheduled sampling:在一定概率的情况下用 gold labels 来代替预测的实体标签。
数据集:ACE05 和 ACE04 用于关系提取;SemEval-2010 Task 8 用于关系分类。用 ACE05 和 ACE04 去训练整个模型,用 SemEval-2010 Task 8 去评估关系分类模块。
传统的关系抽取将该任务看作是有两个子任务的 pipeline,两个子任务依次是命名实体识别(NER)和关系分类。
- pipeline 型的关系抽取的两个子模块非常灵活,并且是可以替换的。
- 但是其缺点在于忽略了 NER 与关系分类之间的依赖关系,研究表明 NER 的效果极大程度上的影响了关系分类的效果。除此之外,还会受到错误传播的影响。
端到端的模型(End-to-End,Joint)不同于 pipeline 任务,将两个子任务合并,同时输出实体和其关系。
- joint 的优点在于它通常比 pipeline 的表现更好,因为实体和关系之间存在依赖关系。
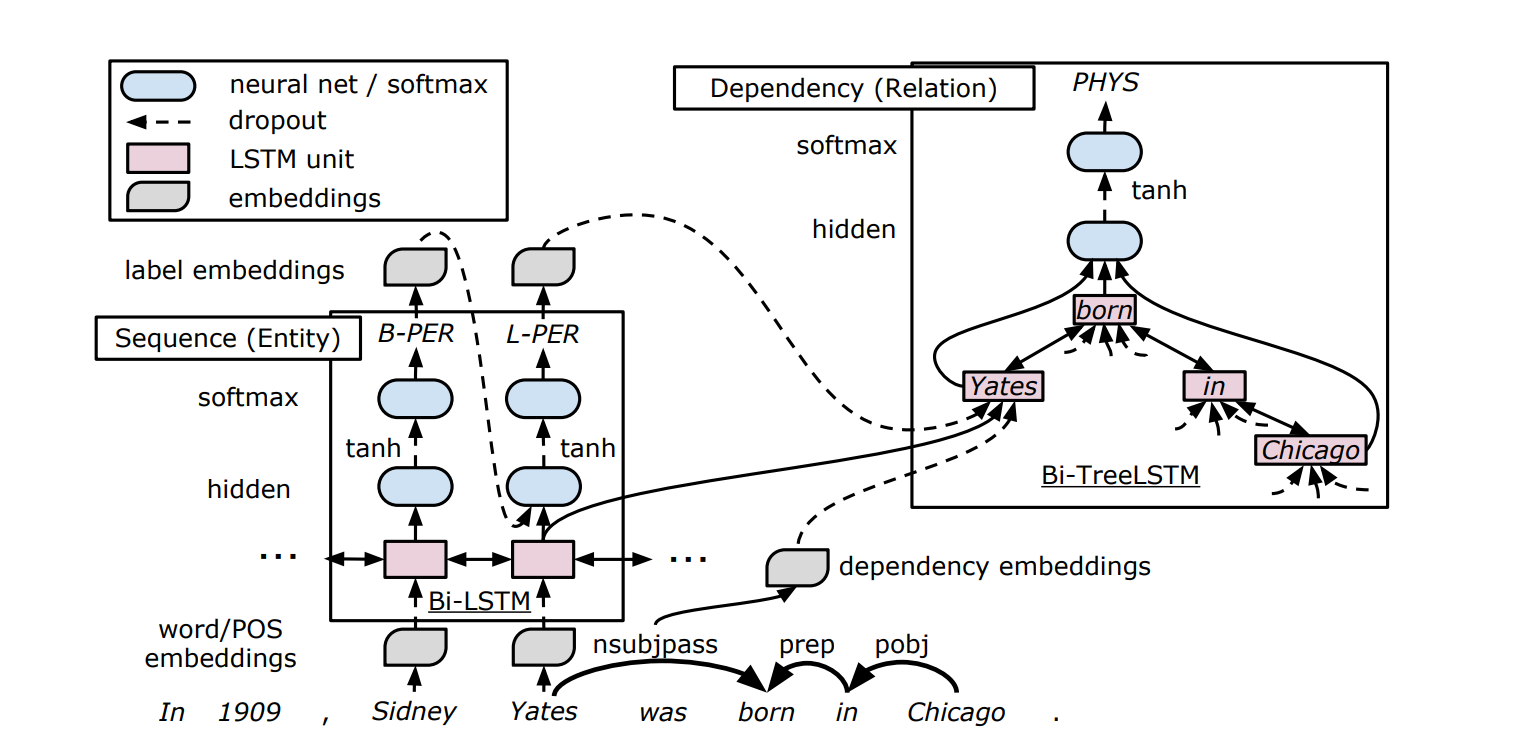
模型结构
模型主要分为以下几个部分:
- Sequence Layer:作为 Entity Detection 的低层结构,与 Entity Detection 共享 BiLSTM 的参数。
- Entity Detection:实体检测,产生 entity embedding。
- Dependency Layer:树型 BiLSTM 结构,用于产生 Relation Classification 的输入。
- Relation Classification:关系分类。