语音识别介绍
语言识别包括输入(一段语音,长度为 T,d 维向量)、语音识别模型、输出(一段文字,长度为 N,有 V 个不同的 token):
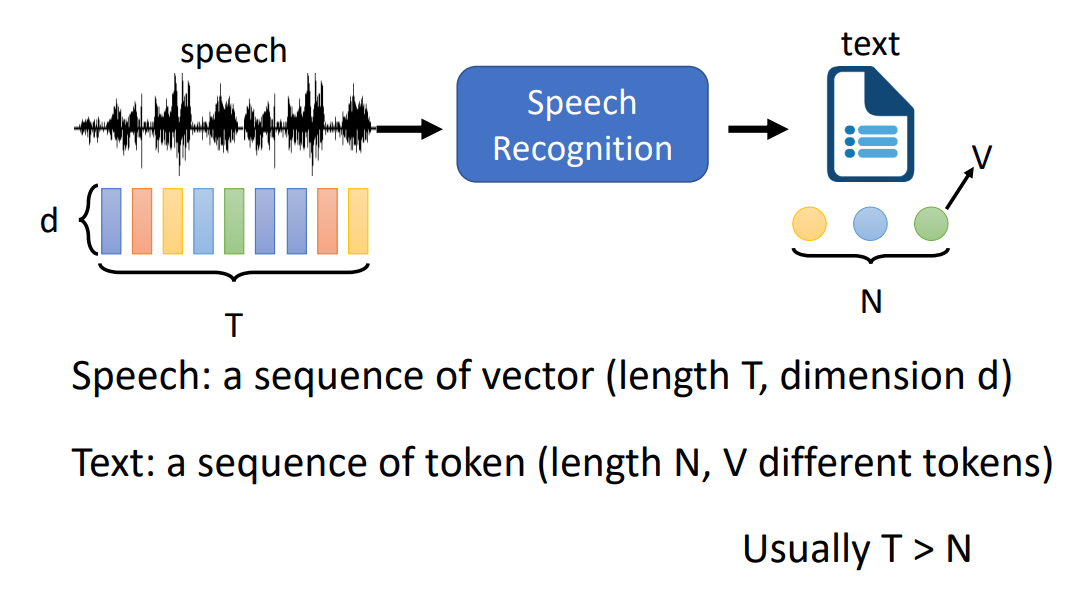
token
下面介绍不同种的 token:
Phoneme:最小的语音单元,比如音标、拼音。缺点是需要一个词典,来对应单词与 phonemes 的关系。
Grapheme:最小的书写单元,比如 26 个英文字母 + 标点 + 空格、汉字 + 标点。
Word:单词,对于一些语言而言单词太多了(V 很长)。
Morpheme:最小的有意义的单元,如英文中的前后缀以及中心词。
Bytes:字节,如 UTF-8 中的每一个字节。好处是可以不依赖于具体的语言,不同语言的文字都可以用 UTF-8 表示。
输入
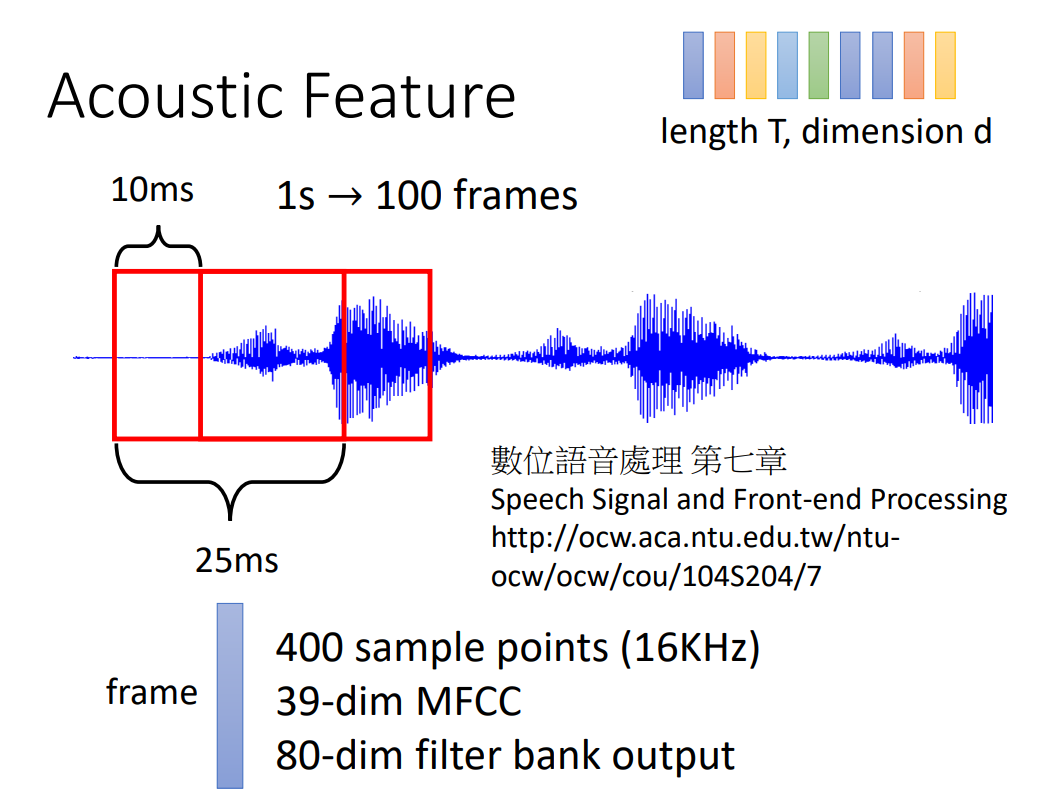
语言识别的输入是长度为 T,维度为 d 的向量。如何将语言信号转换为向量,一般取 25ms 为一个 窗口,窗口每次向后移动 10ms,每一次窗口内的语音信号对应一列向量。
关于如何将一个窗口内的语音信号转换为向量,一般有如下方法:
- 400 次采样:每一个窗口采样 400 次,将 400 次采样结果直接进行拼接,形成一列向量。
- MFCC:形成 39 维的向量。
- Filter Bank Output:形成 80 维的向量(最为常用)。
下面说明以下几种模型:
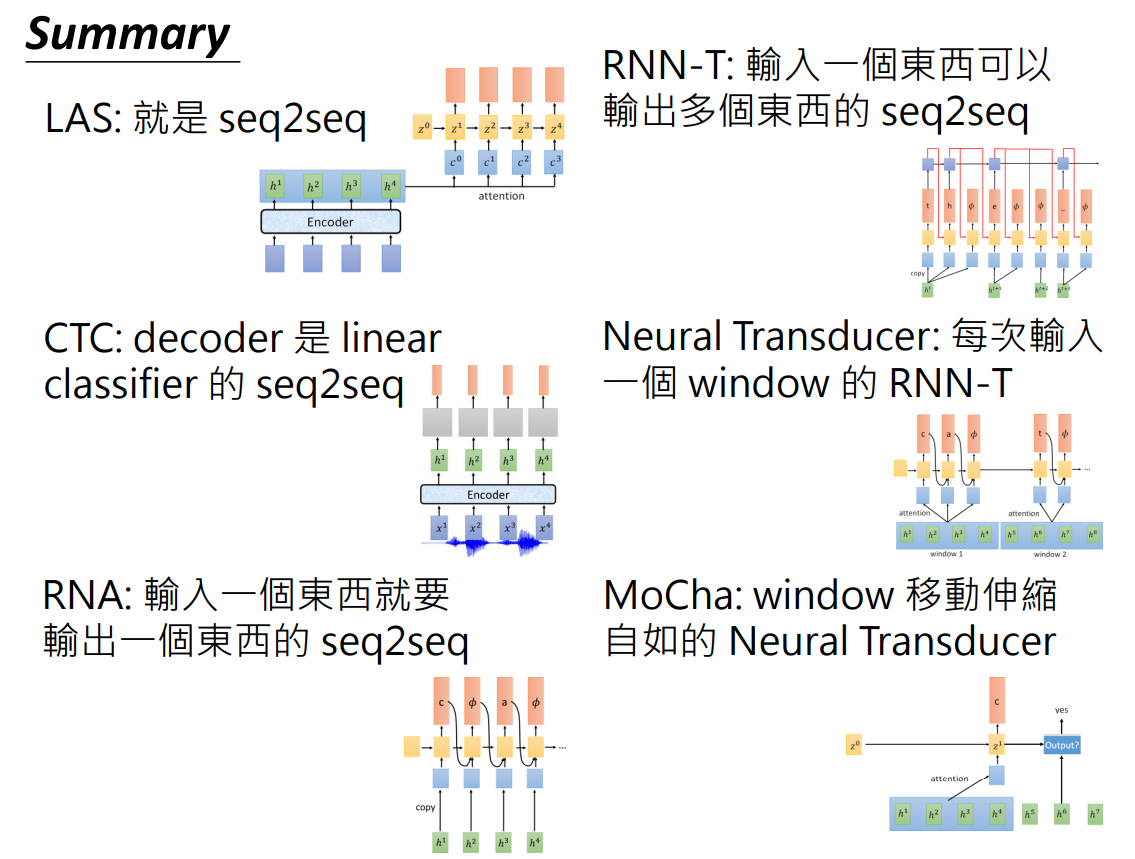
- Listen,Attend and Spell(LAS)
- Connectionist Temporal Classification(CTC)
- RNN Transducer(RNN-T)
- Neural Transducer
- Monotonic Chunkwise Attention(MoChA)
LAS
Listen,Attend and Spell
Listen
Listen的输入为语音特征(acoustic features),经过 Encoder 后输出一组高级表示法的向量:
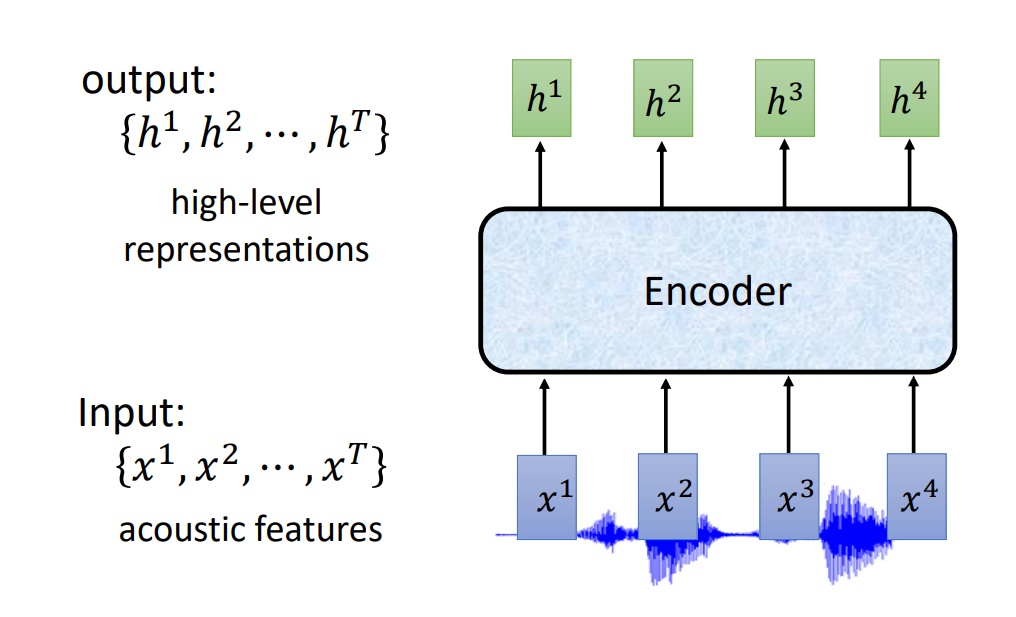
Encoder
其中,Encoder 可以是:
- RNN
- CNN(RNN+CNN 的组合更为常见)
- Self-Attention Layers
Down Sampling
输入太长导致运算量很大,需要 Down Sampling:
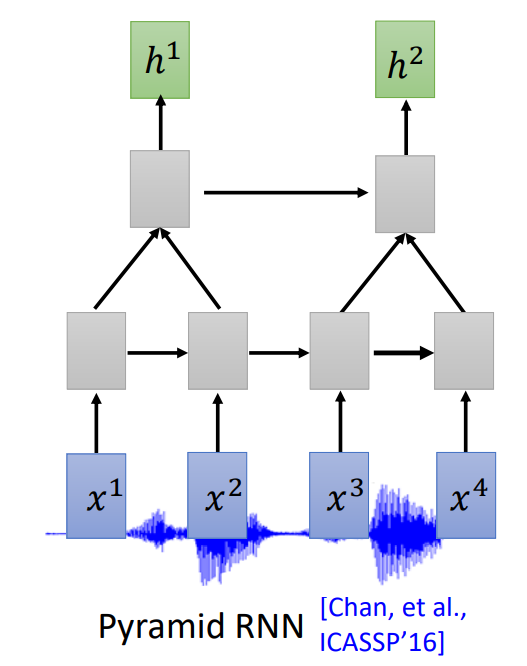
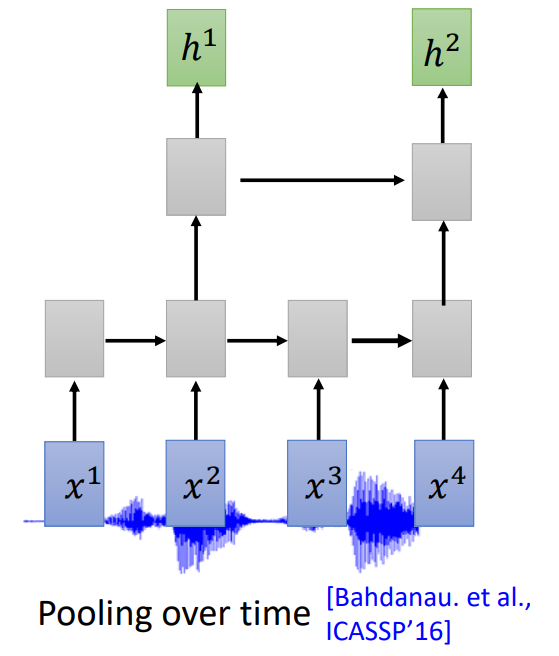
- Time-delay DNN(TDNN)或者 Dilated CNN:只考虑第一个和最后一个向量。
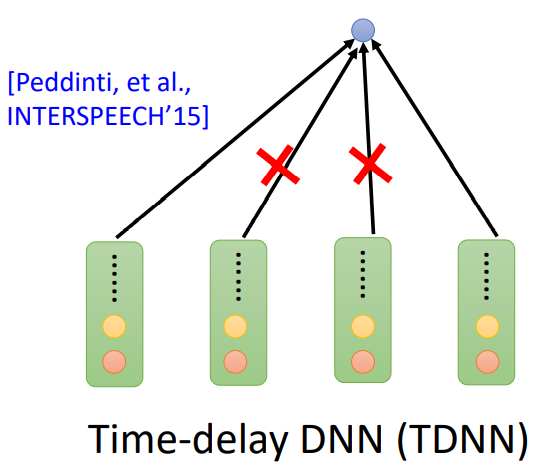
- Truncated Self-Attention:在一定范围内 Attention,超出范围不予考虑。
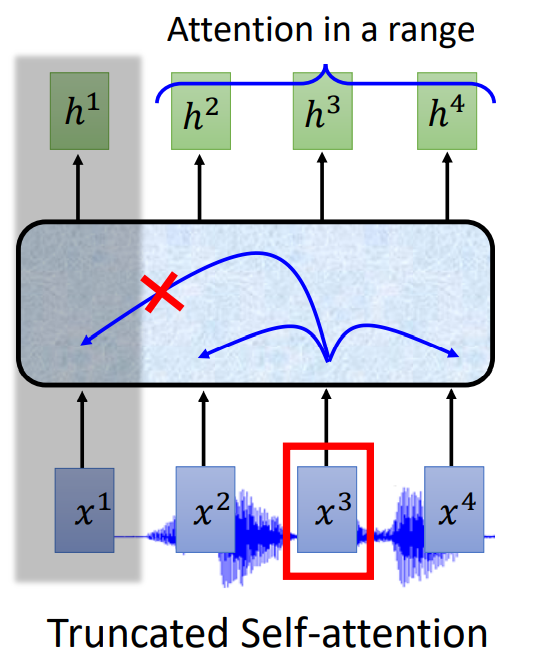
Attention
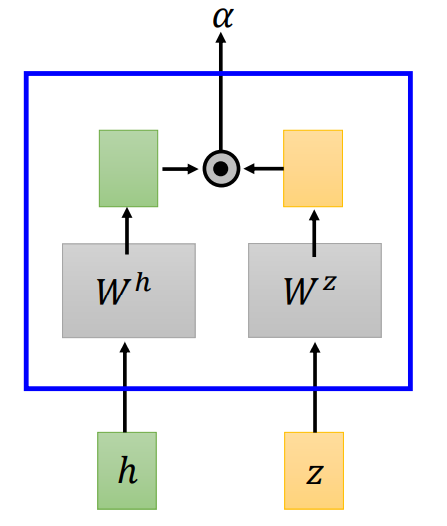
Attention 首先会进入 match 函数,match 以 Encoder 的输出 h 向量 和 z 作为输入,输出为向量 α。
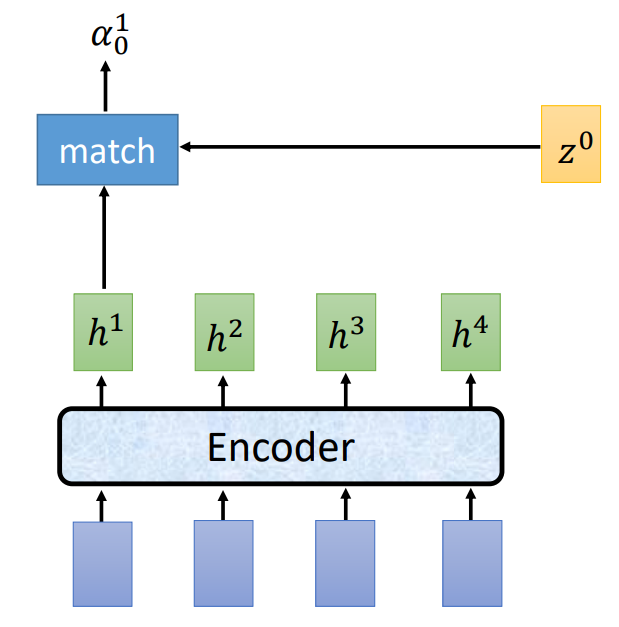
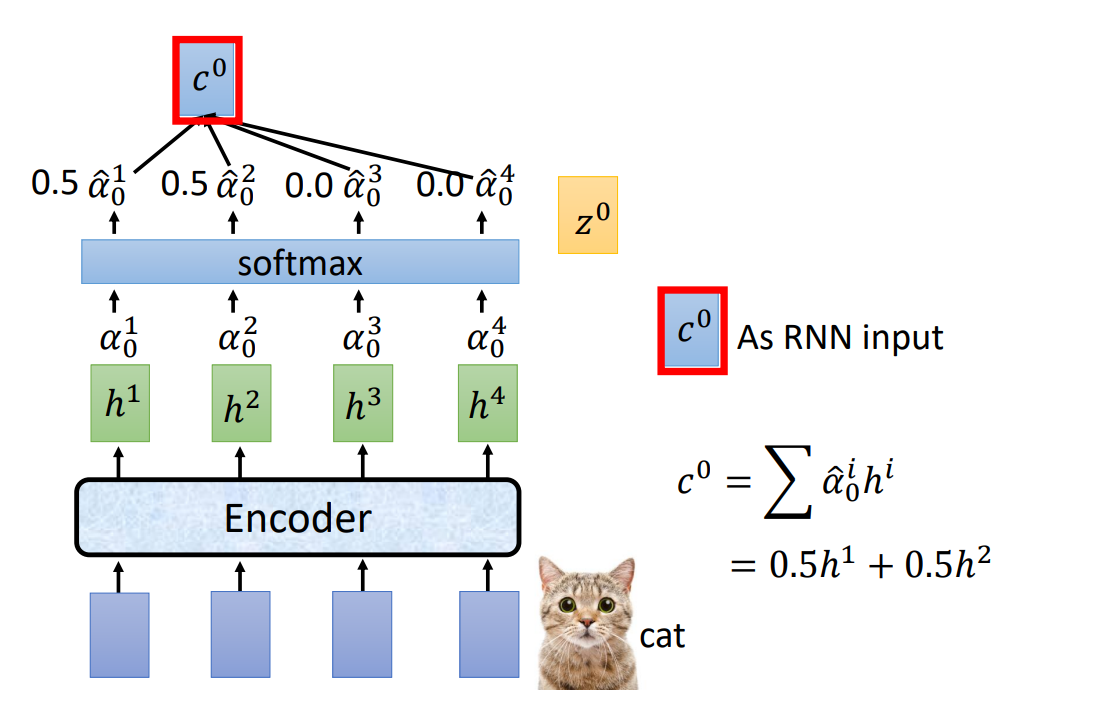
接着 α 进入 softmax 层,最后得到 c(Attend 的输出),作为 Spell(也就是 RNN)的输入。
match
match 函数是可以替换的,如:
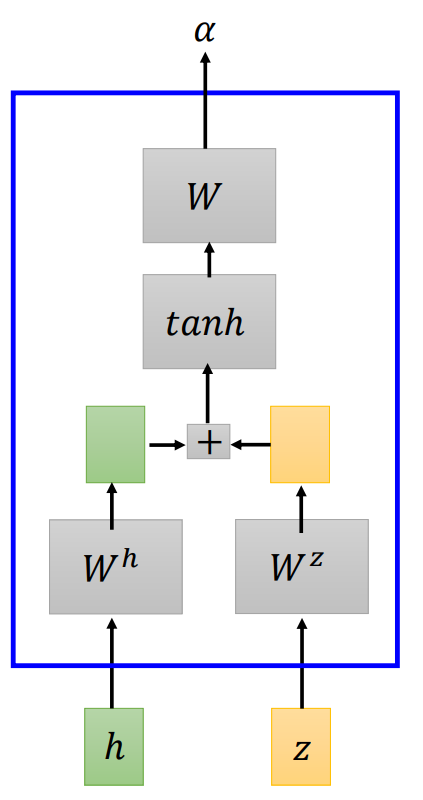
Spell
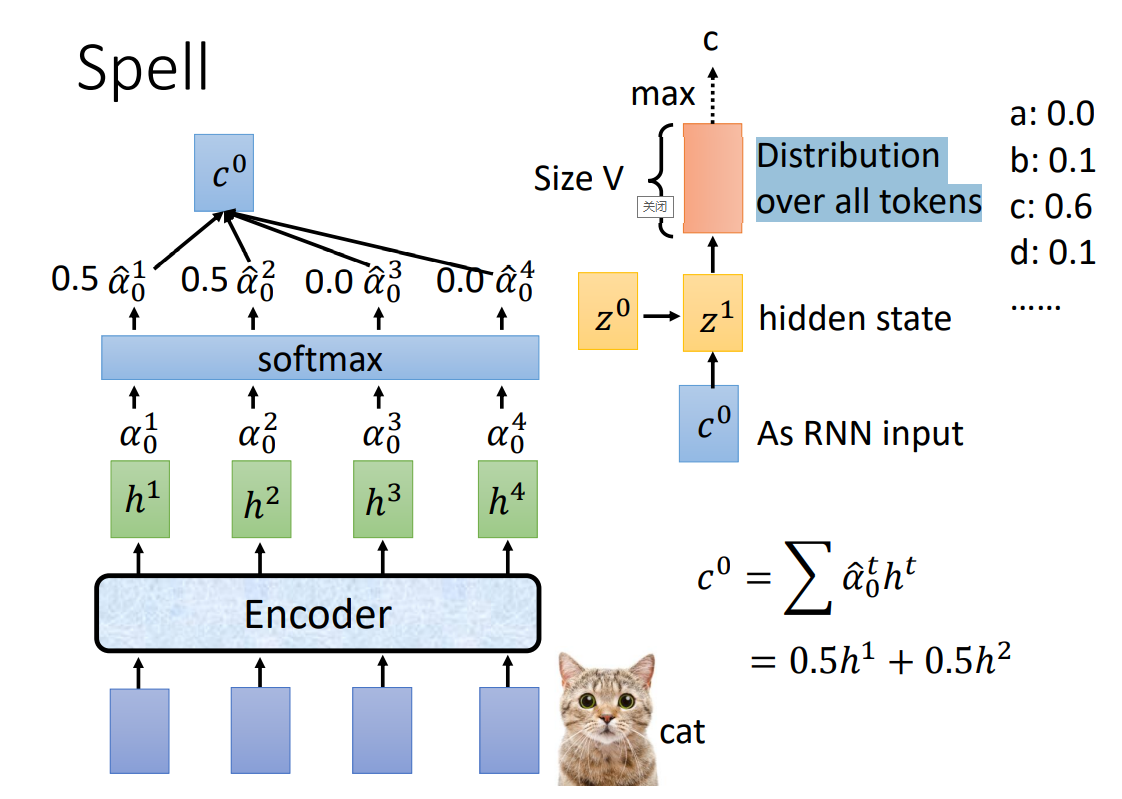
c0 作为 Spell 的输入,得到各个 token 的概率,取最大的作为输出:
z1 作为 match 的输入,得到 c1,c1 再作为 Spell 的输入;以此类推,得到语音识别的 token 序列:
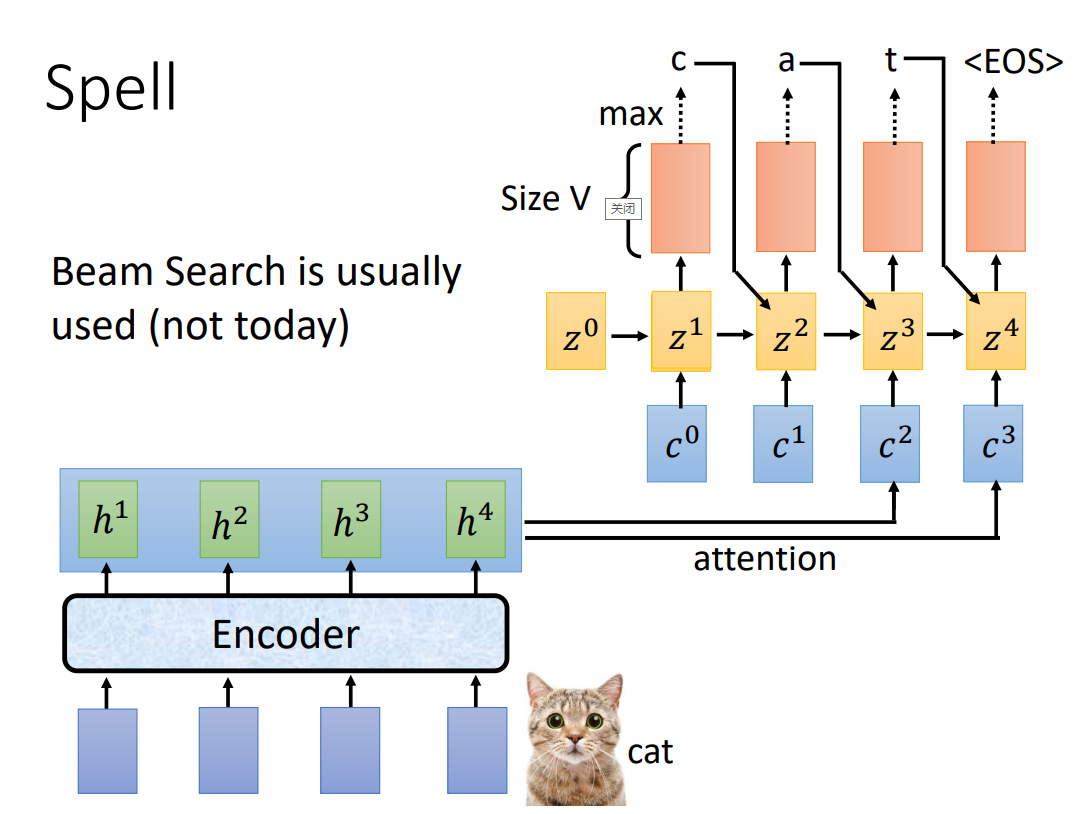
Beam Search
最后选择 token 时,都是选择概率最大的,也就是贪心的选择当前概率最大的 token。但是贪心的选择,有可能进入局部最优,而不是全局最优。
Beam Search 要求每次选择 B(Beam Size)个概率最大的token,显然这会增加运算量,但是更容易得到全局最优。
LAS 在训练时需要强制学习(忽略学习出的结果,而是使用正确结果)。
LAS 无法在线输出语音识别结果,必须一句话说完之后再输出结果。
CTC
Connectionist Temporal Classification,CTC
结构
CTC 结构比较简单,只有一个 Encoder(如果使用 RNN,必须是单向 RNN,因为 CTC 可以在线输出语音识别),Decoder 部分是一个线性分类(softmax)。
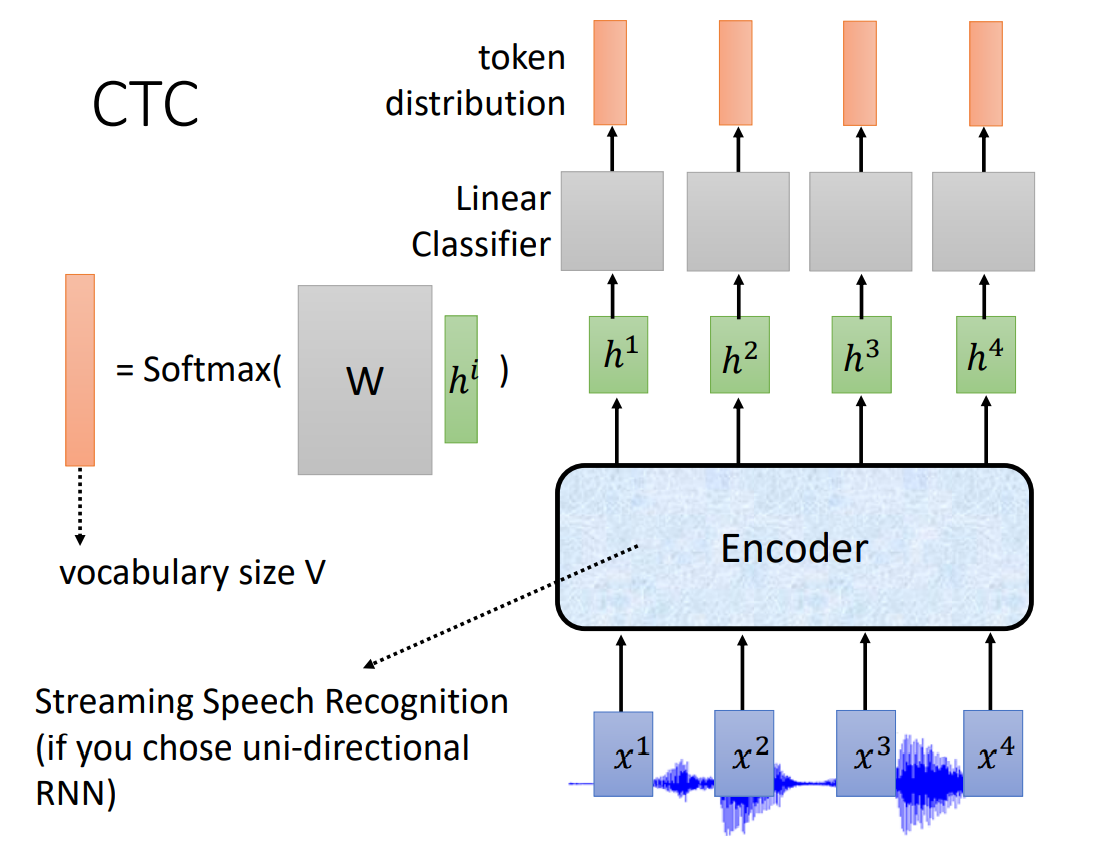
CTC (在没有 down sampling 的情况下)有 T 个语音特征输入,就会有 T 个输出。
但是多个语音特征可能对应一个 token,所以输出包括了 Ø,表示什么也不输出。最终合并相邻并且相同的 token,忽略 Ø。
训练
在训练时,比如一段语音有四个输入,标签是 你好。因为引入了 Ø,所以对应了以下输出:
你你好好、Ø你Ø好、你你Ø好 ……
那么到底需要选择哪一个作为训练的正确标签呢?CTC 在训练时,选择将这些全部考虑(穷举)在内。
RNN-T
RNN Transducer,RNN-T
RNA – CTC 到 RNN-T 之间的过渡
RNA,Recurrent Neural Aligner,就是将 CTC 中线性选择器的部分替换为 LSTM(RNN),使当前输出考虑前面的输出。
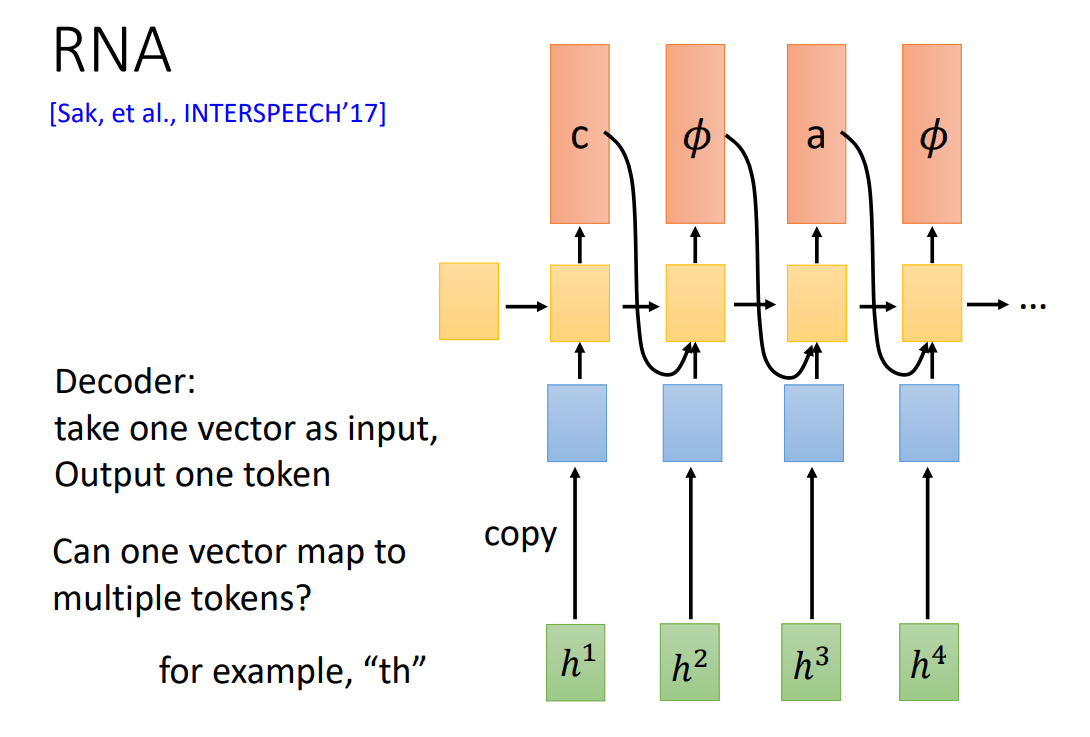
RNN-T 结构
对于 RNA 而言,有可能一个输入对应多个 token,如 th。此时需要引入 RNN-T。
RNN-T 会重复输入,直到输出了 Ø(表示可以输入下一个语音特征)。
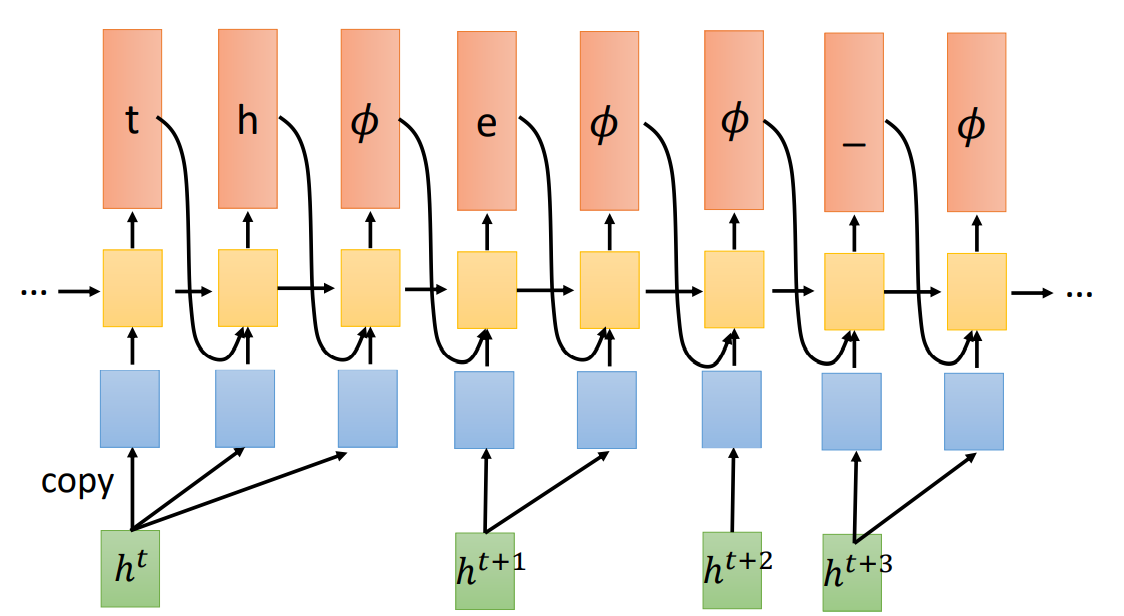
特别之处
因为输出依然包括了 Ø,所以需要自定义标签的生成,依然可以选择与 CTC 一样的处理方式,即选择所有可能的标签。
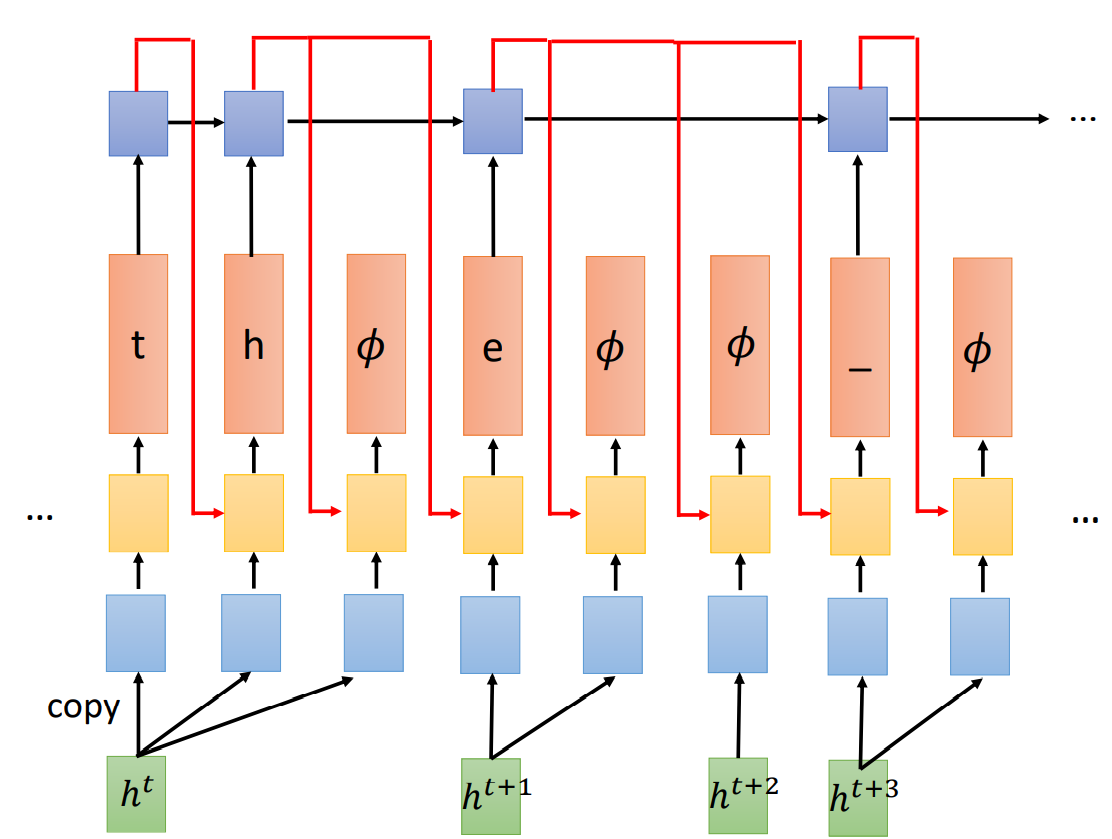
但是,RNN-T 有自己的特别之处,在输出 token 后,将 token 送入另一个 RNN 中,并且这个 RNN 会忽略 Ø 的输出。
这样做的好处是,这个 RNN 网络只看前面产生的非空 token,至于中见有没有 Ø、Ø的顺序,并不关心这个问题。
Neural Transducer
结构
Neural Tansducer 与之前 RNN-T 的不同之处在于:一次性读入多个声音特征作为一个 chunk,先做 Attention。
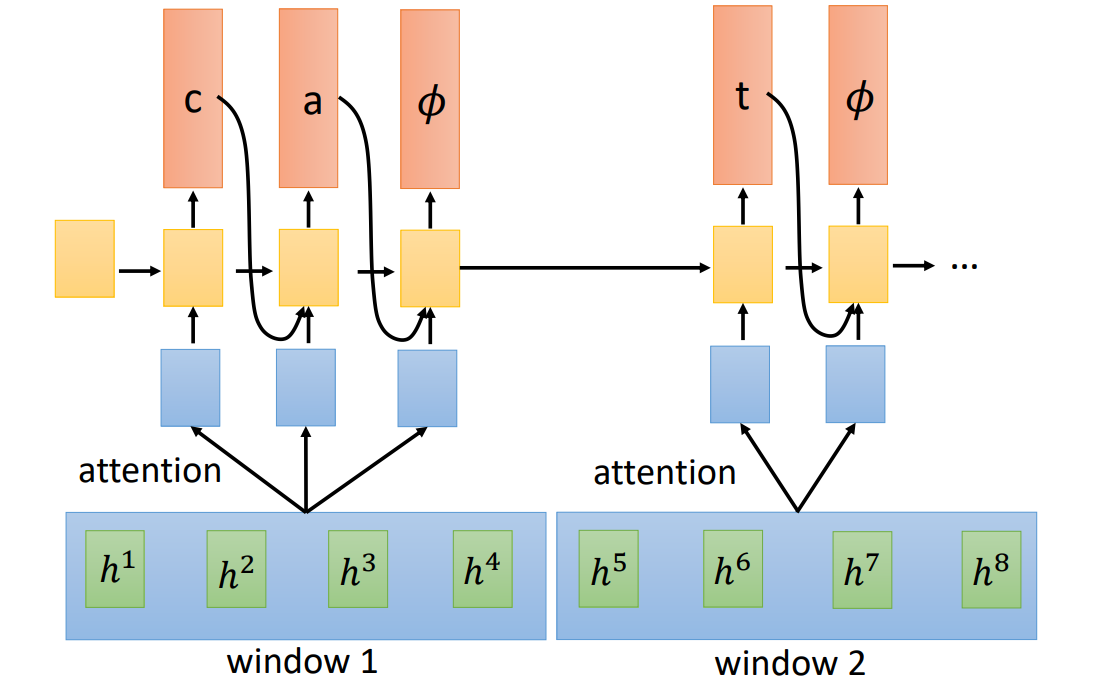
MoChA
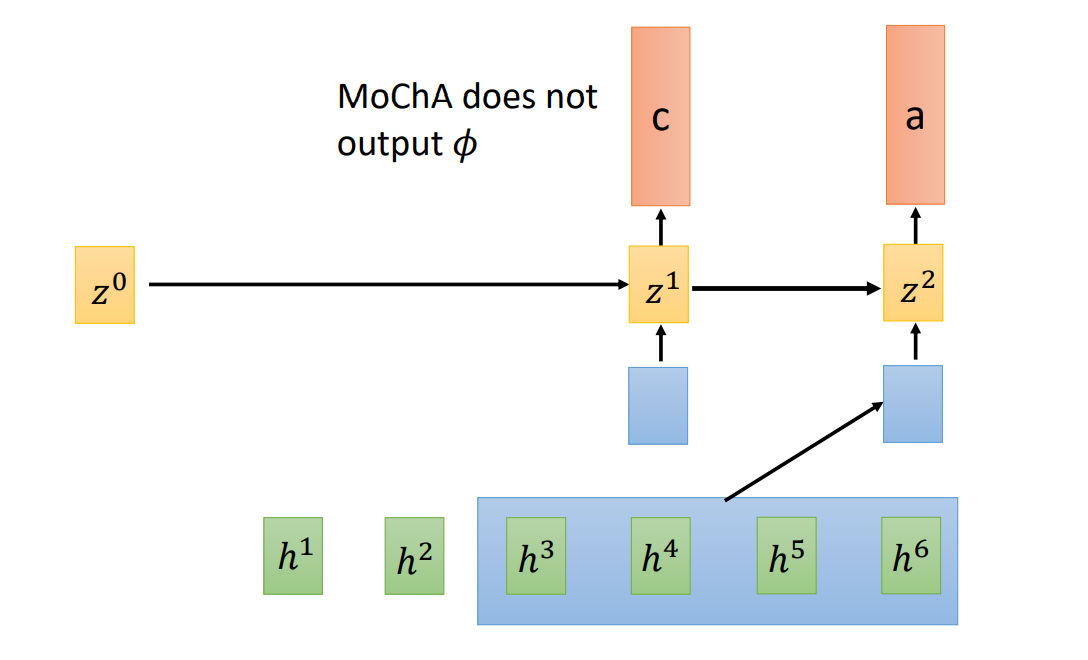
Monotonic Chunkwise Attention,MoChA
结构
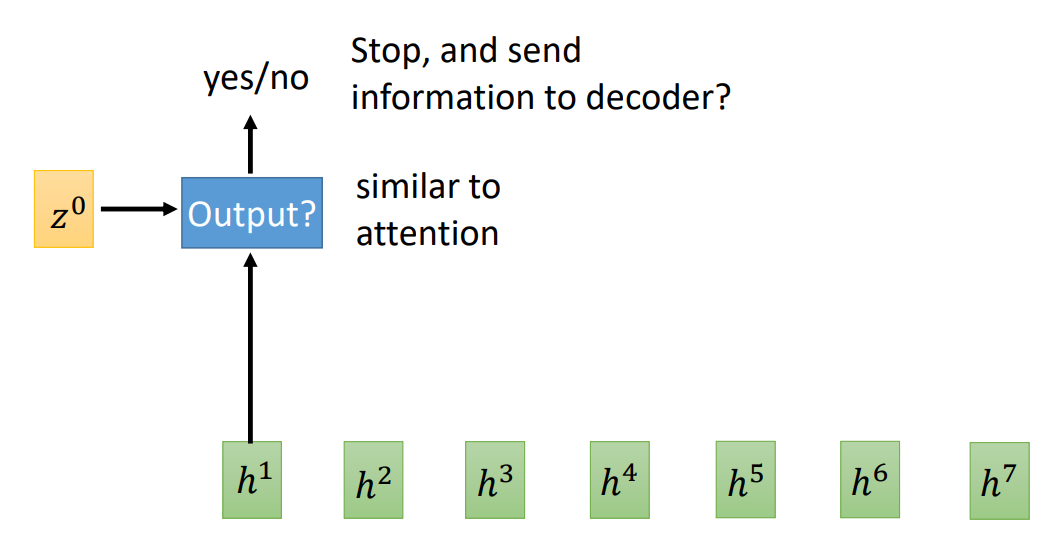
MoChA 可以自己决定 chunk 的大小:
总结